




- @2401_85773741
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
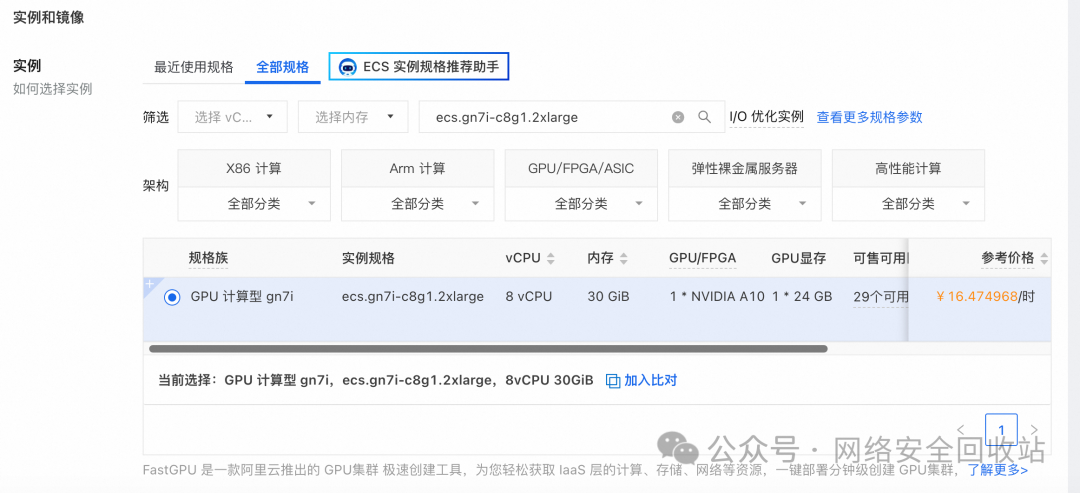
Ollama 是一个强大的本地大模型推理平台,支持用户通过命令行、HTTP API 和 OpenAI 客户端进行多样化的模型调用。通过合理配置环境变量和优化推理流程,Ollama 能够为用户提供高效的本地化推理解决方案。无论是在隐私敏感的本地化环境中,还是需要高性能的大规模推理任务,Ollama 都是一个理想的选择。

随着自然语言处理技术的飞速发展,预训练语言模型已成为推动各种NLP任务进步的关键力量。对于我们每一个普通用户或者作为个人兴趣的开发者来说,从0开始训练一个大规模语言模型无疑是一件十分困难的事。那么我们是否有机会接触到真正的大模型训练呢?答案是有的,利用当下丰富的开源的预训练大模型资源,通过LoRA微调等技术,我们可以对现有的预训练大模型进行特定方向的调整。如果你也想经过微调训练出自己的“定制款”大

本文介绍了使用LLaMA Factory进行微调的步骤,包括环境搭建、数据准备、参数配置、训练和效果评估等,最终成功微调模型并使用Ollama部署,提升了模型表现,达到了预期的效果。有一点感受是跟之前接触的安全实验不太一样:大多数的安全实验都是我打了这个Payload,就一定会出现确定的结果,不管是弹计算器还是反弹Shell,一切都是确定的。而大模型的训练往往充满了玄学成分,可能需要多实验几次才知
生成式人工智能ChatGPT自从2023年初,ChatGPT在全球爆火,从那开始,就好像是人工智能的奇点时刻,刚开始人们只在新闻上见识到ChatGPT的厉害之处,到现在和ChatGPT差不多的大语言模型(豆包、Kimi、Deepseek等)已经完全属于平民老百姓的日常消费品。就和当年的互联网一般,从少数的使用扩散到大众的使用,最终大语言模型这类的生成式人工智能就会和互联网一样,成为工作生活中不可缺

为了理解什么是集成学习算法,首先,你需要知道什么是集成学习。集成学习是一种同时使用多个模型,以达到比使用单一模型更好的性能的方法。从概念上讲,可以参考下面这个比喻:!我们向一个班里的学生提出一个数学问题。他们有两种解答方式:合作解答和单人解答。生活经验告诉我们,如果全班同学一起合作,那么学生之间可以互相检查,协作解决问题,并最终给出一个唯一的答案。然而单人作答就没有这种检查的福利了——即使他/她的

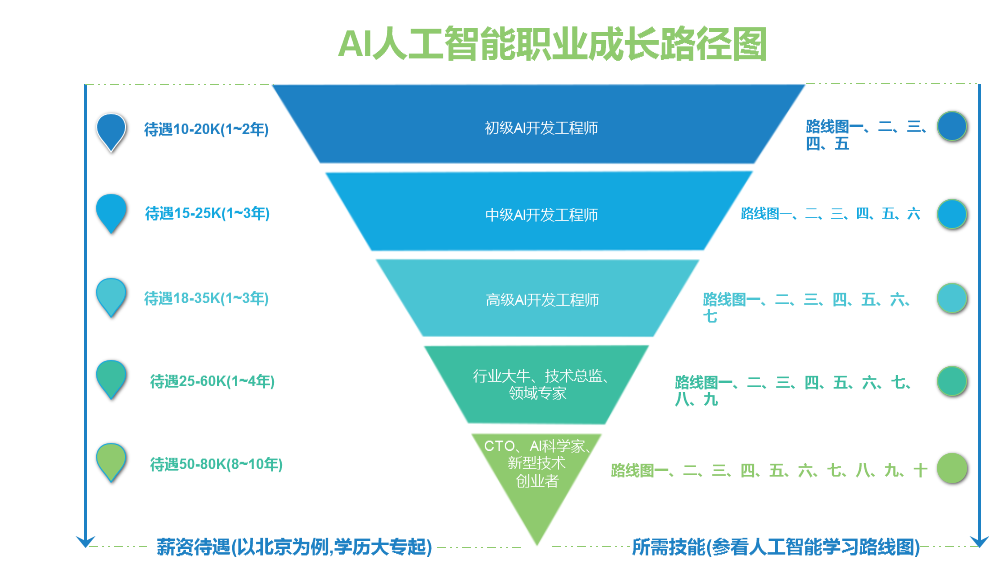
为了让自学者们得到更贴合市场、更权威的AI人工智能学习资料,我向黑马申请到了很多新视频,很骄傲能给广大自学者提供一个这样优秀的学习资源(偷笑)。不用理解我整理的辛苦,不用理解我整理时累的眼角都流哈喇子了,大家觉得有用,拿去就是完整视频:http://yun.itheima.com/course/781.html?2010stt配套资料:https://pan.baidu.com/s/1mOt1xf
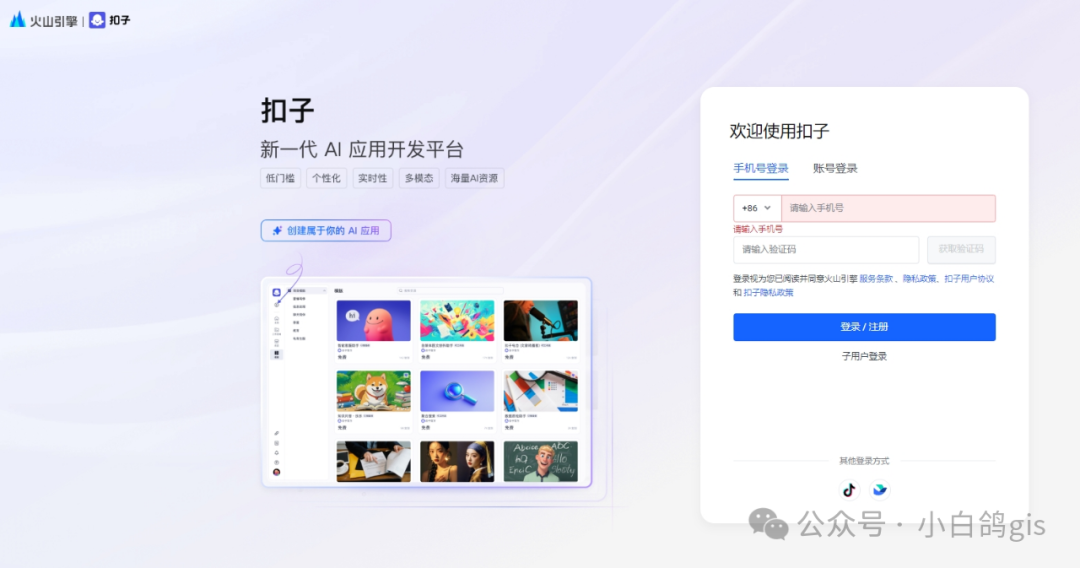
本期为大家介绍如何搭建自己的智能体,本期用到的工具是扣子(Coze),Coze 是一个由字节跳动推出的 AI 开发平台,主要用于快速构建、调试和部署基于人工智能的对话机器人(Bot)和智能体(Agent)。它类似于其他低代码/无代码 AI 平台,但更注重灵活性和扩展性,支持用户通过可视化工具或代码深度定制 AI 应用。本期将演示如何通过Coze搭建地址标准化智能体,内容具体包括:注册Coze、以及
为了让自学者们得到更贴合市场、更权威的AI人工智能学习资料,我向黑马申请到了很多新视频,很骄傲能给广大自学者提供一个这样优秀的学习资源(偷笑)。不用理解我整理的辛苦,不用理解我整理时累的眼角都流哈喇子了,大家觉得有用,拿去就是完整视频:http://yun.itheima.com/course/781.html?2010stt配套资料:https://pan.baidu.com/s/1mOt1xf
最近,深度学习的研究中出现了许多大型预训练模型,例如 GPT-3、ChatGPT、GPT4、ChatGLM-130B 等,这些模型可以在多种自然语言处理任务中取得优异的性能表现。而其中,ChatGPT 模型因为在对话生成方面的表现而备受瞩目,成为了自然语言处理领域的热门研究方向。然而,这些大型预训练模型的训练成本非常高昂,需要庞大的计算资源和大量的数据,一般人难以承受。这也导致了一些研究人员难以重
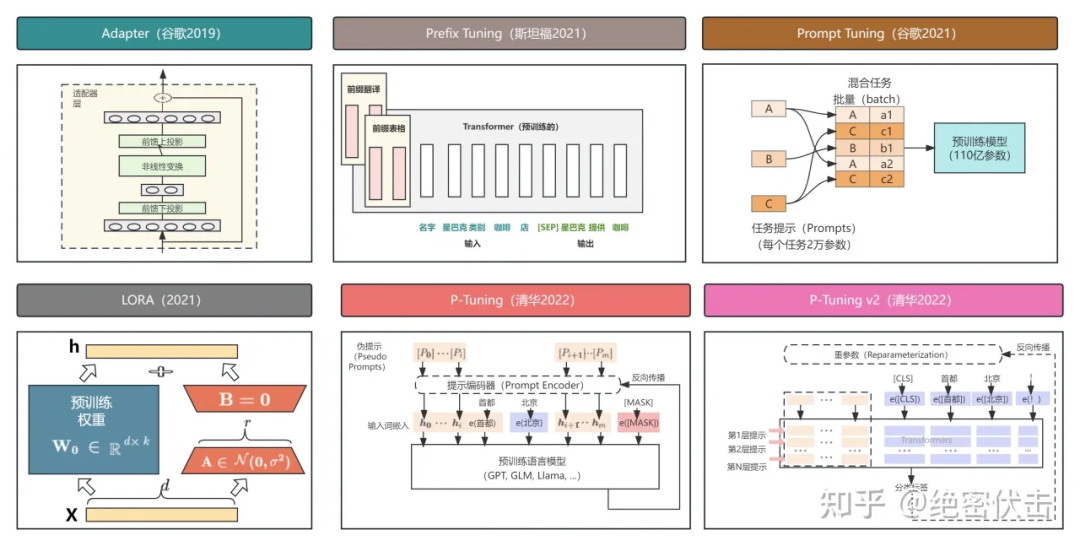
随着人工智能技术的迅猛发展,AI大模型成为了当前最热门的技术领域之一。很多人对AI大模型既充满好奇又感到陌生,特别是对于那些完全没有编程基础的人来说,从零开始学习AI大模型似乎是一项艰巨的任务。但实际上,只要有足够的决心和正确的方法,任何人都有可能成为AI大模型领域的专家。本文将探讨从零基础学习AI大模型需要多长时间,以及如何确保你能够真正学会。
