




- @2401_85379281
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本文介绍了如何在个人电脑上搭建AI智能体平台Dify,支持自定义聊天机器人、智能体设计、工作流编排等功能。Dify是一个开源LLM应用开发平台,具有模型编排、RAG管道、Agent框架等核心功能,可快速构建生成式AI应用。部署过程包括安装Docker、获取Dify源码、启动服务等步骤。文章还探讨了智能体的必要性,指出多模型协同能突破单一AI的局限,并通过360AI助手等案例说明智能体在行业中的应用
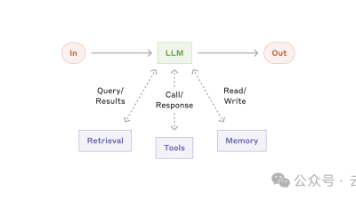
本文介绍了AI智能体(Agent)和工作流(Workflow)的开发经验。文章指出,最成功的实现往往采用简单、可组合的模式而非复杂框架。AI智能体能够自主调用工具完成任务,而工作流则通过预设指令实现可预测性。作者建议根据任务复杂度选择方案:简单任务可优化LLM调用,固定流程用工作流,动态决策场景用智能体。文章还介绍了链式提示、路由和并行化等常见工作流模式,强调理解底层代码比依赖框架更重要。最后指出
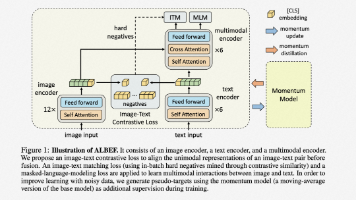
多模态大型语言模型(MLLM)结合大型语言模型与视觉模型,通过模态编码器、LLM和多模态接口处理多种输入信息。文章详细介绍了MLLM的基本结构、不同类型的模态编码器(如EVA-CLIP、ConvNext-L)及其优化策略,探讨了模型评估方法和幻觉问题缓解技术。同时概述了从基础到进阶的大模型学习路线,涵盖系统设计、提示词工程、平台应用开发、知识库应用、微调开发以及多模态应用等方面,为开发者提供了全面
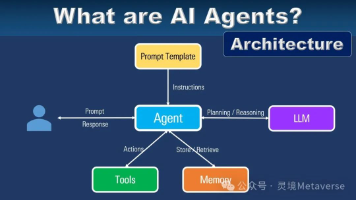
有粉丝后台私信问想了解到底什么是AI Agent?在这一波AI浪潮中,有两个词汇被频繁提及,它们分别是「AI大模型」和「AI Agent」。接下来我将用生动的比喻和贴近生活的例子,帮助AI零基础用户轻松理解这两个概念,并了解它们之间的关系。
这不是个例。2025年的招聘市场,一个显著趋势是:精通大模型应用的Java工程师正成为各大厂争抢的稀缺资源。脉脉高聘报告显示,AI相关岗位占据高薪TOP10的半壁江山,而其中,能实现大模型与企业现有庞大Java体系无缝对接的开发者,薪资更是水涨船高。

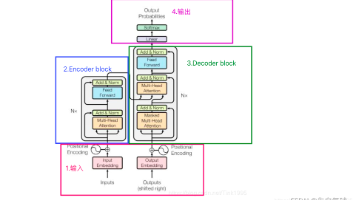
Transformer是现代大语言模型的基石架构,通过自注意力机制解决了RNN的并行计算和长期依赖问题。文章详细解析了编码器-解码器结构、自注意力、多头注意力、残差连接等核心组件,并通过数据流动展示了信息如何在各层间传递,帮助读者理解这一革命性架构如何实现高效并行和上下文理解,从而支撑起像ChatGPT这样的大模型。
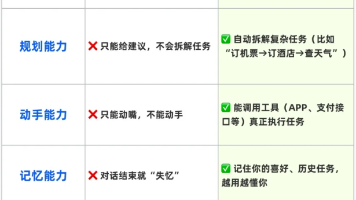
文章详解了AI Agent与传统大模型的区别,强调Agent不仅具备思考能力,还能自主执行任务。介绍了Agent的四大核心模块:大脑(LLM大模型)、记忆库、规划引擎和工具箱,以及四大核心能力:感知能力、规划能力、行动能力和记忆能力。最后推荐智泊AI的课程,旨在培养掌握这些核心能力的大模型时代抢手人才,帮助学员从基础到前沿系统学习AI技术,实现高薪就业。
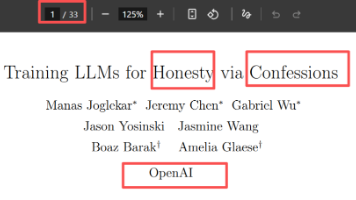
Google发布Gemini 3 Deep Think,在ARC-AGI-2评测中准确率达45.1%,采用并行推理技术同时探索多个假设。OpenAI提出"忏悔训练"方法,让模型在回答后生成自白,与主回答奖励脱钩,显著提高诚实性。研究显示该方法在12项评测中11项表现出更高诚实率,有效减少模型奖励破解、暗中违规和幻觉问题,为提升大模型可靠性提供新思路。
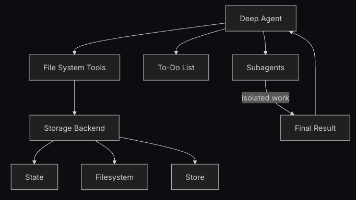
LangGraph DeepAgents是LangChain团队开源的图式智能体编排框架,通过"指挥官-子兵"模式实现多智能体协同工作。与传统线性架构不同,它提供图结构控制流、持久化状态管理和智能体间高效通信机制。文章详细介绍了其架构设计、实战案例构建方法、高级特性及生产环境优化策略,展示了如何快速构建专业级多智能体系统,如3秒内完成东京旅行规划的案例。
谷歌最新Gemini 3 Pro在多模态能力上表现卓越,多项基准测试超越GPT-5.1等竞争对手。其四大核心能力包括:文档理解(处理潦草扫描件)、空间理解(像素级定位)、屏幕理解(精确操作软件)和视频理解(10 FPS高帧率分析)。API开放media_resolution参数,允许开发者灵活选择精度。对学习大模型的开发者和爱好者而言,Gemini 3 Pro代表了当前多模态AI技术的最新发展方向
