




- @HG0724
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
IEEE 754浮点数标准中,指数E=0和E=255被设计为特殊值,用于处理边界情况。正常情况下E取值1-254,对应真实指数-126至+127。当E=0时:若M=0表示±0;若M≠0表示非规格化数(0.M×2⁻¹²⁶),填补极小数的表示空白。当E=255时:M=0表示±∞,M≠0表示NaN(无效运算结果)。这种设计实现了浮点数表示的完整性,既能处理常规数值,又能表示0、无穷大和错误状态,同时保持

文章摘要 本文详细解析了单精度浮点数(float)的4字节表示范围计算过程,从二进制存储原理出发,逐步介绍了浮点数的概念、IEEE 754标准的作用、指数的存储方式以及偏移量的设计。重点说明了浮点数如何通过科学计数法(二进制)表示极大或极小的数值,并解释了指数和尾数的分工。最终推导出float的范围±3.4×10³⁸的由来,帮助读者彻底理解浮点数的存储机制和计算逻辑。 (150字)

文章目录需求一、数据预处理二、分析数据需求获取源数据–密码:hxqy读取文件usa_election.txt查看文件样式及基本信息指定数据截取,将如下字段的数据进行提取,其他数据舍去:cand_nm :候选人姓名contbr_nm :捐赠人姓名contbr_st :捐赠人所在州contbr_employer :捐赠人所在公司contbr_occupation :捐赠人职业contb_receipt

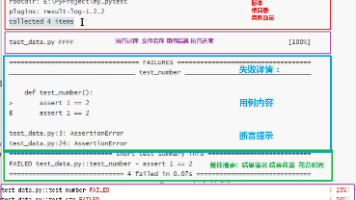
本文介绍了pytest测试框架的基本使用方法。首先通过conda创建独立环境并安装pytest8.3版本,详细说明了三种启动方式(命令行、代码、鼠标启动)。阐述了pytest的用例发现规则和内容规则,要求测试函数必须是test_开头且无参数无返回值。通过add函数的测试示例展示了测试用例编写方法。还介绍了配置框架的两种方式(命令行参数和ini配置文件),重点讲解了mark标记功能,包括用户自定义标
中,你可以从0->1使用python跟着作者走一遍如何使用该方法来处理不平衡的数据集。样本个数:568630;正样本占50.00%;负样本占50.00%样本个数:284807;正样本占0.17%;负样本占99.83%通过SMOTE方法平衡正负样本后。

文章目录需求一、数据预处理二、分析数据需求获取源数据–密码:hxqy读取文件usa_election.txt查看文件样式及基本信息指定数据截取,将如下字段的数据进行提取,其他数据舍去:cand_nm :候选人姓名contbr_nm :捐赠人姓名contbr_st :捐赠人所在州contbr_employer :捐赠人所在公司contbr_occupation :捐赠人职业contb_receipt
文章目录前言一、KNN分类算法1.1 引入数据**加粗样式**1.2 可视化二、KNN算法实现前言邻近算法,或者说K最近邻(KNN,K-NearestNeighbor)分类算法是数据挖掘分类技术中最简单的方法之一。所谓K最近邻,就是K个最近的邻居的意思,说的是每个样本都可以用它最接近的K个邻近值来代表。近邻算法就是将数据集合中每一个记录进行分类的方法一、KNN分类算法1.1 引入数据加粗样式iri
中,你可以从0->1使用python跟着作者走一遍如何使用该方法来处理不平衡的数据集。样本个数:568630;正样本占50.00%;负样本占50.00%样本个数:284807;正样本占0.17%;负样本占99.83%通过SMOTE方法平衡正负样本后。
文章目录前言一、实战演示1.1 调用摄像头实时显示画面1.2 实时边缘检测1.3 实时人脸+眼睛+微笑识别总结前言在github可以看到Opencv的所有源代码openCV官网:https://opencv.org/openCV github:https://github.com/opencv/opencvOpencv-python 是接口(API)Opencv-python一、实战演示1.1 调