
- @QIANAIQ1101
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
摘要: Anthropic发布的Claude Sonnet 5虽非Claude家族的最强模型,但在能力、速度和成本的综合表现上成为更适合高频调用的主力模型。评测显示,Sonnet 5在指令遵循、数学推理和幻觉控制等实用任务上表现突出,总分微弱反超前代高阶模型Opus 4.7,但与旗舰模型Fable 5和Opus 4.8在知识密集、长上下文处理等复杂任务上仍有差距。其核心优势在于效率——推理速度最快

摘要: Anthropic发布的Claude Sonnet 5虽非Claude家族的最强模型,但在能力、速度和成本的综合表现上成为更适合高频调用的主力模型。评测显示,Sonnet 5在指令遵循、数学推理和幻觉控制等实用任务上表现突出,总分微弱反超前代高阶模型Opus 4.7,但与旗舰模型Fable 5和Opus 4.8在知识密集、长上下文处理等复杂任务上仍有差距。其核心优势在于效率——推理速度最快
最新大语言模型评测榜单已同步上线至晓天衡宇•评测社区官网,欢迎大家访问查看更详细的评测数据。🔥近期即将推出 Claude 家族新成员 Sonnet 5 评测报告,敬请期待👇关注晓天衡宇•评测社区官方账号,获取更多大模型相关知识~

最新大语言模型评测榜单已同步上线至晓天衡宇•评测社区官网,欢迎大家访问查看更详细的评测数据。🔥近期即将推出 Claude 家族新成员 Sonnet 5 评测报告,敬请期待👇关注晓天衡宇•评测社区官方账号,获取更多大模型相关知识~
晓天衡宇评测社区持续关注大模型的发展动态,近期针对国内外主流大语言模型进行了全面评测。榜单从智能体、代码、通用、推理四个维度,并基于20+主流评测基准,对国内外主流大语言模型进行了全面评测,现公布。本文基于Top 10评测结果进行解读,完整26个模型的全量排名和维度得分,欢迎访问晓天衡宇评测社区进行查看。欢迎点击👉🏻查看完整榜单。

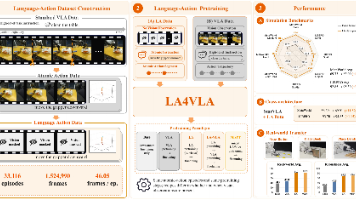
VLA模型看起来能听懂指令,实则可能严重依赖视觉捷径——视觉与语言冲突时,模型跟着画面走。上交与阿里提出LA4VLA:预训练阶段先移除视觉,让模型仅通过语言学习动作模式。评测显示真实机器人成功率从38.3%飙升至81.7%(+43 pts),仿真benchmark同样显著提升。核心思路:先建立稳固的语言-动作映射,再叠加视觉能力,为VLA训练提供了新范式。
更准确地说,是一整套围绕 Gemini 构建的 AI 系统:Gemini Flash、Gemini Omni、Gemini Audio、Nano Banana、Antigravity,以及 Gemini App、Gemini API、AI Studio、Android Studio、AI Mode、Gemini Enterprise 等入口。

晓天衡宇评测社区持续关注大模型的发展动态,近期针对国内外主流大语言模型进行了全面评测。榜单从智能体、代码、通用、推理四个维度,并基于20+主流评测基准,对国内外主流大语言模型进行了全面评测,现公布。本文基于Top 10评测结果进行解读,完整26个模型的全量排名和维度得分,欢迎访问晓天衡宇评测社区进行查看。欢迎点击👉🏻查看完整榜单。
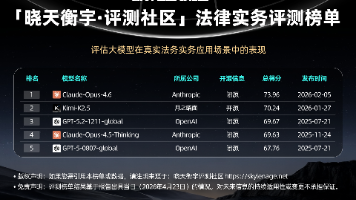
该榜单PLawBench为评测基准,对大模型在实际法律业务场景中的表现作出评测,主要覆盖用户理解、案例分析和文书生成三大方面。PLawBench旨在评估大型语言模型(LLM)在法律实践中的表现,包含三项法律任务:用户理解、案例分析和法律文书起草,涵盖了个人事务、婚姻与家庭法、知识产权以及刑事诉讼等广泛的现实法律领域。该基准旨在评估大语言模型处理实际法律任务的实践能力。【查看完整榜单】👉🏻。
AI 狼人杀只是“辩论式评测”的破局起点,这套动态博弈的评测模式,可以无缝迁移到更多真实且复杂的商业与社会场景中,根据规划矩阵,过程透明化、能力多维化、错误可追溯。晓天衡宇AI狼人杀将会在未来尝试更多可能性:多样化游戏配置:支持不同人数、角色组合和规则变体(例如守卫、白痴、狼王),以观察大语言模型在不同信息不对称结构和游戏复杂度下的行为;人机混合对局:允许人类玩家与Agent共同参与,探索人类与大