




- @AMWICD
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
主要是MultiScaleDeformableAttention包,如果中途换了torch版本,需要重新编译cuda,得到一个新的这个包,不然报错。下载链接:https://download.csdn.net/download/u010826850/21980492。deformable-detr 也是需要一个背景类,num_class+1。python test.py (我没运行这一步)r50上
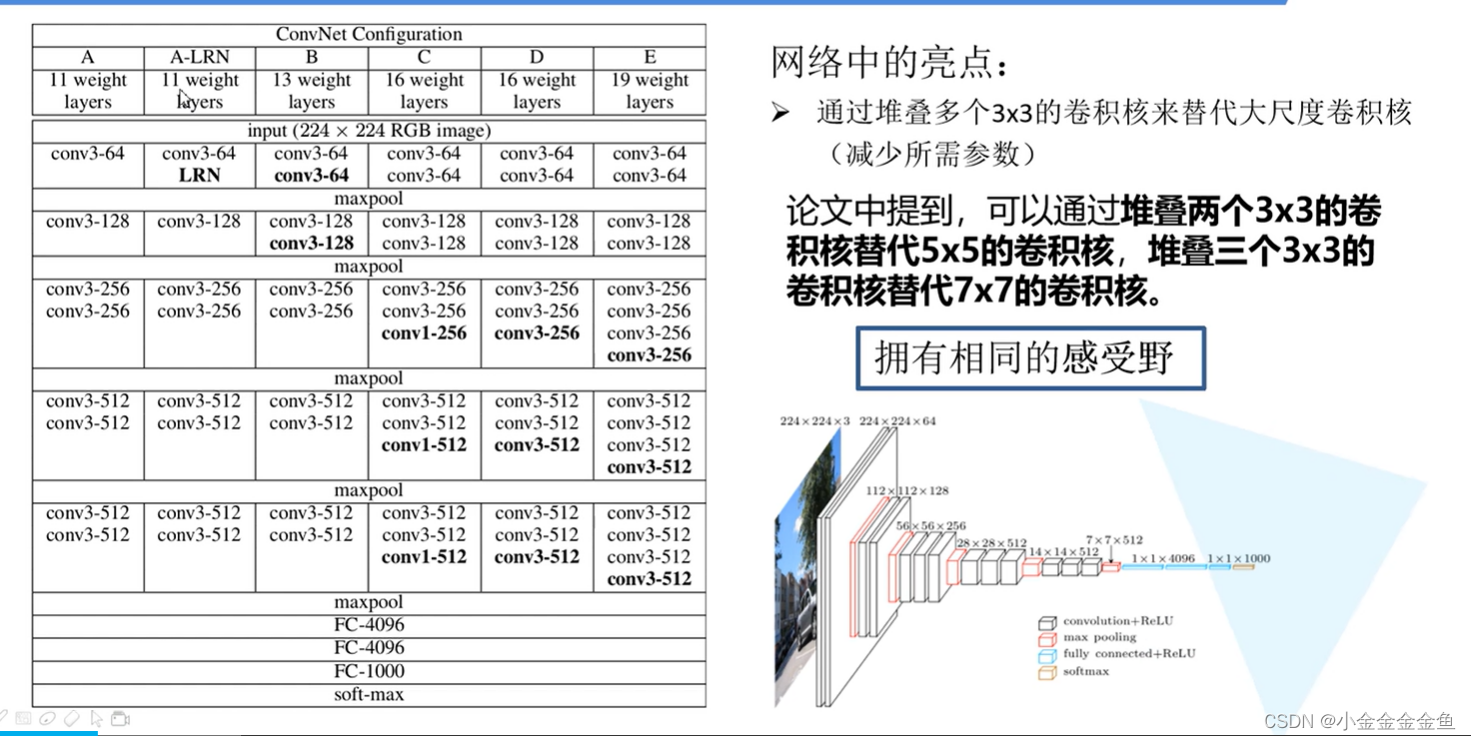
采用多个小的卷积核进行堆叠,得到的感受野大小相同,这可以去替代一个大的卷积核,可以节省网络的训练参数的个数。如果是基于迁移学习的方式使用再训练的话,则就要减去这三个值。因为预训练的模型是基于ImageNet训练的。模型比较大,但是这里的flowers数据集比较小,没法充分训练,这里不运行了。但此处的网络没有这么操作,因为是从头开始训练的。跟之前的AlexNet网络的预测过程是一样的。其余的跟Ale
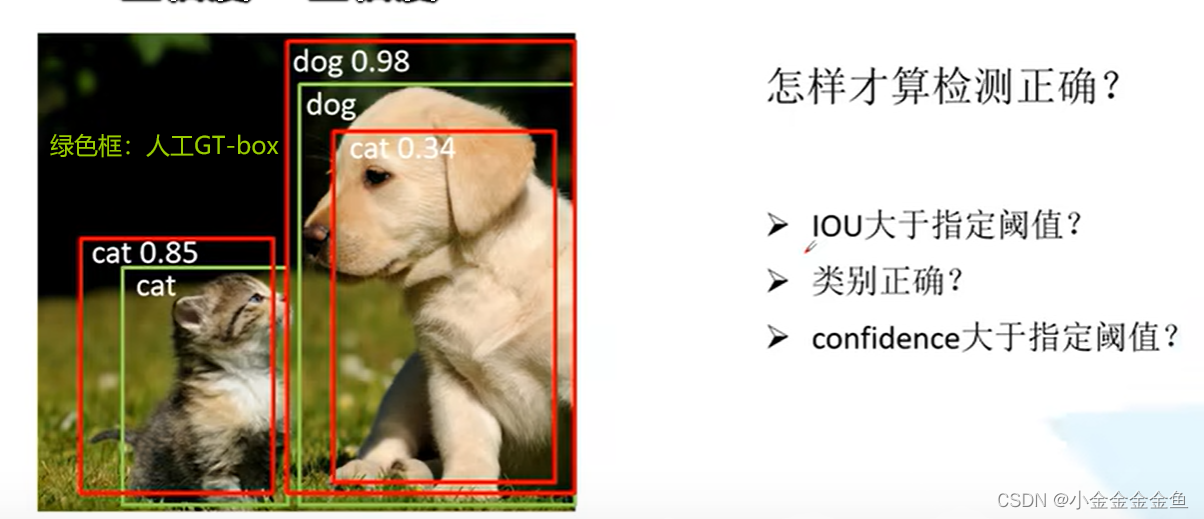
若一个 GT 有多个预测边框,则认为 IOU 最大且大于等于 0.5 的预测框标记为 TP,其他的标记为 FP,即一个 GT 只能有一个预测框标记为 TP。FN就是 把检测对象检测为背景的 那些检测框 的数量,也就是一些被检测错误(F)为负样本(N)的样本,它们本来应该被检测为正样本。因为预测的两个边界框预测的目标都是第一只猫,所以ID都是1,预测给出的数值是置信度,不是IOU,IOU是预测框与真
transform 主要是对input图像进行变换(统一尺寸、对图像中的数据进行类的转换)TensorBoard,虽然他是TensorFlow 的一部分,但是可以独立安装,并且服务于Pytorch等其他的框架。安装tensorboard但是这里tensorboard版本太低了,以下方法解决↓在pip list查看将tensorboard的事件文件放在logs文件夹里面。
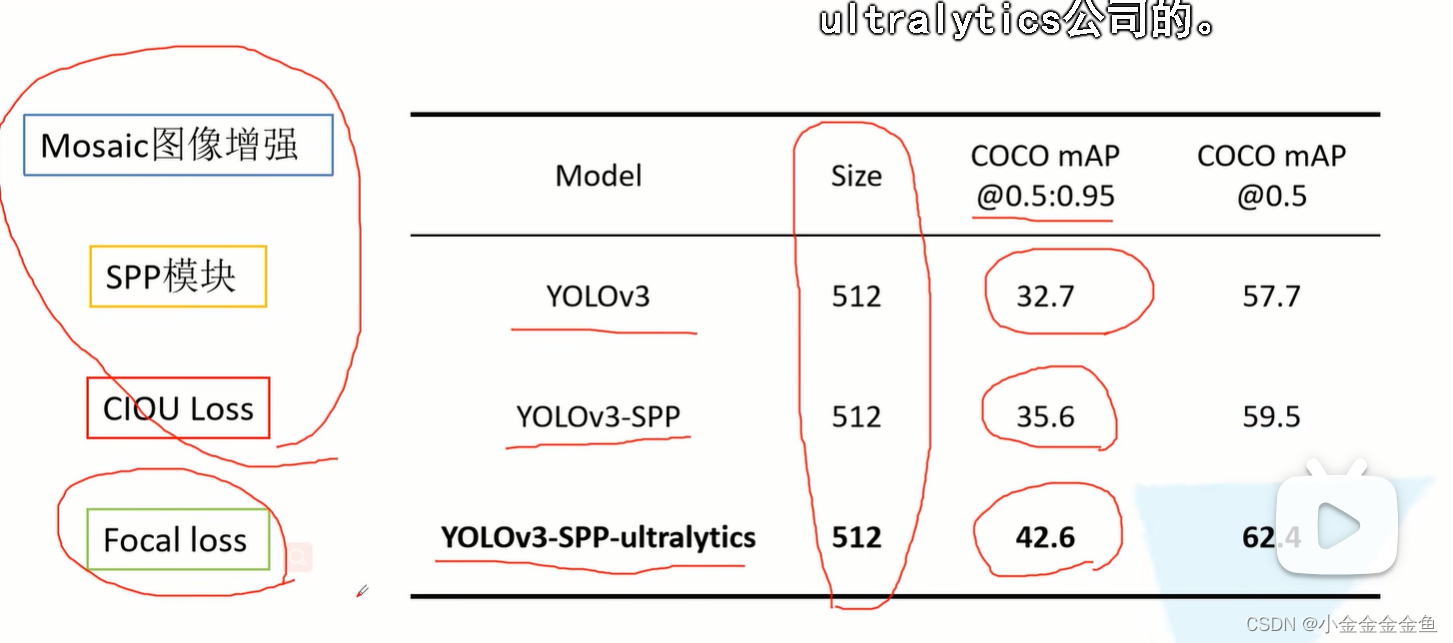
up在yolo3代码的基础上进行修改,并简化了训练过程(移除了一些效果不大的trick)原作者文档中写了如何去训练自己的数据集:1.首先将数据标注成Darknet format(yolo格式)每个txt文件就对应一张图片的信息,每一行表示一个目标。第一个数字:目标索引(如0:人类)后四个数字:目标边界框的相对坐标2.创建txt文件:train.txt文件和test.txt文件。txt文件中存储的是
假设这个train文件夹里面只有ants_image和bees_image。用图片名字命名txt文件,内容是这个图片的分类。可以看到这段代码成功地从数据集里面取出了图片。只以ant为例,bee的就是把这个改改。因为图片太多了,所以用代码自动添加。
师兄说学目标检测之前先学分类坏了,内容好多!学学学感谢up主,好人一生平安什么是混淆矩阵:横坐标:每一列属于该类的所有验证样本。每一列所有元素对应真实类别。纵坐标:网络的预测类别。每一行对应预测结果属于该类的所有样本。对角线:预测正确的样本个数。预测值在对角线上分布的越密集,模型的性能就越好。还能通过混淆矩阵看到这个网络对哪些类别更容易分类出错。混淆矩阵的指标:精确率precision不等于准确率

先略,等我听懂之后再写参考pytorch样例。

主要是MultiScaleDeformableAttention包,如果中途换了torch版本,需要重新编译cuda,得到一个新的这个包,不然报错。下载链接:https://download.csdn.net/download/u010826850/21980492。deformable-detr 也是需要一个背景类,num_class+1。python test.py (我没运行这一步)r50上
目标检测和图像分割挺像。有人把这两个结合,做出了不错的效果。pytorch.org 但是中文文档版本比较老所需环境。
