




- @HYY_2000
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
这篇文章介绍了一个基于AI辅助开发的Markdown转PDF在线工具,主要特点包括: 开发背景:为解决Markdown分享不便的问题,开发可自定义样式的PDF转换工具 技术栈:使用Claude Code+GLM 4.6+MCP工具,2天完成开发 核心功能: 实时预览编辑效果 支持多种主题样式定制 专门优化小说阅读主题(护眼模式/装饰背景) 采用打印方案实现高质量PDF导出 AI开发过程:通过16轮

CatBoost 是由俄罗斯搜索巨头 Yandex 于 2017 年开源的机器学习库,其名称来源于 “Category” 和 “Boosting” 的组合,旨在高效处理类别特征的梯度提升算法。支持类别特征:无需对类别特征进行独热编码,直接处理类别数据,避免数据膨胀。对缺失值的鲁棒性:无需特殊预处理即可直接处理缺失值。防止过拟合:内置多种正则化手段,减少梯度偏差和预测偏移,提高模型的准确性和泛化能力

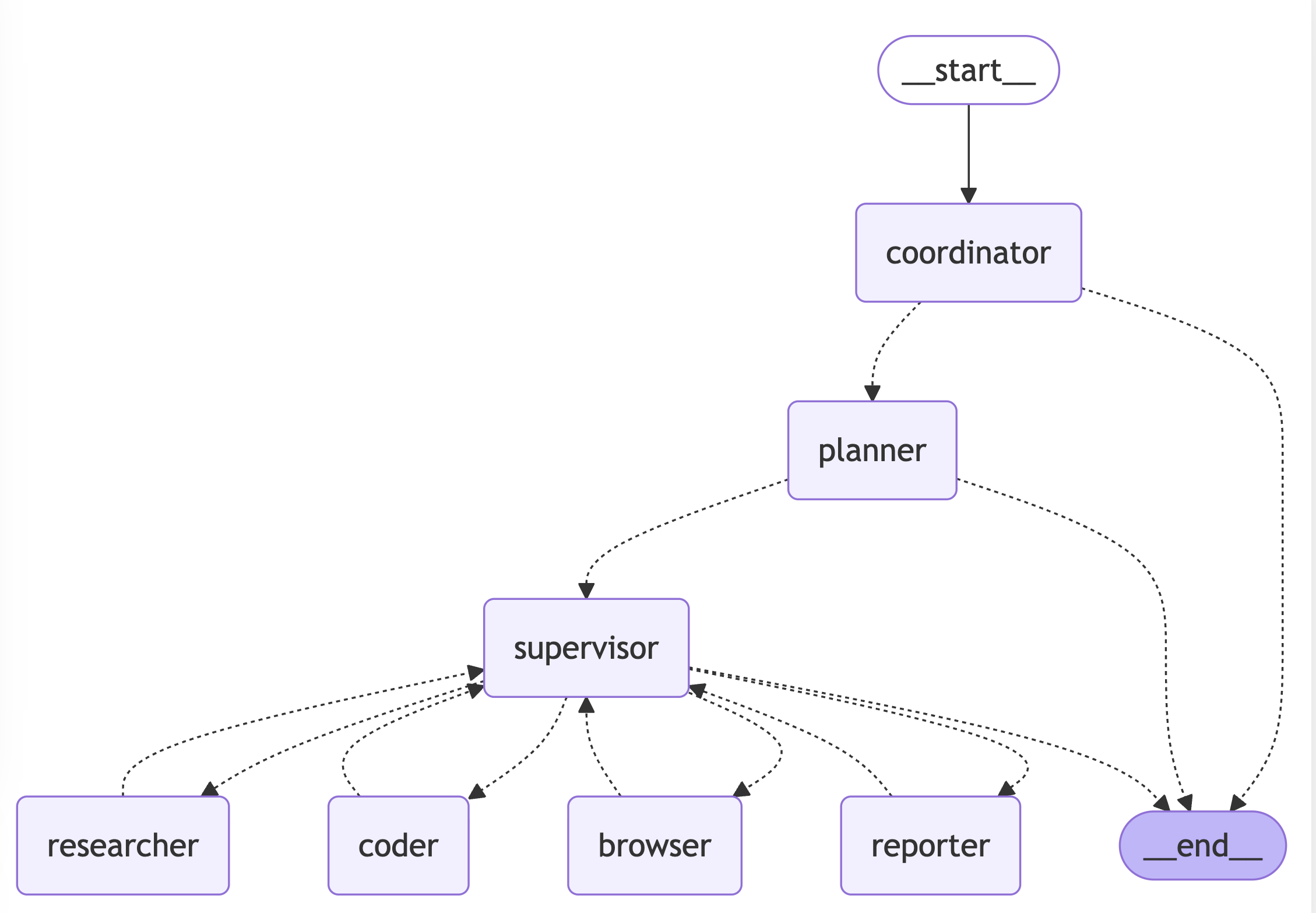
LangManus是一个由社区驱动的开源AI自动化框架,其核心价值在于通过分层多智能体系统,协调语言模型(如通义千问)与专业工具(如Tavily搜索、Jina神经搜索、Python执行环境),解决跨平台数据采集与分析、自动化代码生成与调试、复杂决策任务的分解与执行等场景。langgraph是由LangChain团队开发的一个专门用于构建LLM应用工作流的框架,它的核心理念是将复杂的LLM应用工作流
本文只是实现了一个简易版的DQN走迷宫,想要一个泛化能力超级好的DQN还没有实现。

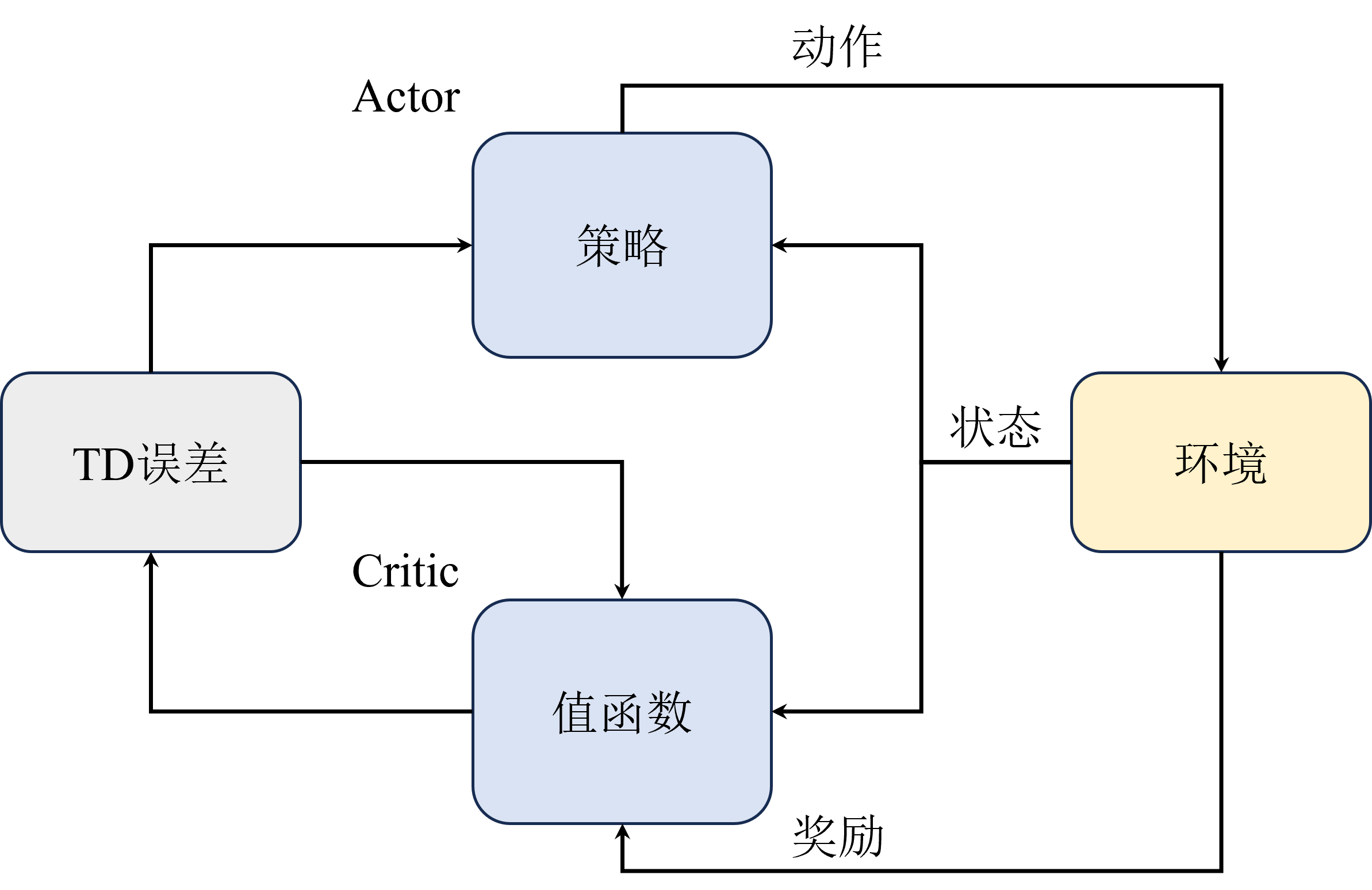
相比REINFORCE算法,为什么A2C可以提升速度?A2C增加了Critic组件用于估计状态价值,这样Actor可以利用Critic提供的价值信息来更新策略,使得学习过程更加高效。A2C、A3C是on-policy的吗?A2C算法是on-policy的,因为它根据当前策略生成的样本来更新这个策略,这意味着它评估和改进的是同一个策略。A3C算法虽然采用了异步的更新机制,但它本质上仍然是on-pol
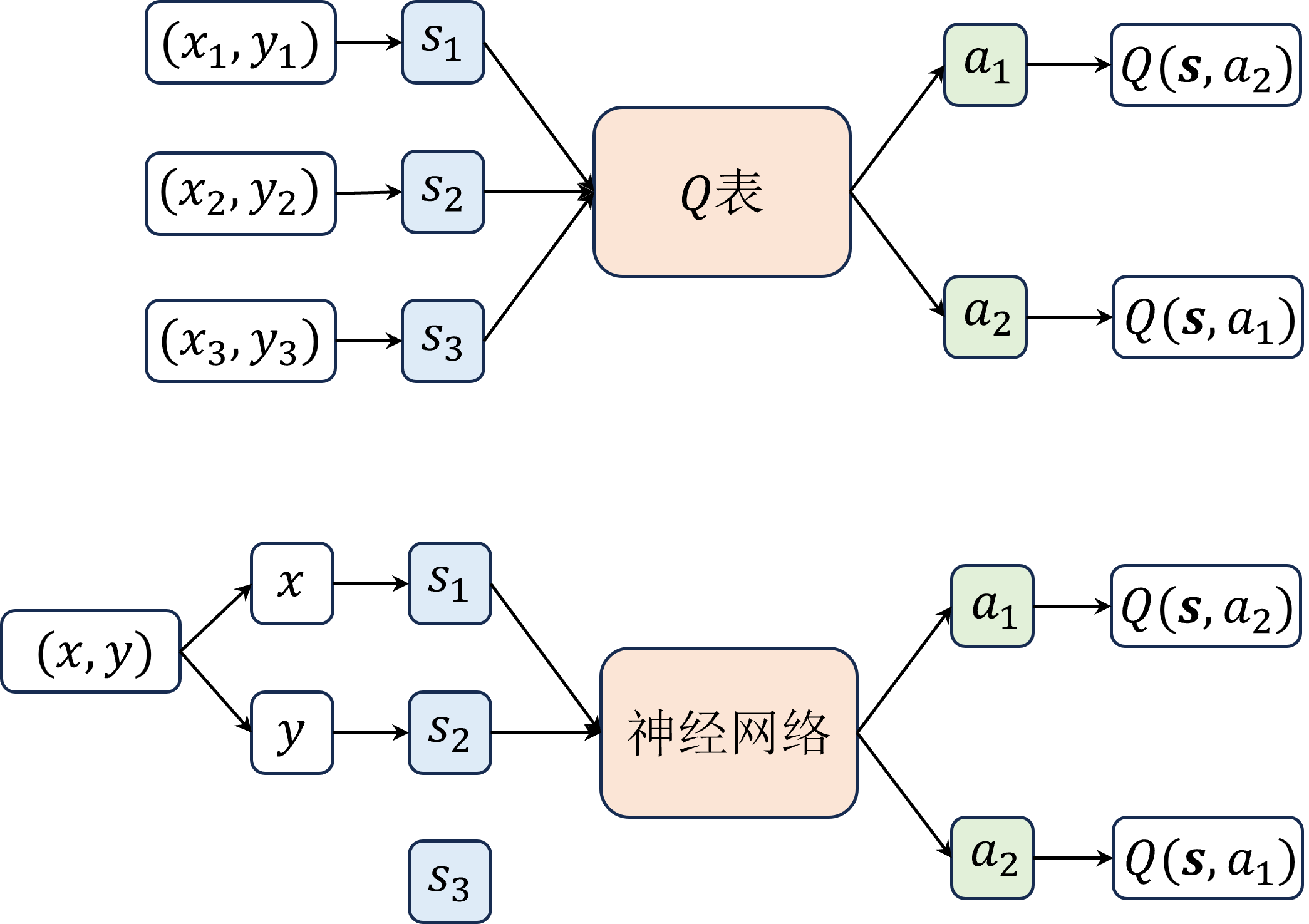
Dueling DQN修改的是网络结构,算法中在输出层之前分流( dueling )出了两个层,如图所示,一个是优势层,用于估计每个动作带来的优势,输出维度为动作数一个是价值层,用于估计每个状态的价值,输出维度为 1。在传统的DQN中,选择和评估动作的Q值使用相同的网络,这可能导致在某些状态下对某些动作的Q值被高估,从而影响学习的稳定性和最终策略的质量。经验回放:通过存储代理的经验(状态,动作,奖
本次实验所应用的三种策略Q-learning、Sarsa和蒙特卡洛都是解决强化学习问题的算法,它们在学习过程中都通过与环境的交互来优化策略。且都用于值函数估计,这三种算法的目标都是学习状态或状态动作对的值函数,即Q值或V值。更新方式不同:Q-learning: 使用了离线学习的方式,通过选择当前状态下值最大的动作来更新Q值。更新公式中使用了max操作。Sarsa: 使用在线学习的方式,通过选择当前
本文探讨提升大模型生成Mermaid语法图的准确率。通过两个优化方向:1)优化提示词降低初次生成错误率(从12%降至5%);2)开发实时校验修复方案。重点介绍使用Mermaid官方API和JSDOM构建Node环境校验器,解决DOMPurify兼容性问题,最终通过补丁修改实现100%修复成功率。测试数据显示初始错误率4%,经修复后全部成功,为Mermaid图生成提供了可靠解决方案。
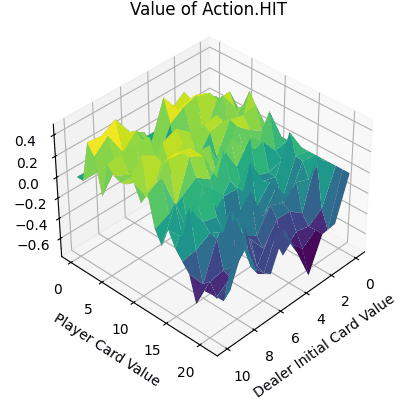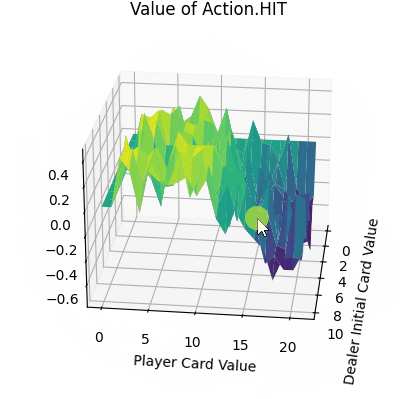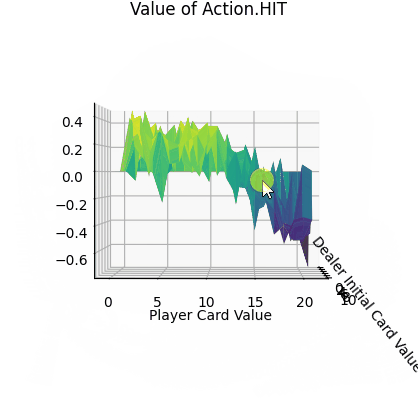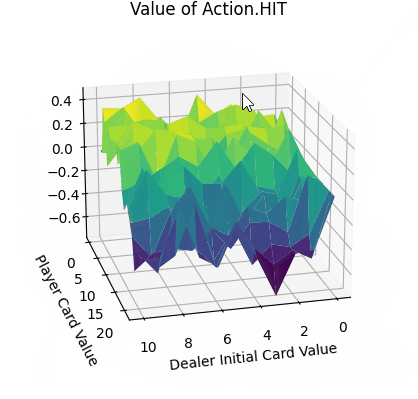
Q-learning是一种基于强化学习的算法,用于解决Markov决策过程(MDP)中的问题。这类问题我们理解为一种可以用有限状态机表示的问题。它具有一些离散的状态state、每一个state可以通过动作action转移到另外一个state。每次采取action,这个action都会带有一些奖励reward(也可以是负数,这样就表示惩罚了)。在Q-learning中,我们有一个智能体(Agent)

本文只是实现了一个简易版的DQN走迷宫,想要一个泛化能力超级好的DQN还没有实现。