




- @Castlehe
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
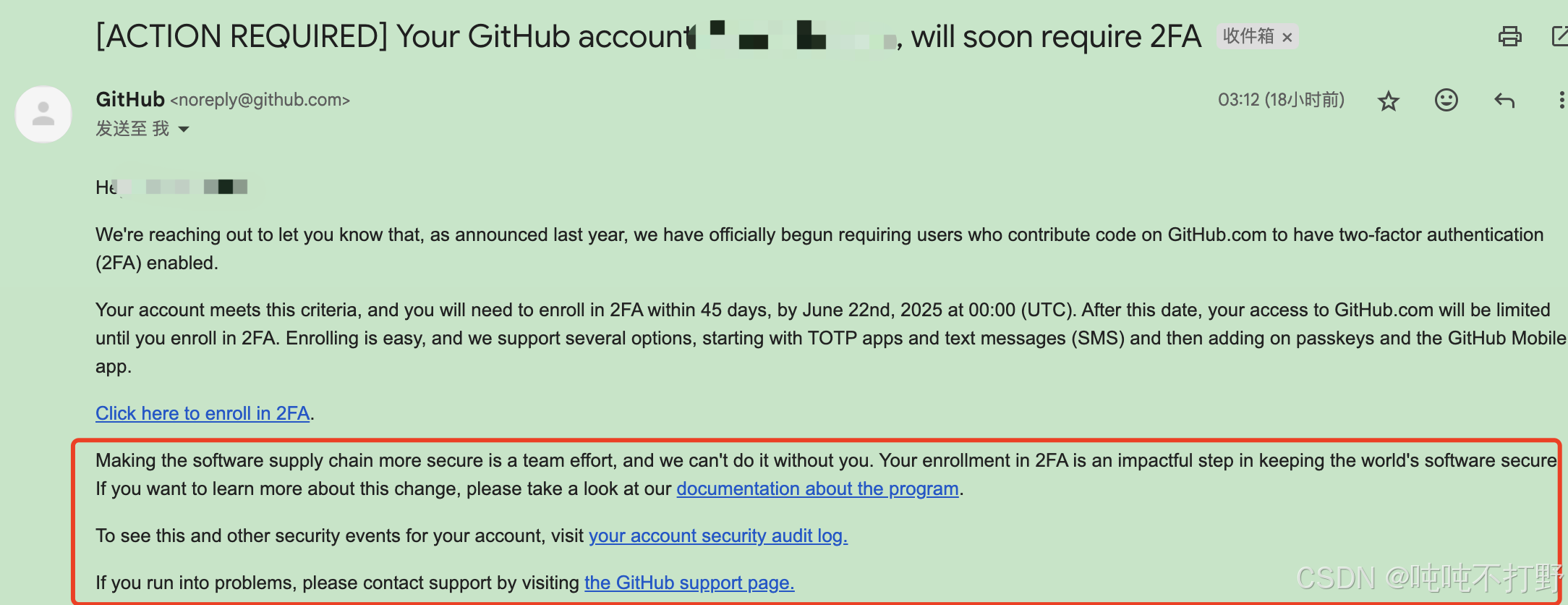
今天突然有一个2FA的提醒,挂在github网站上。点进去。
错误原因vscode安装损坏了,因为默认情况下vscode.markdown-language-features是内置的一个插件也可能是安装了别的什么插件,快捷键冲突了解决方案重装VScode(最简单的,不要瞎折腾了)注意,重装的时候,先将个人用户文件夹中的.vscode文件夹删除,类似:插件删除重新搞是最简单的方式了参考:VSCode: “Markdown Preview” SHIFT-COMM
1. 前置内容1.1 风险警告写在前面——前置风险:这个库并不像PaddleOCR那个库那么流行,维护更新那么及时。这个库——github-AnyQ,最近一次更新时间是2020.11.28。(这个库第一次提交是2018年7月2号,也有可能是因为经过两年的完善,没有更多人试出更多错误。。。)另外根据网上很多安装教程,最好使用docker安装,而且可能会由于gcc等的版本问题,安装失败,还可能会由于网
根据GitBook官方文档-gitignore这里列举几种常见的gitignore写法:# 空行无意义,增加可阅读性## 以#开头的行是注释 如果有需要匹配的内容是#开头的,那么在#前面加上反斜杠转义符,即\#.ipynb_checkpoints/# 不追踪.ipynb_checkpoints这个文件夹下的所有内容**/__pycache__/# 不追踪当前git项目中所有_pycache_文件夹
重度推荐阅读文章:VS Code」Visual Studio Code 菜鸟教程:从入门到精通1. 添加python文件头模板参考:vscode添加python文件头模板正规的叫法是 自定义snippet(代码段) /用户自定义代码段点击 用户->首选项->用户片段,选择对应的语言,例如python,然后会自动打开一个python.json文件,在其中写入以下大致内容即可:{"HEAD
git initgit add .git commit -m "XXX"git pull origin master --allow-unrelated-histories解决error: failed to push some refs to ‘xxxx’
网上有一些关于这个的文章,我参考官方文档的完善了一下,参考:官方文档-4.1 服务器上的 Git - 协议博客园:gitlab两种连接方式:ssh和http配置介绍简书:github上git clone https与ssh的区别(一般的博客都写的是使用区别,一个需要输入用户名密码,另一个不需要。。。官方文档里有偏向原理性的解释)...
参考:用OpenCV调用IP摄像头(python版)这位老哥写的很详细,我就补充一些内容。import cv2import cv2url = "rtsp://admin:admin@192.168.1.88:554/11"cap = cv2.VideoCapture(url)while(cap.isOpened()):ret, frame = cap.read()cv2.imshow('frame
错误信息: gnutls_handshake() failed: The TLS connection was non-properly terminated.配docker的时候,遇到一个很奇怪的问题,gitee上的仓库就可以拉下来,但是github上的就拉不下来想了想,应该是网络方面的问题,搜索后得到的解决方案是:git config --global http.https://github.
这几天在搜索量化交易资源时搜索到了一个github项目,physercoe/awesome-quant,大概样子是下面这样。看到了一个叫awesome的标签,点进去之后发现了许多资源整理类的repo,搜索后发现这个awesome系列是github上比较著名的一种repo。目前可以看到的类似的推荐有:b站文章:【强烈推荐】github上的awesome开源项目知乎专栏文章:GitHub 上的 Awe