- @2401_85280307
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
语言建模的研究始于20世纪90年代,最初采用了统计学习方法,通过前面的词汇来预测下一个词汇。然而,这种方法在理解复杂语言规则方面存在一定局限性。随后,研究人员不断尝试改进,其中在2003年,深度学习先驱Bengio在他的经典论文《A Neural Probabilistic LanguageModel》中,首次将深度学习的思想融入到语言模型中,使用了更强大的神经网络模型,这相当于为计算机提供了更强
大型语言模型(LLM)正在给各个行业带来革命性的变化。从客户服务聊天机器人到复杂的数据分析工具,这项强大技术的能力正在重塑数字交互和自动化的格局。然而,LLM的实际应用受到需要高性能计算硬件环境的限制。这些模型通常需要复杂的硬件和广泛的依赖关系,这使得在更受约束的环境中采用它们变得困难。而LLaMa.cpp 正是为了解决这个问题而诞生。LLaMa.cpp由Georgi Gerganov开发,它在高

请申请一个免费 T4 GPU 来运行该脚本详细讲上面连接。需要科学上网微调过程大约需要 50 分钟。
语言建模的研究始于20世纪90年代,最初采用了统计学习方法,通过前面的词汇来预测下一个词汇。然而,这种方法在理解复杂语言规则方面存在一定局限性。随后,研究人员不断尝试改进,其中在2003年,深度学习先驱Bengio在他的经典论文《A Neural Probabilistic LanguageModel》中,首次将深度学习的思想融入到语言模型中,使用了更强大的神经网络模型,这相当于为计算机提供了更强
LangChain 的作者是 Harrison Chase,最初是于 2022 年 10 月开源的一个项目,在 GitHub 上获得大量关注之后迅速转变为一家初创公司。2017 年 Harrison Chase 还在哈佛上大学,如今已是硅谷的一家热门初创公司的 CEO,这对他来说是一次重大而迅速的跃迁。Insider 独家报道,人工智能初创公司 LangChain 在种子轮一周后,再次获得红杉领投

大型语言模型(LLM)正在给各个行业带来革命性的变化。从客户服务聊天机器人到复杂的数据分析工具,这项强大技术的能力正在重塑数字交互和自动化的格局。然而,LLM的实际应用受到需要高性能计算硬件环境的限制。这些模型通常需要复杂的硬件和广泛的依赖关系,这使得在更受约束的环境中采用它们变得困难。而LLaMa.cpp 正是为了解决这个问题而诞生。LLaMa.cpp由Georgi Gerganov开发,它在高
例如支持向量机,我已经知道它的决策函数(分类面)是线性的了,也就是可以表示成Y=f(X)=WX+b的形式,那么我们通过训练样本来学习得到W和b的值就可以得到Y=f(X)了。例如你投硬币,你试了100次,得到正面的次数和你的试验次数的比可能是3/10,然后你直觉告诉你,可能不对,然后你再试了500次,哎,这次正面的次数和你的试验次数的比可能就变成4/10,这时候你半信半疑,不相信上帝还有一个手,所以
智能体构建器:一个自动指令和工具提供者,通过与用户聊天来定制用户的智能体用户智能体:一个为用户的实际应用定制的智能体,提供构建智能体或用户输入的指令、额外知识和工具配置设置工具:支持用户定制用户智能体的配置,并实时预览用户智能体的性能在使用dashscope提供的qwen api构建应用与定制交互的过程中,我们发现选取千亿级别参数的qwen-max或开源的qwen-72b等大规模参数模型能获得较好

Ollama是一个专为在本地机器上便捷部署和运行大型语言模型(LLM)而设计的工具。所谓自定义模型就是不适用Ollama官方模型库中的模型,理论可以使用其他各类经过转换处理的模型Ollama库中的模型可以通过提示进行自定义。# 设置温度参数# 设置SYSTEM 消息SYSTEM """作为AI智能助手,你将竭尽所能为员工提供严谨和有帮助的答复。"""Modelfile文档One-API是一个Ope

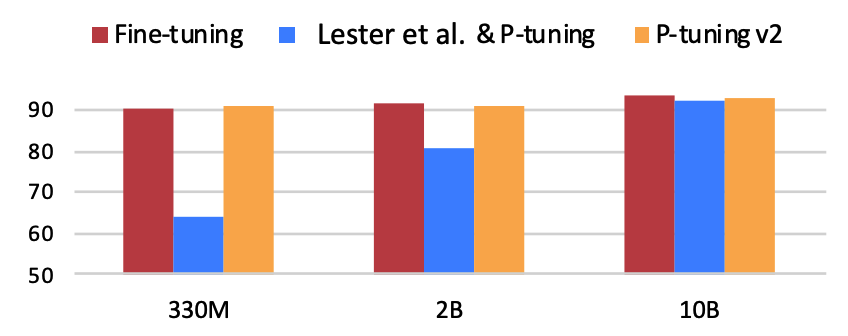
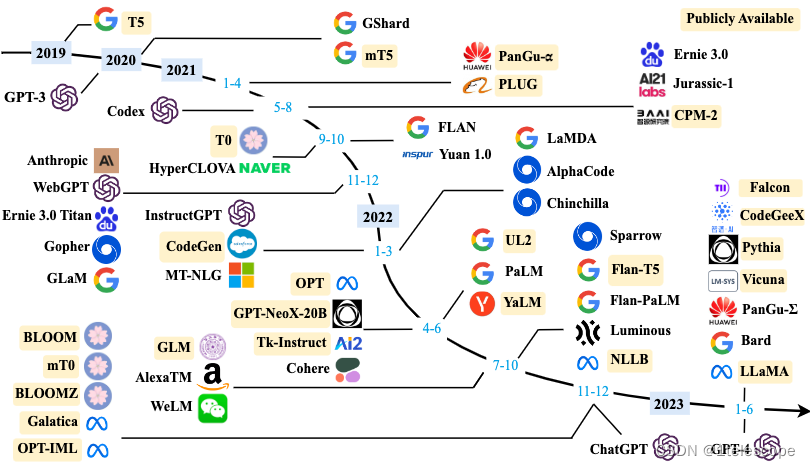
最近对大模型这部分内容比较感兴趣,作者最早接触大模型是22年下半年的时候。当时觉得非常amazing,并认为这是一个颠覆性的工作,目前随着开源大模型的逐渐变多。我觉得我们得学习并了解这些基础知识,以便后续在工作中可以学习并使用。在深度学习中,微调是一种重要的技术,用于改进预训练模型的性能。除了微调ChatGPT之外,还有许多其他预训练模型可以进行微调。微调所有层:将预训练模型的所有层都参与微调,以