




- @Java_rich
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
李飞飞团队提出多模态智能体"感知-认知-行动-学习-记忆"五模块架构,突破传统AI被动模式。该架构融合大语言模型与视觉语言模型,使智能体具备环境交互和持续进化能力。论文详细阐述了基础模型代理化的技术路径,包括预训练阶段的领域随机化和微调阶段的"LLM+VLM"双引擎架构。多模态融合技术显著降低模型幻觉率,在医疗、游戏等领域展现应用潜力,但需平衡技术价值与伦理

《Sanet.st_PromptEngineeringforLLMs》是一本关于优化大语言模型(LLM)提示设计的实用指南。书中强调"提示设计逻辑"的重要性,提出"角色设定+任务指令+约束条件"的黄金三角结构,可显著提升AI输出的精准度。作者指出常见误区如冗长提示会稀释核心指令,并针对不同LLM提供适配技巧。该书适合从新手到资深用户,提供了一套可落地的框架,

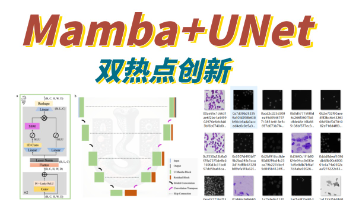
本文探讨了将Mamba与U-Net结合的创新方法,重点介绍了几种关键的技术融合策略。首先提出用Mamba替代U-Net编码器深层阶段或解码器跳跃连接中的传统卷积层,以高效捕捉长程依赖关系。其次,设计了基于Mamba的轻量化架构,通过残差视觉Mamba层显著降低模型复杂度。论文还提出了多尺度建模方案,结合像素级和块级状态空间模型实现层次化特征提取。在实验设计方面,建议选择医学图像分割数据集进行验证,
深度学习是一种模仿人脑神经网络结构和功能的机器学习方法,通过构建多层神经网络模型,自动从大规模数据中学习复杂的特征表示。其核心原理包括和层次化特征提取:通过多层非线性变换,逐步提取数据的高级语义特征端到端学习:直接学习输入与输出间的映射关系,无需人工干预这种机制使深度学习能有效处理高维、非线性数据,在图像识别、语音识别和自然语言处理等领域展现出卓越性能。

在正文开始之前,先给大家带来一个超值福利!为了方便同学们快速开启人工智能学习计划,在学习过程中少走弯路用最快的效率入门Ai并开始实战项目。我们整理了近200个Ai实战案例和项目,这些并不是网上搜集来的,而是我们这五年线上线下教学所开发和积累的案例。-* 可以说都是反复迭代更新出来的,适合同学们来进行循序渐进的学习与练手。需要的扫码。

欢迎大家扫描文末的二维码进行咨询(学习交流、大牛答疑、大厂内推)另外我还整理了整整200G的人工智能学习笔记、课程视频、面试宝典一并可以无套路免费分享给大家!这是小编的其他文章,希望对大家有所帮助,点击即可阅读人工智能常用的十大算法人工智能数学基础(一)人工智能数学基础(二)人工智能数学基础(三)人工智能数学基础(四)遗传算法(Genetic Algorithm,GA)遗传算法是计算数学中用于解决
本文总结了人工智能领域六大创新模型组合方向及其研究价值:1. Transformer+CNN实现全局-局部特征互补;2. 多模态+生成模型构建跨模态生成范式;3. 自监督+多模态提升小样本学习能力;4. 小波变换+Transformer增强频率域建模;5. 动态网络+轻量化模型优化计算效率;6. LLM+计算机视觉实现多模态智能交互。研究显示,这些组合通过创新架构设计(如交互自注意力、动态路由等)

深度学习是机器学习的一个子集,通过构建多层神经网络模拟人脑的抽象和推理能力,特别擅长处理图像、语音、文本等非结构化数据。其核心优势在于自动特征提取能力,相比传统机器学习依赖人工设计特征,深度学习通过多层非线性变换自动发现数据中的隐藏规律。
特别是监督学习方法,包括感知机、k近邻法、朴素贝叶斯法、决策树、逻辑斯谛回归与最大熵模型、支持向量机、提升方法、em算法、隐马尔可夫模型和条件随机场等。叙述从具体问题或实例入手,由浅入深,阐明思路,给出必要的数学推导,便于读者掌握统计学习方法的实质,学会运用。第3部分为进阶知识,内容涉及特征选择与稀疏学习、计算学习理论、半监督学习、概率图模型、规则学习以及强化学习等。需要论文指导发刊的 【AI交叉

精通机器学习算法,主攻计算机视觉方向,线上选课学员30W+,累计开发课程50余门覆盖人工智能热门方向。联通,移动,中信等公司特邀企业培训导师,全国高校教师培训讲师,开展线下与直播培训百余场,具有丰富的授课经验。课程风格通俗易懂,擅长有最接地气的方式讲解复杂的算法问题。具体了解这套计算机视觉【机器学习+深度学习】课程的微信扫码人工智能已从实验室的前沿技术演变为重塑社会的核心力量。它既是职业发展的 “
