




- @LoseInVain
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
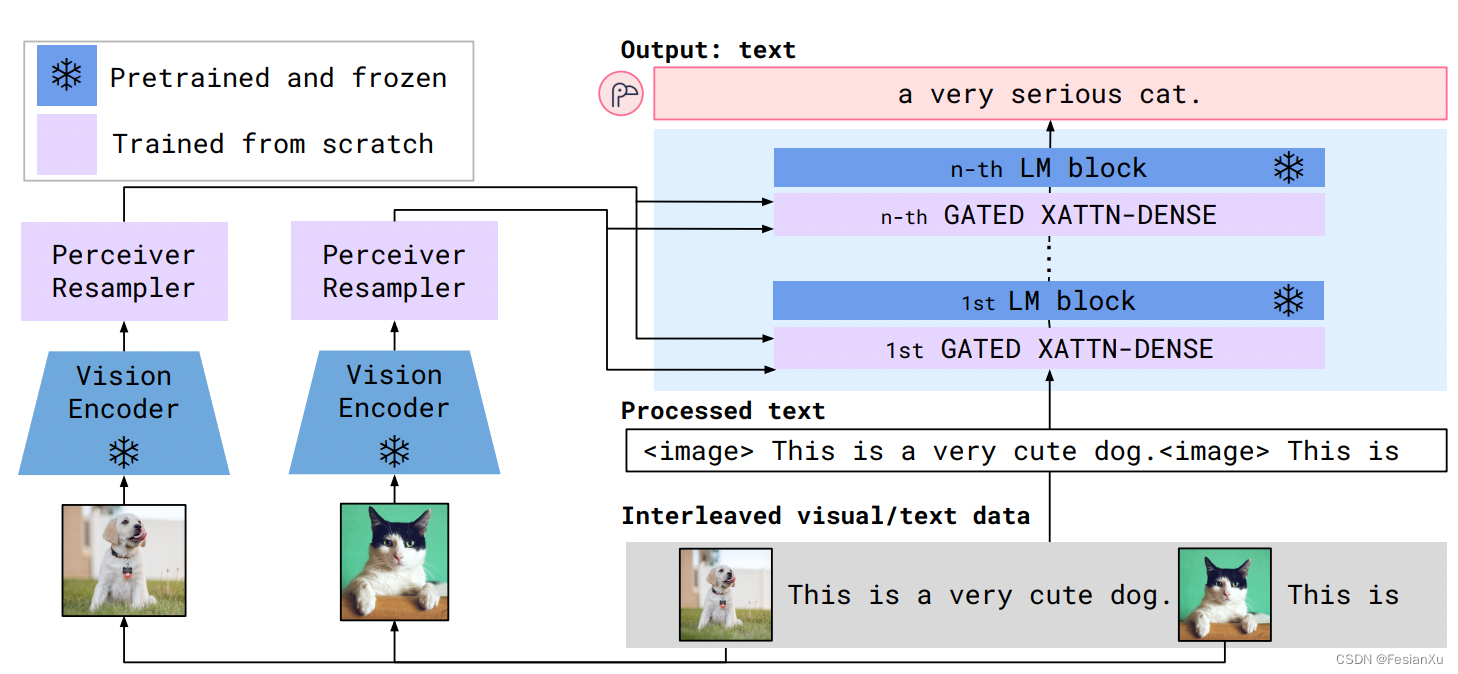
Flamingo算是DeepMind的多模态融合LLM的一个较老的工作了(2022年),之前粗略读过没来得及及时总结,本次过年笔者重新细读了论文,发现其在50多页的论文中有着不少细节,本文对该工作进行读后感笔记。
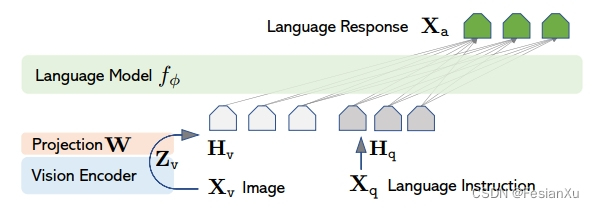
如何将已预训练好的大规模语言模型(LLM)和多模态模型(如CLIP)进行融合,形成一个多模态大语言模型(MLLM)是目前很火热的研究课题。本文将要介绍的LLava是一个经典的工作,其采用了指令微调的方式对MLLM进行训练,笔者在此笔记,希望对诸位读者有所帮助。
前言线性回归模型是机器学习中一个基本回归模型,是许多模型的基础,学习好线性回归模型有助于我们的机器学习,这里简单介绍下线性回归模型并且提供Python代码演示。如有谬误,请联系指正。转载请注明出处。联系方式:e-mail: FesianXu@163.comQQ: 973926198github: https://github.com/FesianXu代码开源:click线性回
前言:接触深度学习也有一两年了,一直没有将一些实战经验整理一下形成文字。本文打算用来纪录一些在深度学习实践中的调试过程,纪录一些经验之谈。因为目前深度学习业界的理论基础尚且薄弱,很多工程实践中的问题没法用理论解释得很好,这里的只是实践中的一些经验之谈,以供参考以及排错。本文将持续更新。如有问题请指出,联系方式:e-mail: FesianXu@163.comQQ: 973926198gi...
前言:接触深度学习也有一两年了,一直没有将一些实战经验整理一下形成文字。本文打算用来纪录一些在深度学习实践中的调试过程,纪录一些经验之谈。因为目前深度学习业界的理论基础尚且薄弱,很多工程实践中的问题没法用理论解释得很好,这里的只是实践中的一些经验之谈,以供参考以及排错。本文将持续更新。如有问题请指出,联系方式:e-mail: FesianXu@163.comQQ: 973926198gi...
WenLan 2.0的方法介绍和个人理解

【多视角立体视觉系列】 几何变换的层次——投影变换,仿射变换,度量变换和欧几里德变换20200226 FesianXu前言几何变换非常常见,在计算机视觉和图形学上更是如此,而这里指的几何一般是由点,线,面等几何元素组成的1,2维或3维图形。几何变换能够实现不同空间几何元素的对应,在很多领域中有着非常多的应用,立体视觉便是其中一个。本文尝试对四种不同类型的几何变换进行...
双目三维重建——层次化重建思考FesianXu 2020.7.22 at ANT FINANCIAL intern前言本文是笔者阅读[1]第10章内容的笔记,本文从宏观的角度阐述了双目三维重建的若干种层次化的方法,包括投影重建,仿射重建和相似性重建到最后的欧几里德重建等。本文作为介绍性质的文章,只提供了这些方法的思路,并没有太多的细节,细节将会由之后的博文继续展开。如有谬误,请联系作者指出,转载请
视频分析与多模态融合之一,为什么需要多模态融合FesianXu 20210130 at Baidu search team前言在前文《万字长文漫谈视频理解》[1]中,笔者曾经对视频理解中常用的一些技术进行了简单介绍,然而限于篇幅,意犹未尽。在实习工作中,笔者进一步接触了更多视频分析在视频搜索中的一些应用,深感之前对视频分析在业界中应用的理解过于狭隘。本文作为笔者对前文的一个补充,进一步讨论一下视频
CLIP中的infoNCE损失是一种对比性损失,在SigLIP这个工作中,作者提出采用非对比性的sigmoid损失,能够更高效地进行图文预训练
