




- @Solo95
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
来自吴恩达深度学习系列视频:卷积神经网络第四周作业2: Art Generation with Neural Style Transfer - v1。如果英文阅读对你来说有障碍,可以参考中英】【吴恩达课后编程作业】Course 4 -卷积神经网络 - 第四周作业。参照对代码的注释并不完全正确,该作业中有一个很难发现的错误,我在下面注明了。预训练模型你可以在原论文官网 MatConvNet....
本文转载自JayLou娄杰,知乎专栏《高能NLP》作者,已与原作者取得联系,已获授权。原文地址:https://zhuanlan.zhihu.com/p/76912493https://zhuanlan.zhihu.com/p/115014536本文以QA形式总结对比了nlp中的预训练语言模型,主要包括3大方面、涉及到的模型有:单向特征表示的自回归预训练语言模型,统称为单向模型:ELMO/ULMF
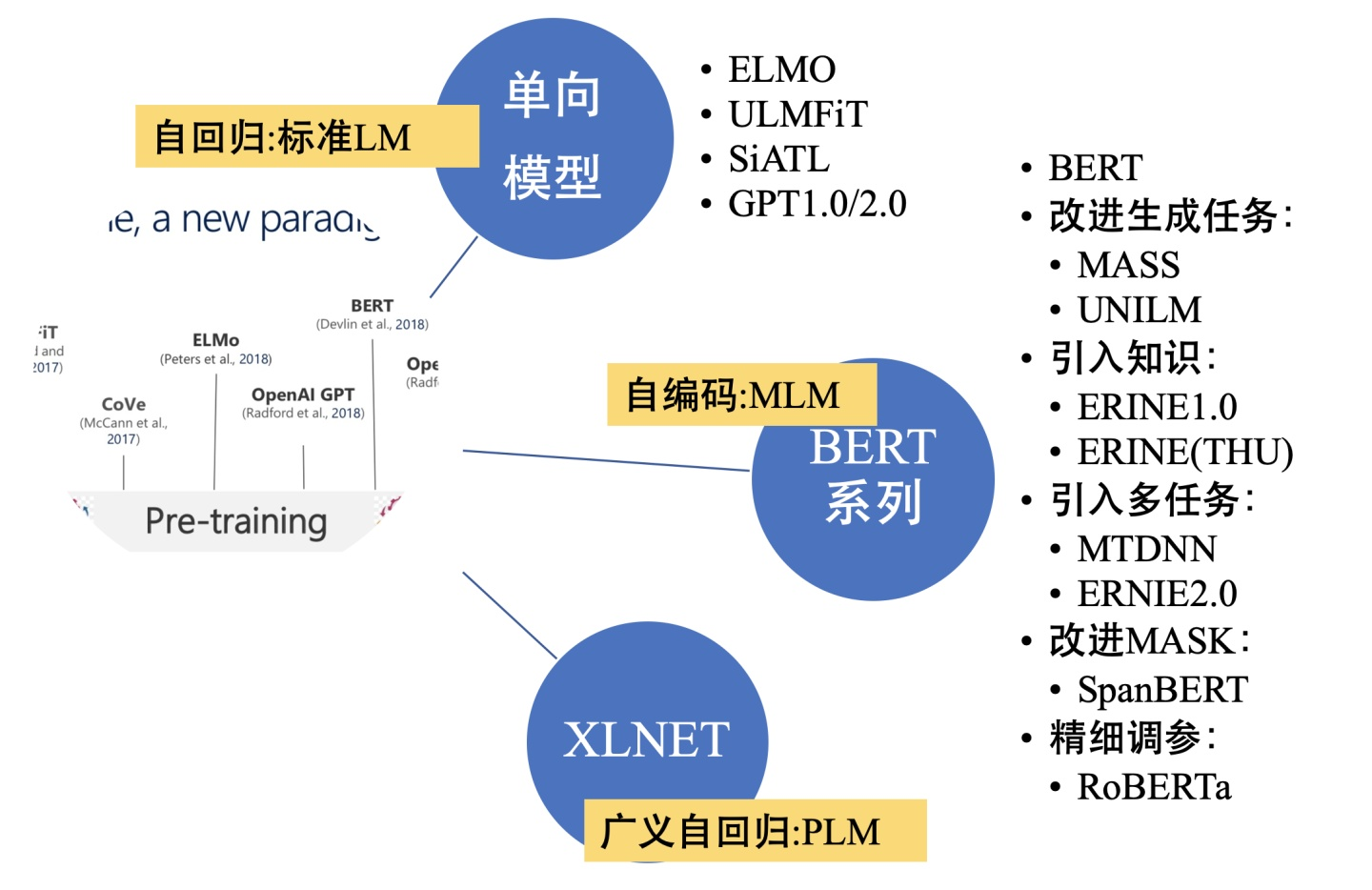
1. 概率语言模型设计用于计算一个句话在自然语言中出现的概率2. 语言建模(即训练语言模型的过程):给定n个单词,预测第n+1个单词是什么。神经网络语言模型使用神经网络进行语言建模。3. 神经网络语言模型随着自然语言处理领域不断提出新的网络架构逐步演进,transformer是其中一个标志性里程碑。基于transformer,Google和Open AI分别提出了BERT和GPT 1.0/2.0.
在计算激活值和梯度的时候以fp16精度存储,执行优化算法的时候还原为fp32(缺失位补0),这样最终的效果是模型在GPU上以fp16和fp32两种方式加载,这被称为混合精度训练(mixed precision training)
前向传播过程中计算节点的激活值并保存,计算下一个节点完成后丢弃中间节点的激活值,反向传播时如果有保存下来的梯度就直接使用,如果没有就使用保存下来的前一个节点的梯度重新计算当前节点的梯度再使用。
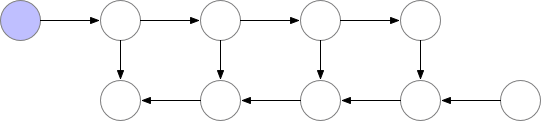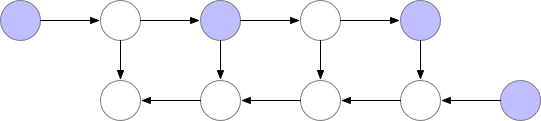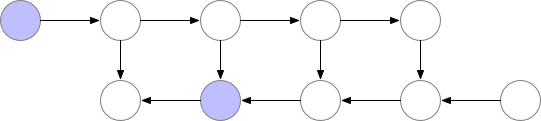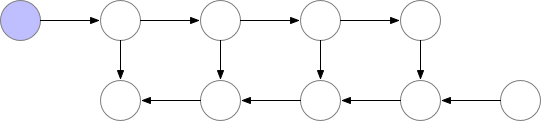
梯度累积(Gradient Accumulation)的基本思想是将一次性的整批参数更新的梯度计算变为以一小步一小步的方式进行
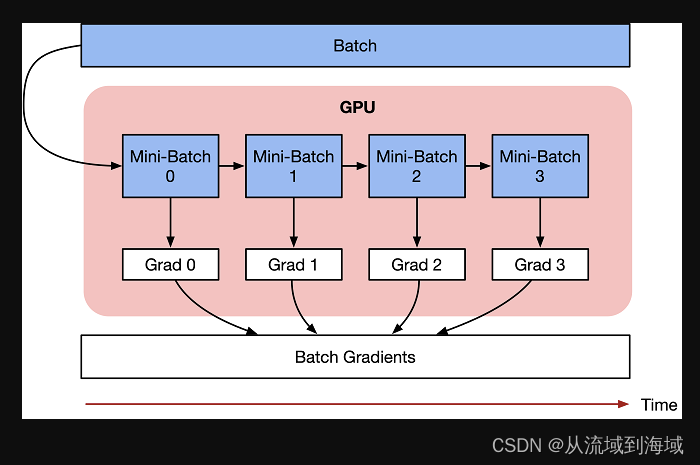
本文介绍了DeepSeek的三样核心贡献,从原理到意义说明了DeepSeek如何重塑AI格局。

AI时代,大模型对知识创作的冲击从Python开始的博客之路AI从不生产内容,AI只是内容的搬运工 / 复读机粗浅内容将被大模型替代,我们需要更有深度的内容劣质内容将被大模型替代,我们需要更多优质的内容乐观看待变化
Adam Optimization Algorithm.Adam refer to Adaptive Moment estimation.要看懂这篇博文,你需要先看懂:指数加权平均使用动量的梯度下降法RMSprop整理并翻译自吴恩达深度学习系列视频:https://mooc.study.163.com/learn/2001281003?tid=2001391036#/learn...
在计算激活值和梯度的时候以fp16精度存储,执行优化算法的时候还原为fp32(缺失位补0),这样最终的效果是模型在GPU上以fp16和fp32两种方式加载,这被称为混合精度训练(mixed precision training)