




- @Lab4AI
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
DeepSeek-OCR突破传统OCR局限,通过“压缩+解码”架构高效解析多模态文档。其核心包括双阶段视觉压缩引擎(DeepEncoder)和MoE解码器,能以10-20倍压缩比处理图像,在保持高精度的同时显著提升速度并降低显存占用。该技术仅需3B参数即可深度解析文字、表格、图表等内容,并支持3分钟私有化部署。Lab4AI平台提供全流程支持,用户可快速体验从文档上传到结构化输出的完整流程,实现高效

本文详细介绍了两种大模型本地部署方案:面向生产环境的VLLM部署和适合个人快速体验的Ollama部署。VLLM方案具有高性能推理、高吞吐量等优势,适合Linux系统;Ollama方案则简单易用、硬件要求低,支持Windows系统。文章从环境准备、部署步骤到调用示例逐步展开,并解释了模型量化原理。通过本地部署,用户可以更好地保障数据安全、控制服务稳定性并降低长期成本。此外,还提供了优化技巧和参数配置
本文以DeepSeek-OCR-2为例,详解其核心特性、本地部署及vLLM推理实战。并延伸后处理策略,涵盖数据清洗、RAG优化到多模态检索,打通从“读出来”到“用起来”的全链路,为高质量数据集构建提供实战指南。有了OCR工具等统一格式后,接下来数据处理流程的重要工作就是构建数据集了,下篇内容笔者将分享当前通用的数据处理工具EasyDataset, 大家敬请期待~
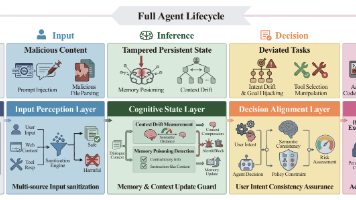
本文系统分析了OpenClaw自主AI代理的安全威胁,提出了五层生命周期导向的安全框架(初始化、输入、推理、决策、执行),揭示了跨阶段复合风险。研究通过案例验证了技能中毒、记忆中毒等威胁的实际影响,指出现有单点防御的局限性,并提出纵深防御架构设计原则。该研究为构建安全可靠的自主AI系统提供了重要参考,未来可探索硬件辅助安全原语和动态自适应防御策略。
本文提出了 EvolveRouter,一个通过闭环协同进化联合优化路由与智能体配置的创新框架,有效解决了多智能体问答中智能体质量静态化和协作规模僵化的两大核心问题。实验结果充分验证了其相对于现有 SOTA 方法的优越性。
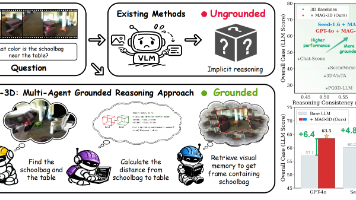
MAG-3D提出无需训练的多智能体三维具身推理框架,通过规划、定位、编码三智能体动态协同,结合开放词汇三维定位与可执行几何验证,在Beacon3D、MSQA基准上实现零样本最优性能,同时大幅提升定位与问答的一致性,有效解决现有方法依赖微调、流程僵化、易产生幻觉的问题,为开放世界三维可靠推理提供实用方案。
在相当长的一段时间里,目标检测领域存在一个核心的权衡:要么选择像 YOLO 系列那样拥有极致速度但只能识别固定类别的“闭集”检测器,要么选择像 Grounding DINO 那样能够识别任意文本描述但速度较慢的“开放集”检测器。对于需要实时响应和灵活性的现实世界应用(如机器人、自动驾驶),这一直是个难题。于2024年初发布的 YOLO-World 彻底打破了这一局面。该研究首次成功地将开放词汇(O
论文《FBRT-YOLO: Faster and Better for Real-Time Aerial Image Detection》提出了一种针对航拍图像目标检测的优化方法。针对航拍场景中小目标密集、尺度变化大等挑战,该研究通过轻量化网络设计、增强的多尺度特征融合、专设小目标检测层以及注意力机制等技术,显著提升了检测速度和精度。实验表明,FBRT-YOLO在保持高精度的同时实现了更快的处理速

VideoLLaMA 3是基于Llama 3的前沿多模态基础模型,深度融合视觉、听觉与语言理解能力,支持高分辨率图像和长视频的端到端分析。其核心技术包括统一的视听语言架构、高效长视频词元化和万亿级多模态预训练,具备复杂的时空因果推理能力,可同步解析画面与音轨信息。该模型为影视分析、场景理解等任务提供强大支持,相关代码和预训练权重已在Lab4AI平台开源,用户可一键复现实验。
语义分割模型在训练和测试数据来自同一领域(如晴天)时表现优异,但当遇到未见过的领域(如雨天、雪天)时,性能会因“领域偏移”(Domain Shift)问题而急剧下降。为了解决这一挑战,该论文提出了一种全新的文本查询驱动(Textual query-driven)的分割范式。该模型的核心思想是,不再仅仅依赖像素信息进行学习,而是将分割任务重新构建为一个通过文本查询匹配目标的过程。
