- @Humbunklung
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
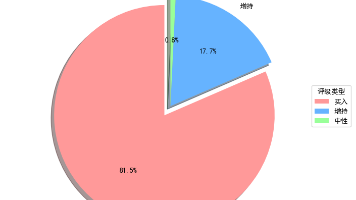
该接口用于获取新浪财经的机构推荐池数据,涵盖最新投资评级、目标价、行业分类等关键指标。数据来源为专业金融机构(券商、基金等)发布的股票评级报告,反映市场主流机构对个股的价值判断。
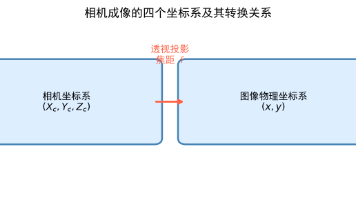
相机标定是通过数学方法估计相机成像模型参数的过程,包括描述光学特性的内参(焦距、主点坐标)、相机位姿的外参(旋转矩阵、平移向量)以及镜头畸变系数。标定的核心目的是建立像素坐标与世界坐标的精确映射关系,校正镜头畸变,提高测量精度。标定基于针孔相机模型,涉及世界坐标系、相机坐标系、图像物理坐标系和像素坐标系四个坐标系的转换。OpenCV等工具库提供了便捷的标定方法,通过标定板图像可自动计算这些参数。精
match是Rust中最强大的控制流工具之一,它提供了一种优雅的方式来处理多种可能性。就像硬币分拣机一样,match能够精确地将值分配到正确的处理路径。

使用openpyxl,我们可以轻松地在 Excel 单元格中设置公式,并且可以引用其他工作簿中的单元格内容。使用 openpyxl 库,我们还可以将多个工作簿的内容合并到一个新的工作簿中,方便进行数据处理和分析。
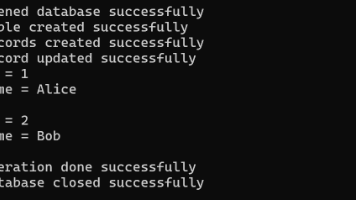
本文档介绍如何在 C++ 项目中使用 SQLite3 数据库,假设通过 vcpkg 安装了 SQLite3。因本机为Windows环境,为方便,用了本机的Visual Studio 2022 创建cmake项目。
最近打算储备一些接口,于是结合AI做了简单的整理,后续再一个一个尝试。以下是目前可用的免费A股行情数据接口及使用指南,结合稳定性和易用性综合推荐

该接口用于获取新浪财经的机构推荐池数据,涵盖最新投资评级、目标价、行业分类等关键指标。数据来源为专业金融机构(券商、基金等)发布的股票评级报告,反映市场主流机构对个股的价值判断。
之前本机跑了一套SonarQube的社区版,默认使用的是H2数据库,那么我把它练到我机器上的SQL Server数据库了,期间遇到以下两个问题,并在配置过程中解决掉,特将这个过程记录下来。“Encrypt”属性设置为“true”且 “trustServerCertificate”属性设置为“false”,但驱动程序无法使用安全套接字层 (SSL) 加密与 SQL Server 建立Database
使用命令克隆远程github仓库时超时,如下图所示:以下载某个仓库为例,报错信息为:解决办法参考stackoverflow上的帖子,给本地git工具设置代理,顺利下载代码,如下图:设置全局性http代理的代码如下(假定http代理的端口为7890):查看当前http代理状态:取消http代理设置:完整示例

日常经常用到这俩的一些环境变量,特记录下来,如有错误,还请指正。