- @Study996
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
AgenticAI是一种通过分解任务步骤来提升AI性能的工作方法。它将复杂任务拆分为规划、研究、起草、修订等可管理环节,通过LLM与工具API的协同工作,产生比单一提示更优质的输出。典型应用包括研究代理、发票处理和客户服务等场景。系统自主性可分为低、中、高三个等级,采用反思、工具使用、规划和多代理协作等设计模式。相比传统LLM,AgenticAI具有性能提升显著、支持并行处理和模块化组件等优势,但

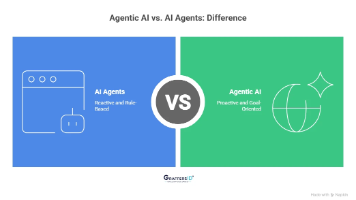
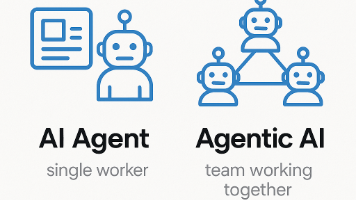
企业AI应用的两大路径:AIAgent聚焦结构化任务执行,通过预设规则完成特定工作;AgenticAI则具备战略思维,能自主决策、持续学习并协调多系统协同。二者差异体现在自主性、决策逻辑等8个维度。企业应根据业务复杂度选择:结构化、短期ROI需求适合AIAgent;跨部门协作、战略决策等复杂场景则需AgenticAI。领先企业正采用"执行+统筹"的混合模式,实现从自动化到智能化
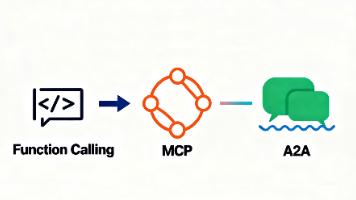
摘要:文章探讨了从单纯大语言模型向AIAgent的进化,重点解析了三大关键技术:MCP协议实现工具发现与调用、FunctionCalling机制使模型学会使用工具、A2A协议支持多Agent协作。通过天气查询案例,展示了MCP协议的工作流程,并分析了600行系统提示词如何指导模型完成复杂任务。文章指出Agent本质是精心设计的上下文工程,通过控制上下文长度、结构化信息等方式克服传统自动化的局限,使
本文探讨了从通用AI模型向专业领域AI模型的发展趋势,特别聚焦设计领域。文章分析了隐性知识在设计中的重要性及其特征(隐含性、情境特定性等),提出了通过定性研究和AI交互记录法提取隐性知识的方法。重点阐述了如何将设计师行为转化为知识向量,并构建能够理解设计意图、生成连贯行动序列的智能体。文章还讨论了模型训练策略(LoRA、RLHF等)及当前面临的挑战,如知识提取完整性和智能体泛化能力。最后指出,通过

2022 年底,ChatGPT震撼上线,大语言模型技术迅速“席卷”了整个社会,人工智能技术因此迎来了一次重要进展。面对大语言模型的强大性能,我们不禁要问:支撑这些模型的背后技术究竟是什么?这一问题无疑成为了众多科研人员的思考焦点。必须指出的是,大模型技术并不是一蹴而就,其发展历程中先后经历了统计语言模型、神经网络语言模型、预训练语言模型等多个发展阶段,每一步的发展都凝结了众多科研工作者的心血与成果

AI Agent作为新一代智能实体,凭借感知、规划、行动和记忆四大核心能力,正在从辅助工具进化为能独立完成复杂任务的数字员工。不同于传统AI系统,AI Agent通过整合大模型与外部工具,实现从思维到行动的闭环,在商业调研、电力运维、医疗诊断等领域展现出显著价值。尽管面临大模型不确定性、多Agent协作机制不成熟等挑战,但其在金融、制造等垂直行业的深度应用已初见成效。
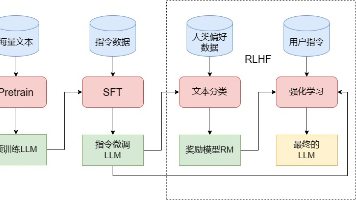
本文系统介绍了大语言模型(LLM)的定义、特点、能力及训练方法。LLM与传统预训练模型的核心差异在于其庞大的参数量(十亿至千亿级)和海量训练数据,使其具备涌现能力、上下文学习、指令遵循和逐步推理等独特优势。文章详细阐述了LLM的三阶段训练流程:预训练(Pretrain)构建基础能力,监督微调(SFT)培养指令遵循能力,以及人类反馈强化学习(RLHF)实现价值观对齐。同时分析了训练过程中的关键技术挑
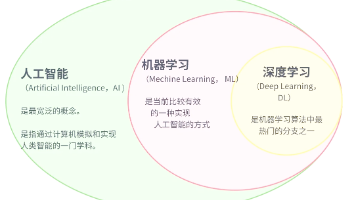
本文系统介绍了人工智能的核心算法体系,涵盖机器学习、深度学习、强化学习和生成式AI等关键技术。机器学习分为监督学习、无监督学习和半监督学习,包括线性回归、决策树、K均值等经典算法。深度学习重点解析了CNN、RNN和Transformer架构的特点与应用。强化学习通过AlphaGo等案例展示了决策优化能力,生成式AI则介绍了GAN、扩散模型和大语言模型等创新技术。文章还探讨了多模态学习、集成学习等前
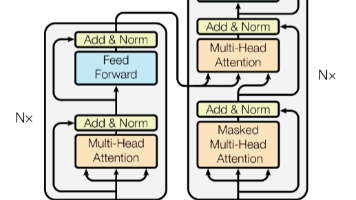
本文系统介绍了神经网络与Transformer的工作原理及其训练过程。首先解释了神经元的基本概念和人工神经网络的结构,通过买肉案例形象说明神经元计算过程。然后详细阐述了神经网络的训练机制、循环神经网络(RNN)的特点及其局限性。重点解析了Transformer的核心模块——多头自注意力机制,通过圆桌会议的比喻生动说明了其工作原理。文章还完整介绍了大语言模型训练的四个关键阶段:预训练、监督微调、奖励
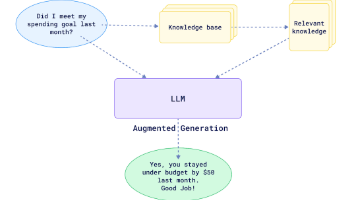
摘要:本文介绍了10个GitHub上热门的开源检索增强生成(RAG)框架,包括Haystack、RAGFlow、txtai等,分析了它们的特点和应用场景。RAG技术通过整合外部知识源增强大语言模型能力,能提供更准确及时的响应。文章对比了RAG与LangChain的区别,强调RAG在定制化、准确性方面的优势,并详细梳理了各框架的核心功能、适用场景和优缺点,为开发者选择合适框架提供参考。