




- @Libra1313
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
*工具实战:**集中训练抓包工具(Wireshark)、渗透测试工具(Nmap)、漏洞扫描工具(Nessus 基础版)的使用,结合模拟场景练习工具应用(掌握基础扫描逻辑,为 SRC 漏扫工具进阶做准备)。实战技能训练:开展漏洞扫描、漏洞利用、电商系统渗透测试、内网渗透、权限提升(Windows、Linux)、代码审计等实战训练,结合运维中熟悉的系统环境设计测试场景(强化红蓝对抗攻击端技术能力)。操
批量设备配置、收集日志/状态,比逐台 CLI 效率高很多。:写好的脚本能在不同厂商(华为、华三、思科、锐捷)设备上应用。:能和数据库、监控系统、Web 平台结合,形成自动化运维系统。
通过第四模块的接口开发,我们知道接口的请求方式有多种,在接口测试时我们不可能针对不同请求方式的接口不断的改变它的请求方法形式和参数,所以可以将多种不同请求方式统一整合,只改变请求方法(GET、POST、DELETE、UPDATE)来切换不同的请求形式。引进持续继承,就是让它来做一些重复的事情。**工具实战:**集中训练抓包工具(Wireshark)、渗透测试工具(Nmap)、漏洞扫描工具(Ness
之前的文章说过, 要写一篇自动化实战的文章, 这段时间比较忙再加回家过11一直没有更新博客,今天整理一下实战项目的代码共大家学习。
输出示例:# 运行测试:pytest -v test_api.py# 运行测试:pytest -v test_api.py这些示例展示了如何使用Python来执行各种接口自动化测试任务,从简单的GET和POST请求到更复杂的认证、文件上传和响应验证。希望这些代码片段能为你的测试工作提供灵感和指导!
L4阶段:大模型的微调和私有化部署,我们会更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调;而L3 L4更多的是通过项目实战来掌握大模型的应用开发,针对以上大模型的学习路线我们也整理了对应的学习视频教程,和配套的学习资料。在你已经掌握了大模型技术之后,就需要开始准备面试,我们将提供精心整理的大模型面试题库,涵盖
网上看到一首诗:“代码尽头谁为峰,一见秃头道成空。编程修真路破折,一步一劫渡飞升。”感觉还挺有意境的。

Java作为一门拥有近30年历史的编程语言,凭借其和,始终占据编程语言排行榜前列。面对云原生、微服务、AI等技术的蓬勃发展,Java也在持续进化(如虚拟线程、GraalVM)。本文将为初学者和进阶者梳理一条清晰的2025年Java学习路线,涵盖的全流程,并提供实用的学习资源推荐。
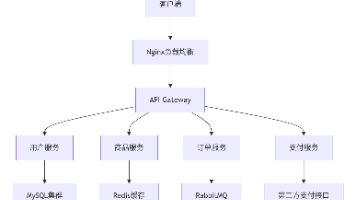
用户认证与权限管理商品管理与分类浏览购物车与订单处理支付接口集成后台管理系统。
IDEA配置:新建项目时选择"Java 21",并启用预览特性(以使用最新语法)