




- @Metal1
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
如果我们需要优化kernel程序,我们必须知道一些GPU的底层知识,本文简单介绍一下GPU内存相关和线程调度知识,并且用一个小示例演示如何简单根据内存结构优化。一、GPU总线寻址和合并内存访问 假设X指向一个32位整数数组的指针,数组首地址是0x00001232,那么一个线程需要访问第0个成员时是也许是如下访问的:int tmp = X[0]假设内存总线宽度是256...
如果我们需要优化kernel程序,我们必须知道一些GPU的底层知识,本文简单介绍一下GPU内存相关和线程调度知识,并且用一个小示例演示如何简单根据内存结构优化。一、GPU总线寻址和合并内存访问 假设X指向一个32位整数数组的指针,数组首地址是0x00001232,那么一个线程需要访问第0个成员时是也许是如下访问的:int tmp = X[0]假设内存总线宽度是256...
CrewAI是一个轻量级Python多智能体协作框架,专注于构建"AI团队"协作完成复杂任务。其核心特点包括独立架构(不依赖LangChain等框架)、角色驱动的代理设计(每个代理有明确角色和目标)以及双重执行模式(自主协作的Crews和结构化流程的Flows)。框架包含三大组件:Agent(专家成员)、Crew(团队管理)和Process/Flow(任务策略),支持自动任务分

Vue3 是一个基于组件化的前端框架,通过响应式数据自动同步页面更新。核心概念包括:单文件组件(.vue文件)整合模板、逻辑和样式;响应式数据(ref/reactive)实现数据驱动视图;模板语法(插值、指令)连接数据与DOM;组件化开发(props/emit)构建模块化应用;组合式API提升逻辑复用性;配套工具(Vue Router/Pinia)处理路由和状态管理。Vue3让开发者专注于数据状态
原文地址:https://www.zhihu.com/question/195613621、face.com以色列公司,某年六月时被Facebook收购,同时暂停了API服务,之前测试过他们的服务,基本上是了解到的应用中做得最牛的了。2、orbeOrbeus由麻省理工学院和波士顿大学的几个科学家联合创立,他们致力于让Orbeus实现能从照片或
1KNIME一款强大开源的数据挖掘软件平台通过数据挖掘可以从大量有序或者杂乱无章的数据中发现潜在的规律,甚至通过训练学习还能通过已知的数据预测未来的发展变化,今天就给大家推荐一款强大开源的数据挖掘软件平台:KNIME数据分析平台。其提供了自建服务器版和云版两种支持方式,其基本的工作流程如下,先读取要分析的数据,然后对其中的一些数据进行转换,然后分析出其中的规律,最后部署到平台,KNIME...
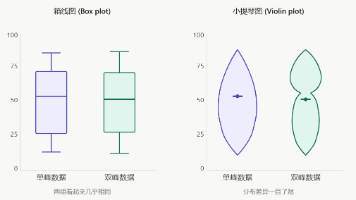
让我画一个直观的对比来帮助理解:如上图所示,左侧的箱线图中两组数据的统计摘要几乎一样(中位数、四分位距接近),很容易误以为它们是相似的分布。在房价预测中,“房屋面积"这个特征的小提琴图如果出现两个明显的"鼓包”(双峰),往往意味着数据混合了两种不同类型的房屋(比如公寓和别墅)。小提琴图(Violin Plot)是机器学习和数据分析中一种非常实用的可视化工具,它结合了箱线图和核密度估计图的优点,主要
概念板块数据结构 文件存储路径:tdx\T0002\hq_cache\block.dat 文件存储格式: 文件头:384字节 板块个数:2字节 各板块数据存储结构(紧跟板块数目依次存放) 每个板块占据的存储空间为2812个字节,可最多包含399个个股 板块名称:9字
开源期刊,又叫“开放存取”简称OA(OpenAccess)。是指将学术信息资源放到互联网上,任何人可以免费获得,而不需考虑版权或注册的限制。 开源期刊是一种免费的网络期刊,旨在使所有用户都可以通过因特网无限制地访问期刊论文全文。此种期刊一般采用作者付费出版、读者免费获得、无限制使用的运作模式,论文版权由作者保留。在论文质量控制方面,OA期刊与传统期刊类似,采用严格的同行评审制度。开