




- @Blankit1
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
注意:^M的输入方式是 Ctrl + v ,然后Ctrl + M。

语言幻觉”是一种不基于感官输入的感知,而“视觉幻觉”是对正确感官输入的误解文章中设计了一系列的能表现语言幻觉和视觉幻觉的实验,共200对图像-问题-答案对。包括表格、地图、海报、视频帧等,以及修改后的图片,这些修改的图片只有小幅的修改,但是对于同一问题的答案是完全不同的。这些实验分为两大类视觉依赖型和视觉辅助型。视觉依赖型的问题的答案与图片的内容强相关(比如:图片的左上角是什么?)视觉补充型是一些

在docker中运行时,由于配置的共享内存不足导致。新建docker时,
在选择图片中不存在的物品时,有3种方式“Random Sampling”、“Popular Sampling”和“Adversarial Sampling”。即,LVLM(Large Vision-Language Models)倾向于生成与描述中的目标图像不一致的对象。这篇文章主要是评价视觉-语言模型中出现“幻觉”的评价。(POPE,基于轮询的对象探测评估)。

Pillow是一个强大的图像处理库,可以方便地读取、处理和保存图像。
转自https://blog.csdn.net/coding_sun/article/details/78975486安装tensorflow时,如果使用直接安装速度相对较慢,采取清华大学的镜像会提高速度。GPU版本安装方法:pip install tensorflow-gpu==1.8 -i https://pypi.tuna.tsinghua.edu.cn/simple或pip install
一、tesorflow基本概念二、计算图一个机器学习任务的核心是模型的定义以及模型的参数求解方式,对这两者进行抽象之后,可以确定一个唯一的计算逻辑,将这个逻辑用图表示,称之为计算图。计算图表现为有向无环图,定义了数据的流转方式,数据的计算方式,以及各种计算之间的相互依赖关系等三、操作3.1 运算操作定义类操作的类型,以及参与运算的数据的类型3.2 tensorflow中的运算符变量运算指的是ele
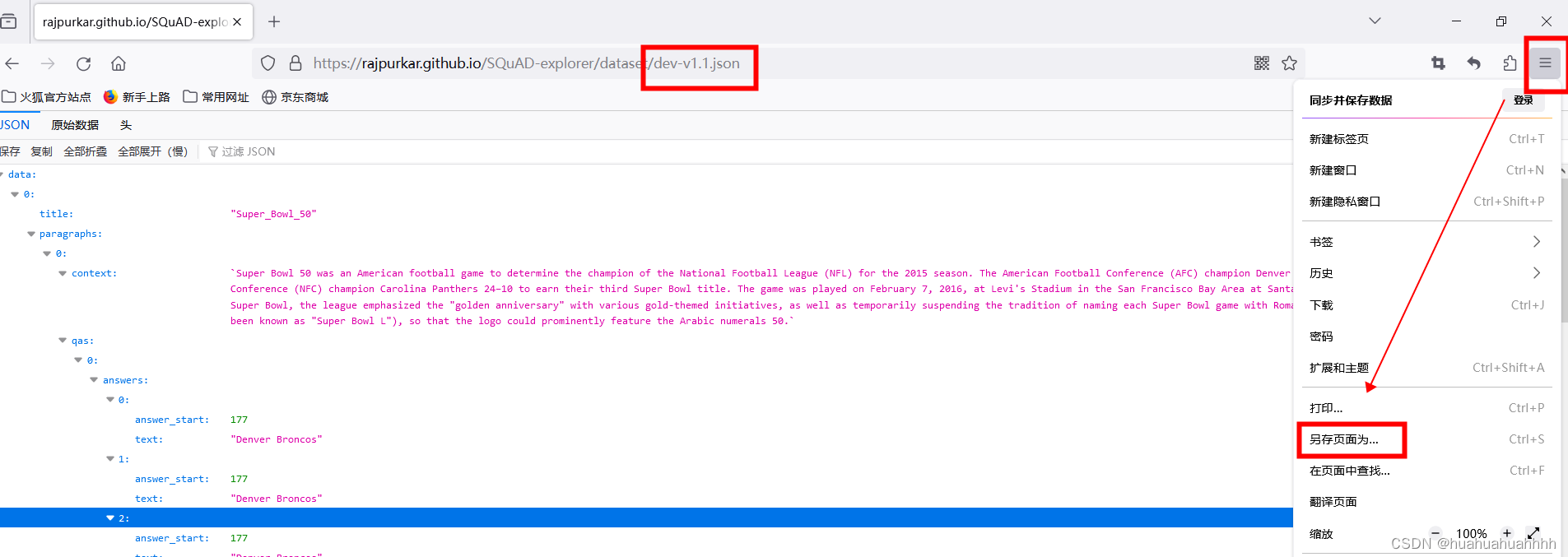
点击右边的三条横线——>另存页面为。
调用示例可以看到传参是什么,立即体验中提供了怎么请求的代码。中找到自己需要的模型,分别点。这里是多模态的传参示例。

BCE loss pytorch官网链接BCE loss:Binary Cross Entropy Losspytorch中调用如下。设置weight,使得不同类别的损失权值不同。其中x是预测值,取值范围(0,1), target是标签,取值为0或1.在Retinanet的分类部分最后一层的激活函数用的是sigmoid,损失函数是BCE loss.BCE loss可以对单个类别进行求损失,配合si