- @Andius
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
ONNX(Open Neural Network Exchange)本质上是一种模型的中间表示格式(IR),类似于编译器里的 LLVM IR。用 PyTorch 训练完一个模型之后,模型的计算逻辑是用 Python 描述的,跑推理的时候要经过 Python 解释器、PyTorch 的调度器、再到底层的 CUDA kernel。这条链路很长,开销不小。
简单说:V1是baseline,V2针对键盘敲击这类突发噪声做了优化,V3改成了因果模型可以实时跑。

我们知道FFT需要使用蝶式的方式计算,但是实际上,我们在开发音频的过程中,所有的数字都是实数,所以可能我们并不需要使用到这么多的计算次数,就可以实现FFT,具体做法接下来我会给出推导和证明。

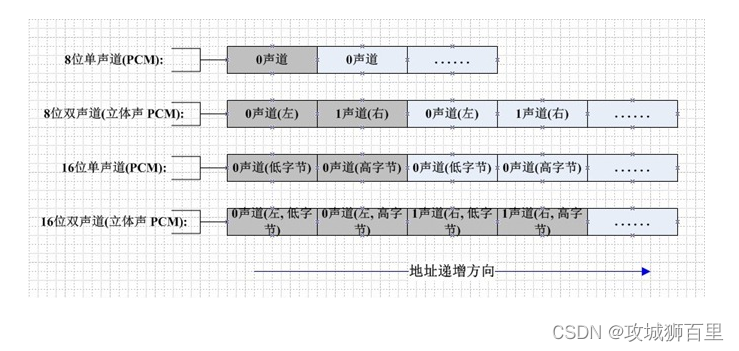
PCM(Pulse Code Modulation)也被称为脉冲编码调制。PCM音频数据是未经压缩的音频采样数据裸流,它是由模拟信号经过采样、量化、编码转换成的标准的数字音频数据。
最近在尝试把WebRtc的NoiseSuppressor模块移植到嵌入式平台,现在已经移植了,尝试了下效果,降噪效果很显著,噪声带被显著抑制了。

我们需要读取两部分数据,分别是训练集和评估集,这两个集是分开的首先我们需要进行一个预处理部分:# 对读入的图像数据进行预处理# 将图片尺寸缩放道 224x224# 读入的图像数据格式是[H, W, C]# 使用转置操作将其变成[C, H, W]# 将数据范围调整到[-1.0, 1.0]之间return img定义一个训练集数据读取器类似之前的,我们需要将训练集划分batch,还需要将其打乱进行。至

我们之前用的是均方差作为我们神经网络的损失函数评估值,但是我们对于结果,比如给定你一张应该是0的照片,它识别成了6,这个时候这个均方差表达了什么特别的含义吗?显然你识别成6并不代表它比识别成1的情况误差更大。所以说我们需要一种全新的方式,基于概率的方案来对结果进行规范。也就是我们说的交叉熵损失函数。

图像分类是根据图像的语义信息对不同类别图像进行区分,是计算机视觉的核心,是物体检测、图像分割、物体跟踪、行为分析、人脸识别等其他高层次视觉任务的基础。图像分类在许多领域都有着广泛的应用,如:安防领域的人脸识别和智能视频分析等,交通领域的交通场景识别,互联网领域基于内容的图像检索和相册自动归类,医学领域的图像识别等。这里简单讲讲LeNet我的推荐是可以看看这个视频,可视化的查看卷积神经网络是如何一层
这里实际上涉及到了挺多有关有关理论的东西,可以详细看一下paddle的官方文档。不过我这里不过多的谈有关理论的东西。在代码中,我们实际上是用不同的卷积核来造成不同的影响,我这里也是paddle中对于卷积核的几个比较简单的应用。实际上你也可以理解成通过卷积算子对图像进行了处理,而输出的参数矩阵也就是卷积核,卷积核会决定对图像的处理结果。卷积核对图像造成的影响可以参考上方常见卷积核汇总。飞桨卷积算子对
大伙既然都来做这个了,那配个CUDA环境肯定是必不可少的了吧(笑)最前面的最前面,