- @Darlingqiang
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
现有前馈式3D重建模型(如VGGT、DUSt3R、MASt3R)虽然摆脱了后优化流程,但模型规模和数据规模对重建精度的影响尚未被系统探索。VGGT-Ω 在架构、数据和训练三个维度同时做了规模化改进:引入 Register Attention 替代部分全局注意力以降低计算开销,用单一 Dense Head + Pixel Shuffle 替代多头 DPT 以节省显存,并构建了覆盖4M序列(含动态场景
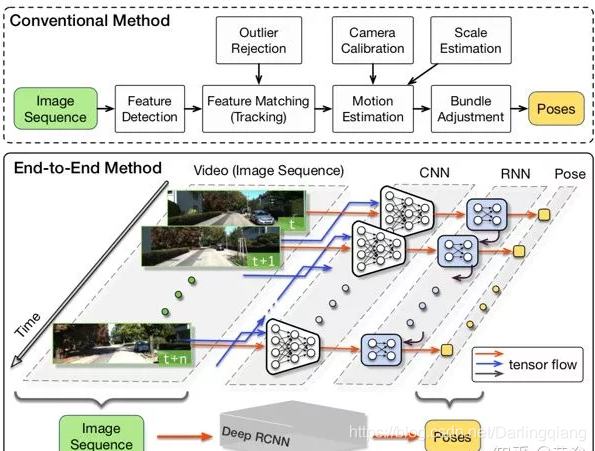
经典的计算机视觉问题是3-D重建。基本上可以分成两种路径:一是多视角重建,二是运动重建。前者有一个经典的方法是多视角立体视觉(MVS,multiple view stereo),就是多帧的立体匹配,这样采用CNN模型来解决也合理。传统MVS的方法可以分成两种:区域增长(region growing)和深度融合(depth-fusion)。soccor on tabke 等效果惊艳,在现有的5G..
VLM 决定认知上限VLN 决定任务表达能力VLA 决定商业可行性。
生成式AI与更广泛的AI有着相同的“为什么是现在(Why now)”的原因:更好的模型,更多的数据,更多的算力。这个类别的变化速度比我们所能捕捉到的要快,但我们有必要在大背景下回顾一下最近的历史。第1波浪潮:小模型(small models)占主导地位(2015年前),小模型在理解语言方面被认为是“最先进的”。这些小模型擅长于分析任务,可以用于从交货时间预测到欺诈分类等工作。但是,对于通用生成任务

VLM 决定认知上限VLN 决定任务表达能力VLA 决定商业可行性。
先来一份调研数据:2019 年,全球六大手机品牌的市场份额总计达到 73.3%,同比上升 3.98 个百分点。2019年是 5G 手机出货的元年,头部厂商发布强势产品,在 5G 手机领域依然占据非常高的市场份额。2019 年,华为、三星、 vivo 在全球 5G 手机市场份额分别是 36.9%、 35.8%、 10.7%。(Strategy Analytics,东莞证券)。下面是笔者关注的...
1. 动态目标实时三维重建-结构光方案动态目标 三维重建Stripe boundary codes for real-time structured-light range scanning of moving objects我们提出了一种新的实时结构光扫描方法。在分析现有结构光技术的基本假设之后,我们基于编码投影条纹之间的边界,导出了一组新的照明模式。这些条纹边界码允许对移动物体的距离扫描,只对
本文结合一些pape并且将资源进行整合,以便于后期的学习。博客将这些资源一下,这里不得提到大名鼎鼎的KinectFusion以及他后面的一系列工作。KinectFusion单篇论文引用都已经超过3000次了,可以称得上是具有划时代意义的一篇巨著,如果只想看现阶段效果最好的三维重建算法,请拉到文章最后(如有更好的算法,还请各位留言告知,以便于笔者及时更新,还望告知)一、KinectFusion(..
分水岭算法实现(C++、opencv)1.作用:分割图像,2.实现:#include <cmath>#include <iostream>#include <memory>#include <opencv2/core/core.hpp>#include <opencv2/highgui/highgui.hpp>#include <o
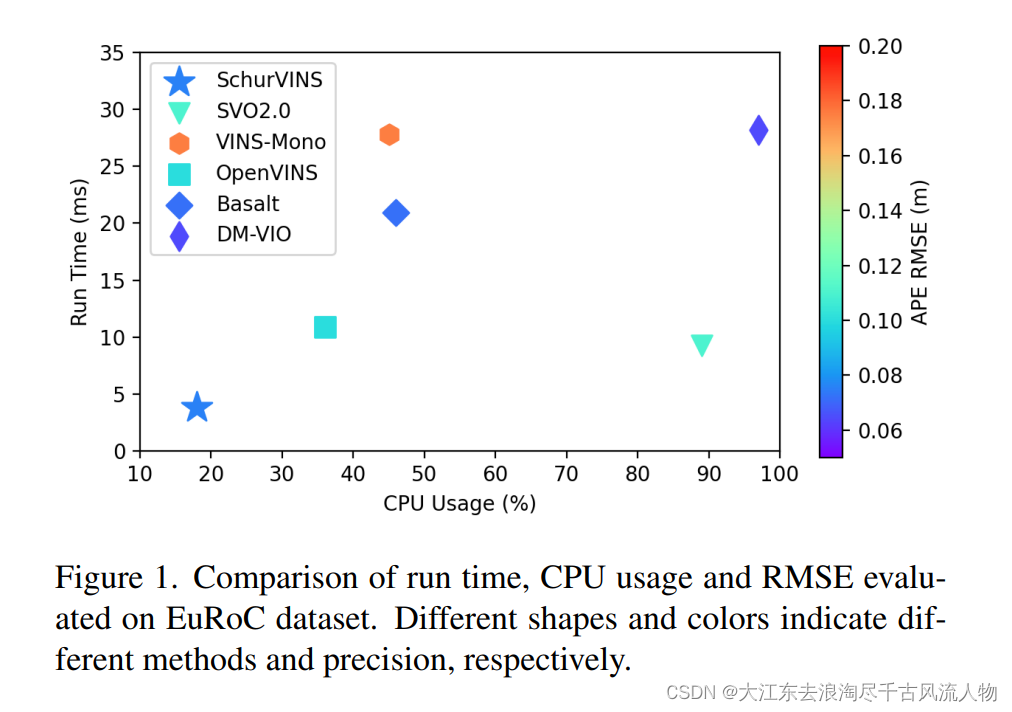
此外,表4和表5中两者的比较也表明,基于EKF的地标求解器和基于GN的地标求解器都能有效、可靠地保证高精度,虽然基于EKF的地标求解器导致精度略有下降,但它可以实现明显较低的计算复杂度。因此很难在资源受限的系统上提供准确的定位,为了解决这个问题,本文提出了SchurVINS,一种基于滤波的视觉惯性系统,综合考量了视觉残差,同时通过Schur操作降低计算复杂度,使得精度和效率的得到了良好的平衡,并在