- @ARYAD
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
一般情况来说,我们通过收集数据,训练深度学习模型,通过反向传播求导更新模型的参数,得到一个契合数据和任务的模型。这一阶段,通常使用python&pytorch进行模型的训练得到pth等类型文件。AI模型部署就是将在python环境中训练的模型参数放到需要部署的硬件环境中去跑,比如云平台和其他cpu、gpu设备中。一般来说,权重信息以及权重分布基本不会变(可能会改变精度、也可能会合并一些权重)。该部

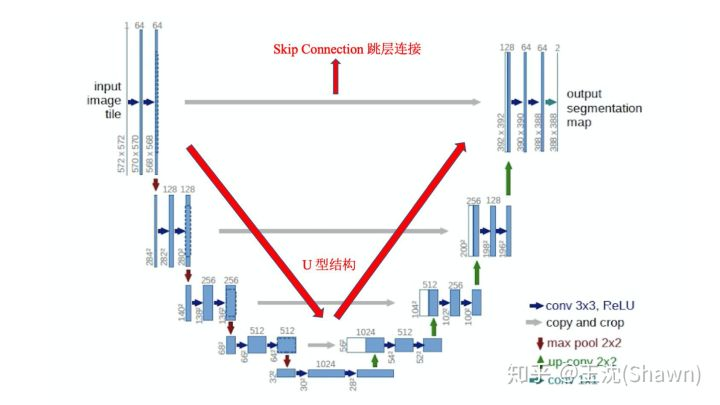
根据UNet的结构,它能够结合底层和高层的信息。底层(深层)信息:经过多次下采样后的低分辨率信息。能够提供分割目标在整个图像中上下文语义信息,可理解为反应目标和它的环境之间关系的特征。这个特征有助于物体的类别判断(所以分类问题通常只需要低分辨率/深层信息,不涉及多尺度融合)高层(浅层)信息:UNet共进行了4次上采样,并在同一个stage使用了skip connection,而不是直接在高级语义特
pytorch跑Unet代码,gpu利用率在0%-20%闪现,主要问题是GPU一直在等cpu处理的数据传输过去。利用top查看cup的利用率也是从0省道100%且显然cup的线程并不多,能处理出的数据也不多。在一般的程序中,除了加载从dataloader中数据和model的运行需要gpu,其余更多的dataset、dataloader、loss的计算和日志的输出很多部分都需要cup的计算。所以,可

1.准确率ACC:overall:准确率是分类正确的样本占总样本个数的比例,即其中, ncorrect为被正确分类的样本个数, ntotal为总样本个数。结合上面的混淆矩阵,公式还可以这样写:y_pred = [0, 2, 1, 3]y_true = [0, 1, 2, 3]print(accuracy_score(y_true, y_pred))# 0.5print(accuracy_sco
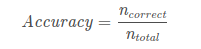
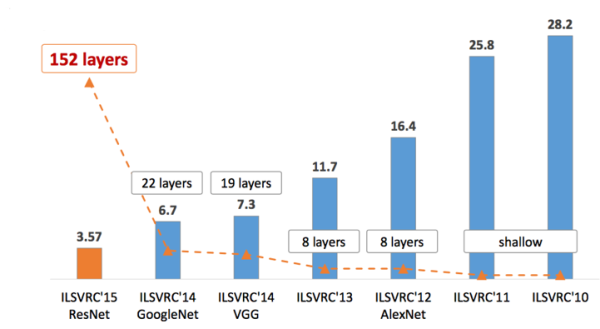
作者:我爱机器学习链接:https://zhuanlan.zhihu.com/p/22094600来源:知乎著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。CNN的发展史上一篇回顾讲的是2006年Hinton他们的Science Paper,当时提到,2006年虽然Deep Learning的概念被提出来了,但是学术界的大家还是表示不服。当时有流传的段子是Hinton的学生在台