




- @CYP_2015
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
它将声学模型、发音词典和语言模型提供的所有信息综合起来,利用复杂的搜索算法(如维特比算法),在庞大的可能性网络中,寻找一条概率最高、最合理的路径,这条路径对应的就是最终的识别结果。本文对语音识别的全链路技术栈进行入门级解读,旨在让读者理解从声音的产生到最终的文本输出,技术层面是一条怎样的链路。职责: 它的任务是将输入的声学特征(如MFCC)匹配到最小的语音单元——“音素 (Phoneme)”。本文
这是当前的业界主流和研究前沿。E2E模型试图将声学模型、发音词典和部分语言模型功能整合进一个单一的深度神经网络中,直接实现从声学特征序列到文本序列的映射,大大简化了传统流程。它将语音视为一个双重随机过程,其底层是不可观测的马尔可夫链(状态序列,通常对应音素),表层是与状态相关的可观测输出(声学特征)。即在给定一个音素状态的条件下,其对应的声学特征向量(如梅尔频率倒谱系数MFCCs)所服从的概率分布
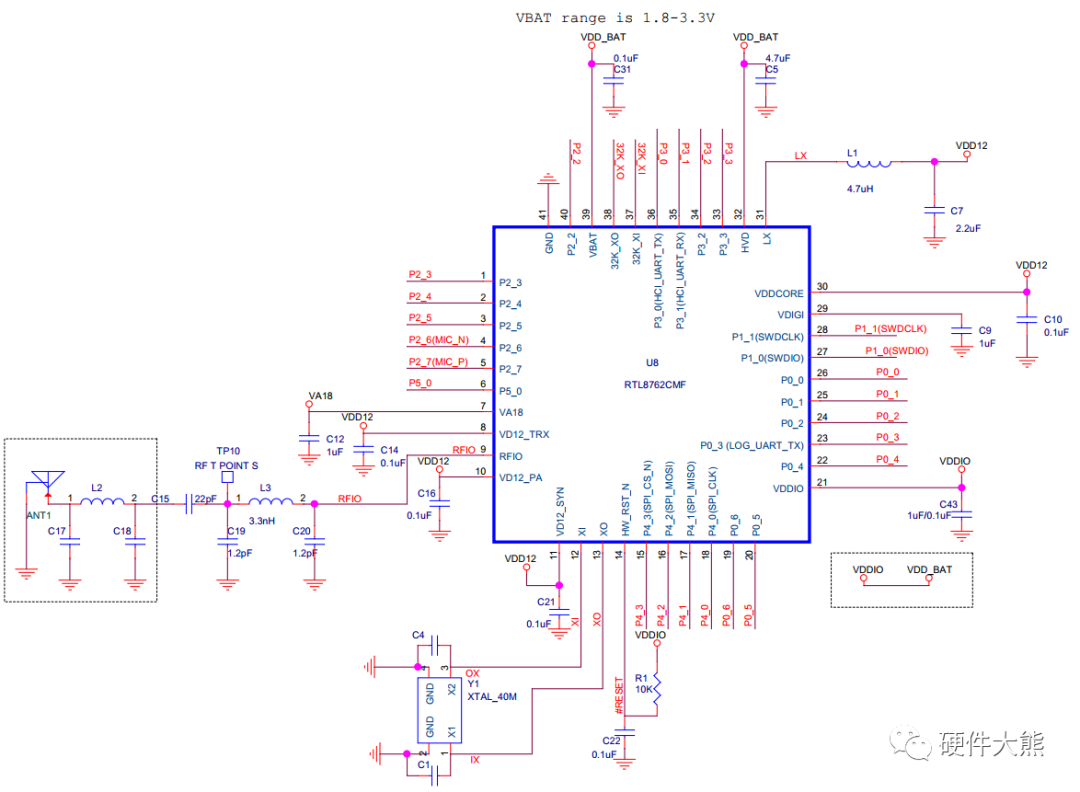
RTL8762C是瑞昱一款超低功耗蓝牙芯片,瑞昱的硬件设计指导书中,关于该芯片的layout设计指导很有普适性的参考指导意义,如下为笔者做过一定简化的芯片最小系统原理图——PCB Layout建议分如下几个点——元件布局顺序按如下顺序布置元件,顺序靠前的元件意味着布局时需要尽量靠近 ICDC/DC 电路元件VBAT bypass 电容RF 电路元件40MHz 晶振RF VDD bypass 电容其
《一款射频芯片的layout设计指导案例-篇章1》中,我们阐述了RTL8762元件布局顺序、DC/DC电路元件布局走线、电源Bypass布局规范、外部flash布局走线、RF布局走线,本篇阐述晶振、ESD、板层等相关指导建议——40MHz晶振布局走线规范在没有结构限制情况下, Crystal 和 BT CHIP 要放在同一层面。为了避免干扰 RF 信号, Crystal 尽量远离 RF Trac.
对于应用工程师,芯片失效分析是最棘手的问题之一。之所以棘手,很无奈的一点便是:芯片失效问题通常是在量产阶段,甚至是出货后才开始被真正意识到,此时可能仅有零零散散的几个失效样品,但这样的比...
对于给定的制造工艺和晶片区域,微控制器的功耗主要取决于两个因素(动态可控):电压和频率。ST公司L系列超低功耗芯片为130nm超低泄漏工艺,在超低功耗所做的设计思路如下:1.围绕Cort...
它将声学模型、发音词典和语言模型提供的所有信息综合起来,利用复杂的搜索算法(如维特比算法),在庞大的可能性网络中,寻找一条概率最高、最合理的路径,这条路径对应的就是最终的识别结果。本文对语音识别的全链路技术栈进行入门级解读,旨在让读者理解从声音的产生到最终的文本输出,技术层面是一条怎样的链路。职责: 它的任务是将输入的声学特征(如MFCC)匹配到最小的语音单元——“音素 (Phoneme)”。本文
这是当前的业界主流和研究前沿。E2E模型试图将声学模型、发音词典和部分语言模型功能整合进一个单一的深度神经网络中,直接实现从声学特征序列到文本序列的映射,大大简化了传统流程。它将语音视为一个双重随机过程,其底层是不可观测的马尔可夫链(状态序列,通常对应音素),表层是与状态相关的可观测输出(声学特征)。即在给定一个音素状态的条件下,其对应的声学特征向量(如梅尔频率倒谱系数MFCCs)所服从的概率分布
它将声学模型、发音词典和语言模型提供的所有信息综合起来,利用复杂的搜索算法(如维特比算法),在庞大的可能性网络中,寻找一条概率最高、最合理的路径,这条路径对应的就是最终的识别结果。本文对语音识别的全链路技术栈进行入门级解读,旨在让读者理解从声音的产生到最终的文本输出,技术层面是一条怎样的链路。职责: 它的任务是将输入的声学特征(如MFCC)匹配到最小的语音单元——“音素 (Phoneme)”。本文
毫米波雷达、AI摄像头、端侧大模型等技术将深度融合,让系统能够通过感知人的位置、姿态、表情甚至语气,来预判你的意图,主动提供服务。Matter协议的普及是大势所趋。它是由亚马逊、谷歌、苹果这三家昔日的死对头,联合CSA连接标准联盟(前身为Zigbee联盟)共同推出的一个全新的、统一的、开源的智能家居连接标准。这意味着,你未来可以用苹果的Siri去控制小米的灯,用华为的智慧生活App去联动美的的空调