- @2401_86953848
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
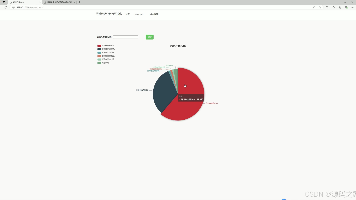
本文介绍了一个基于Python的中药材数据分析系统,采用Django框架和MySQL数据库构建。系统通过requests爬虫从中药材天地网采集数据,提供产地占比饼图、词云图、价格柱状图、成分极坐标图、历史价格折线图等可视化分析功能。后台支持药方数据管理,包含搜索、新增、删除和导出操作,并设有注册登录模块保障系统安全。核心代码展示了数据采集过程,包括产品ID获取和药方信息提取。该系统解决了中药材数据
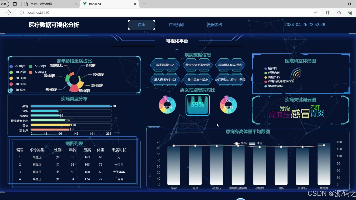
本文介绍了一个基于Python、MySQL、Flask和Vue的医疗数据分析系统。系统包含四大功能模块:1)可视化大屏展示各年龄段患病占比、疾病分布等图表;2)基于随机森林算法的疾病预测功能;3)病例数据表格展示与管理;4)后台数据维护模块。核心技术包括使用jieba分词、TF-IDF特征提取和随机森林分类算法实现病情预测,并通过Flask提供API接口,Vue实现前端交互。系统旨在提升医疗数据整
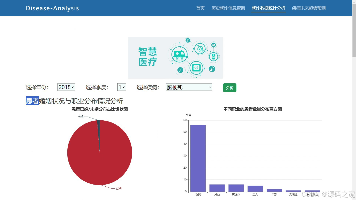
本文介绍了一个基于Python和Flask框架开发的医疗数据分析与预测系统。系统整合了Echarts可视化技术和ARIMA预测算法,主要功能包括:1)历史就诊信息查询;2)多维度统计分析(患者婚姻状况、职业分布、住院天数、年龄分布等);3)疾病发展趋势预测(年龄趋势、已婚率趋势、住院天数趋势)。系统通过交互式图表直观展示医疗数据特征,并利用ARIMA模型对未来趋势进行预测,为医院管理决策提供数据支
技术栈:Python语言、Flask框架、知识图谱、机器学习、智能医疗问答、数据库医疗问答模块医疗查询模块反馈建议模块医疗问答咨询记录模块数据可视化模块注册登录模块后台管理模块项目介绍:该系统集成了Python、Flask、知识图谱与机器学习技术,构建了一个智能化的在线医疗服务平台。用户可通过自然语言与系统交互,获得基于知识图谱的专业医疗回答。
本文介绍了一个基于知识图谱的医疗智能问答系统。该系统采用Python+Django/Flask框架,结合Neo4j图数据库存储医疗实体关系,并运用BERT模型实现智能问答。主要功能包括:知识图谱可视化展示疾病、药品等实体关联;对话式智能问答交互;问答记录管理;用户信息查看;数据统计分析(通过ECharts展示每日问答量趋势)以及后台运维管理。系统实现了医疗知识的智能查询、可视化呈现和全流程管理,为
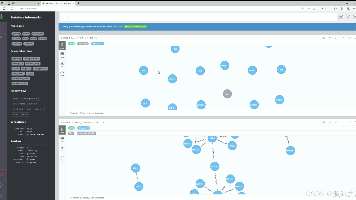
本文介绍了一个基于Python Flask框架的医疗数据可视化系统。系统采用Echarts实现数据可视化,包含六大功能模块:首页数据概览、患者信息管理、医疗数据可视化、患者信息添加、医疗工作安排和疾病关联分析。核心功能包括通过图表展示患者数据趋势、表格管理患者信息、日历管理医疗事务以及关系网络分析疾病关联。系统后端使用Flask处理请求,前端结合HTML和Echarts实现交互式可视化,旨在帮助医
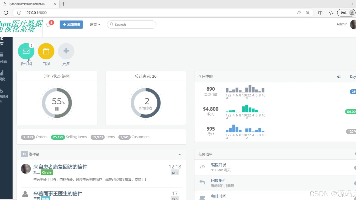
本文介绍了一个基于知识图谱的医疗智能问答系统,采用Python+Django框架开发,结合Neo4j图数据库存储医疗知识图谱。系统核心功能包括:1)知识图谱可视化模块,展示疾病、症状等实体关联;2)医疗问答交互模块,通过Bert模型实现自然语言理解;3)词云分析模块呈现高频医疗关键词;4)问答信息管理模块支持记录维护。项目整合深度学习与知识图谱技术,为医疗领域提供智能问答解决方案,实现疾病症状查询
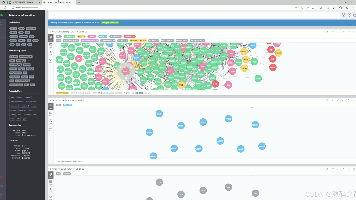
本文介绍了一个基于Python与Flask开发的交通大数据分析与预测系统。系统采用Vue前端框架和Echarts可视化库,通过requests爬虫技术采集MetroDB网站的城市交通与地铁客流数据,存储于MySQL数据库。主要功能包括:首页仪表盘展示核心指标与全局数据总览;交通与地铁数据分析模块支持多维度筛选查询;预测模块融合ARIMA和LSTM算法生成未来一周趋势预测;模型对比模块评估不同算法性
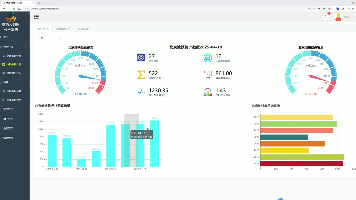
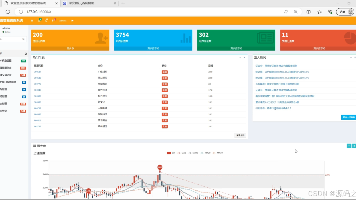
摘要:本文介绍了一个基于Django框架的股票交易管理可视化系统。系统采用Python语言开发,使用tushare模块和requests爬虫获取实时股票数据,并通过Echarts实现数据可视化展示。主要功能包括:上证指数K线分析、股票信息管理、交易记录管理、新闻资讯管理、用户评论管理等模块。系统提供数据采集、业务处理和可视化分析的一体化解决方案,支持管理员进行股票数据维护、交易记录查看、新闻发布与
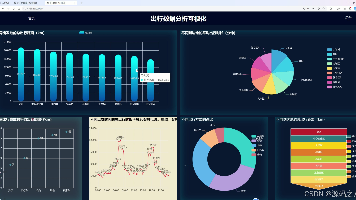
本文介绍了基于Django框架的城市居民出行模式可视化系统。系统采用Python 3.x、MySQL、ECharts等技术栈,集成K-Means聚类和随机森林算法实现出行模式分析与预测。主要功能包括用户管理、多维度数据可视化(柱状图、饼图等)、出行预测、数据管理等模块。系统界面展示了大屏可视化、数据分析、预测结果等页面,支持从出发地、出行方式等多维度分析出行数据。核心代码实现了数据预处理、特征工程