
写文章




- @Mocode
简介
该用户还未填写简介
擅长的技术栈
未填写擅长的技术栈
可提供的服务
暂无可提供的服务
【强化学习理论】基于策略的强化学习——深度确定性策略梯度算法
深度确定性策略梯度算法(Deep Deterministic Policy Gradient,DDPG)是一种Actor-Critic框架的算法,该算法常用于连续控制任务(动作空间为连续型),其中Actor网络产生的动作是具体的、确定的动作而非动作的分布,因此被称为“确定性”策略梯度。本文介绍深度确定性策略梯度算法。
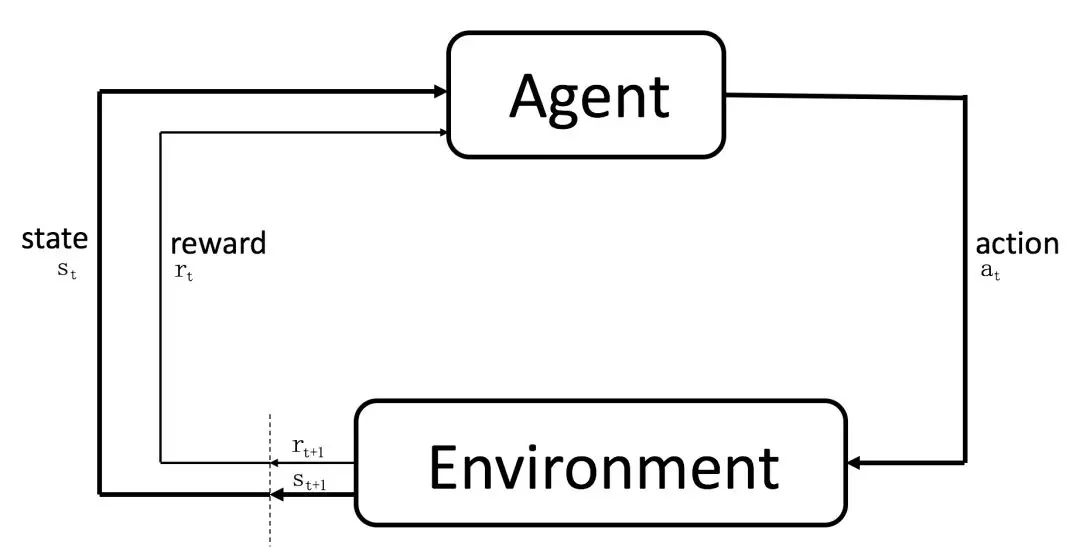
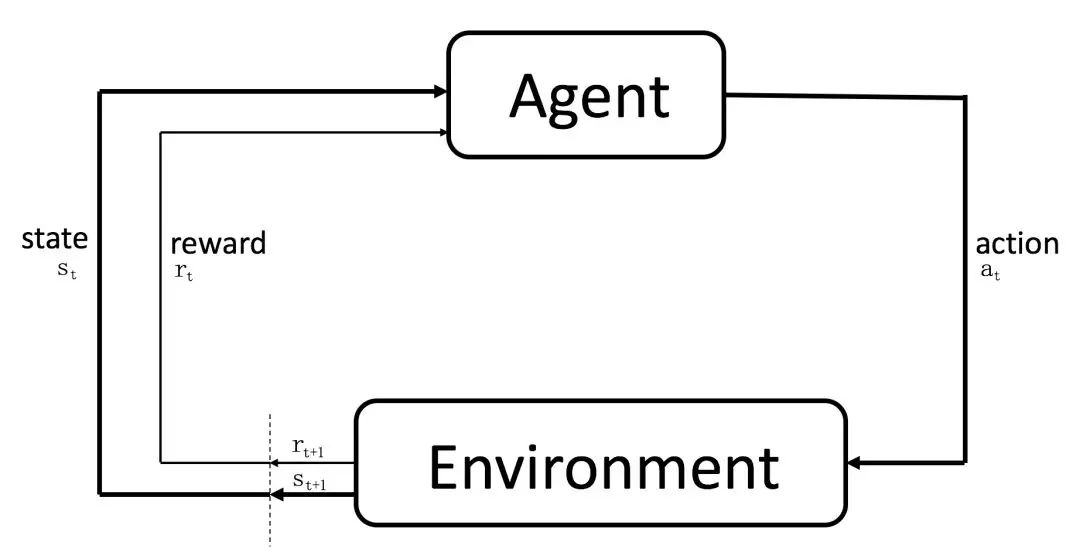
【强化学习理论】贝尔曼最优方程公式推导
继贝尔曼期望方程之后,对贝尔曼最优方程的公式推导。结合图文更好理解。
【MIMICIII 数据库安装】踩坑记录+解决方案
在安装MIMIC III数据库过程中踩到的坑与解决方案记录。
【强化学习理论】基于策略的强化学习——策略梯度算法
基于策略的强化学习方法通过计算动作分布进行动作选择。策略梯度算法(policy gradient,PG)是经典的基于策略的强化学习方法,本文对策略梯度算法进行介绍。
【2024】Datawhale AI夏令营 Task4笔记——vllm加速方式修改及llm推理参数调整上分
本文承接前一篇文章,对其中vllm加速方式进行修改,推理速度获得了极大提升。另外,在延用多路投票的同时,通过调整大语言模型的参数获得了一些分数的提升。

贝叶斯神经网络与变分推断
本文解释了贝叶斯神经网络(Bayes Neural Network, BNN)、变分推断(variational inference, VI)及二者之间的关系。

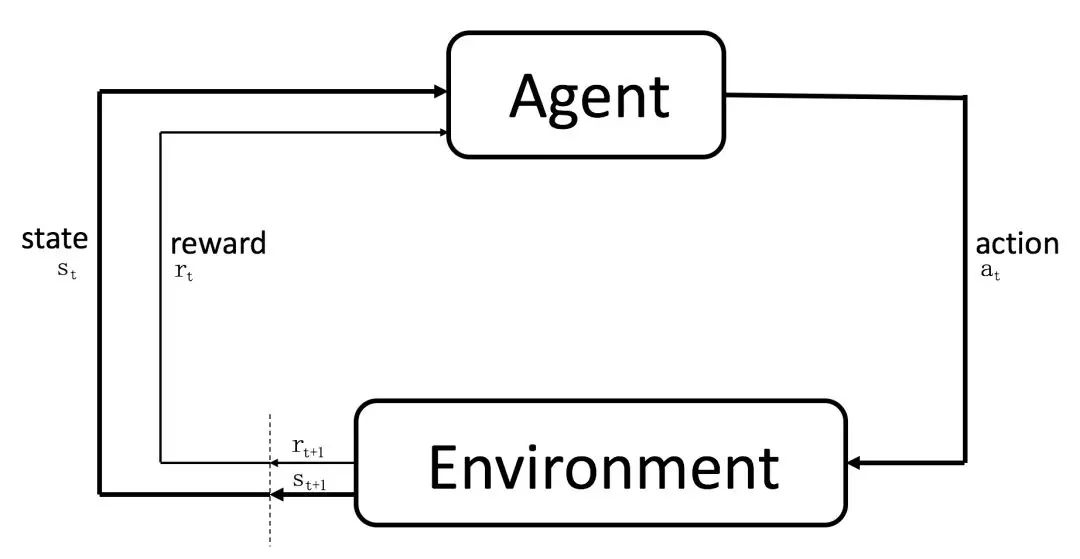
【强化学习理论】贝尔曼最优方程公式推导
继贝尔曼期望方程之后,对贝尔曼最优方程的公式推导。结合图文更好理解。
贝叶斯神经网络与变分推断
本文解释了贝叶斯神经网络(Bayes Neural Network, BNN)、变分推断(variational inference, VI)及二者之间的关系。
LLama大模型初体验——Linux服务器部署LLama注意事项
在Linux服务器部署Llama模型的注意事项。
