




- @ONE_SIX_MIX
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本文提供了一个Python函数is_editable(),用于检测当前包是否以可编辑模式(editable mode)安装。该函数通过importlib.metadata获取包的分发信息,检查是否存在dir_info.editable标志来判断安装模式。使用时只需修改package_name变量即可检查任意包的安装状态。函数返回布尔值,True表示可编辑模式安装,False则为正常安装模式。代码示
摘要:本文介绍了一种使用Python csv模块解析IoTDB路径的方法。IoTDB路径如root.database.123gr``o.up.device需要特殊处理,其格式类似CSV。通过自定义IOTDB_PATH_Dialect类指定分隔符为点号、引号字符为反引号等参数,再利用csv.reader即可正确解析包含特殊字符的路径。示例代码成功将三种不同格式的路径分割为组件列表,验证了该方法的有效
本文介绍了 lightweight-charts-python 项目的维护情况,该项目是基于 TradingView Lightweight Charts 的 Python 封装。当前维护者已将该库升级至 V5 版本,并新增了多项功能特性,包括实时数据流更新、多面板图表、工具箱绘制工具、事件系统等16项改进。项目支持 PySide6、wxPython 和 asyncio 环境,提供了详细的安装和构
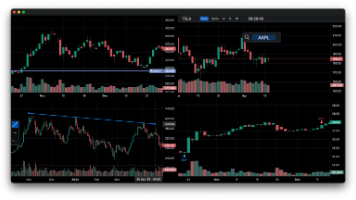
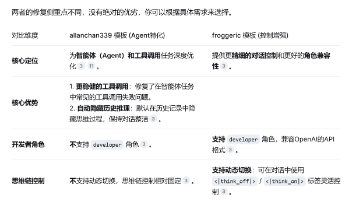
本文介绍了对Qwen3.6-35B模型的优化改进。主要解决了原模板导致的KV缓存失效、思考块堆积降智、工具调用死循环等问题。新增功能包括:支持开发者角色、动态开关思考模式(<|think_on|>/<|think_off|>)、中文思考链诱导(节省20% token)、思考长度限制(4096 token)等。通过修改模板(基于fakezeta合并版),实现了更稳定的工具调用和中文思维链(98%成功
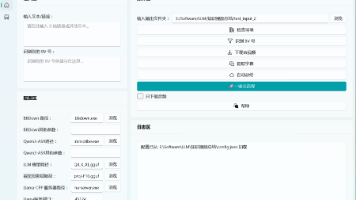
QwenPaw会话增强工具插件为QwenPaw提供了强大的会话管理功能,包括回退对话(/rewind)、分叉会话(/fork)和重新生成回复(/regen)。该插件通过命令拦截和会话文件操作实现核心功能,支持多agent工作区隔离,并集成WebUI显示。安装方式灵活,可通过命令行、插件管理或手动复制安装。插件采用MIT许可,需要QwenPaw 1.1.0及以上版本和Python 3.10+环境支持
记录,太坑了,深度学习显卡损坏原来是这样子的。时间 2020-10-23深度学习服务器,3张 RTX2080Ti。损坏的是1号卡,就是夹在0号和2号卡中间的那张卡。可能常年温度太高,烧坏了。事件记录:每过一段时间,1号卡温度和功率会变成nan。重启服务器就好了。但服务器经常有任务,也不能随便重启,没看到什么问题,就不管了。又过了一段时间。发现模型运算超慢的。还以为那里出问题了,查来查去,然后发现执
最近多了两张卡,一张P40,一张M40,都是24G显存版本,测试下训练速度。训练StyleGan类对抗生成模型,占用显存15G。核心100%满载。没有使用混合精度加速技巧。平均下来,每训练1000次RTX 3090,耗时约 107 秒Tesla P40,耗时约 245 秒Tesla M40,耗时约 346 秒时间比为RTX 3090 为 1XTesla P40 为 2.3XTesla M40 为
"播音终结技"是一款B站视频内容处理工具,具备BV号识别、视频下载、音频提取和内容总结等自动化功能。该工具基于PySide6开发图形界面,支持一键全流程操作:从视频链接自动提取BV号,通过BBDown下载视频,使用Qwen3-ASR转换音频为文本,最后利用Qwen3.5大模型生成内容摘要。项目开源且提供预构建包,需额外配置BBDown、Qwen3-ASR-GGUF等依赖项。支持
摘要:本文对比测试了Qwen3.6-35B模型的两种量化版本(UD-Q6_K_XL和APEX-I-Balanced)在逻辑推理、数学计算和文本处理任务上的表现。测试结果显示APEX量化版本在速度(110 token/s vs 98 token/s)、模型大小(23.9G vs 29.7G)和任务完成度上均优于UD-XL版本,特别是在处理复杂多步指令时,UD-XL容易出现死循环问题。三个测试题目分别
摘要:本文介绍了手动构建WebUI的方法。首先需要安装Node.js环境并确保npm可用,然后进入llama.cpp项目的webui目录执行npm安装和构建命令。接着通过cmake配置项目时开启WebUI选项(-DLLAMA_BUILD_WEBUI=ON),并禁用预构建WebUI(-DLLAMA_USE_PREBUILT_WEBUI=OFF),最后完成项目构建即可解决问题。整个过程涉及前端资源构建