




- @2401_84271379
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
对于已经在OpenList中的4个格子,我们以它上面的格子S[2][2]举例,从起点A经由格子S[3][2]到达格子S[2][2]的G值为20(10+10)大于从起点A直接沿对角线到达格子S[2][2]的G值14。与PRM相同的是两者都是基于随机采样的算法,不同的是PRM最终生成的是一个无向图,而RRT生成的是一个随机树。对于图6所示的有向图,V可以表示为{A,B,C,D,E,F,G},E可以表示
我们有一大堆的数据,这些数据可能是结构化的、非结构化的以及半结构化的,然后我们基于这些数据来构建知识图谱,这一步主要是通过一系列自动化或半自动化的技术手段,来从原始数据中提取出知识要素,即一堆实体关系,并将其存入我们的知识库的模式层和数据层。文本语料经过实体抽取,得到的是一系列离散的命名实体,为了得到语义信息,还需要从相关的语料中提取出实体之间的关联关系,通过关联关系将实体(概念)联系起来,才能够
查看nouveau驱动的启用情况,如果有输出表示nouveau驱动正在工作,如果没有内容输出则表示已经禁用了nouveau。A2000,在产品列表中选择对应显卡,然后操作系统选择Linux 64-bit,点击搜索后进行下载。,则需要,在重启的时候,按住ESC或者F2,进入recover 模式,进行下面的步骤。安装成功后,reboot 重启,输入nvidia-smi 查看。根据自己的显卡选择所需下载
码头堆场全是五六层的金属集装箱,岸桥也全是百米高的钢铁巨人,这种多金属的场景,高精度组合导航的多径影响会非常严重,卫导信号基本是没法用的,如果这个时候选择相信组合导航里融合IMU的数据,岸桥下长时间的停车装船卸船又会造成巨大的累积误差。这个场景里有各家都在发力的Robotaxi,说不定在广州、深圳、上海、北京部分地区已经体验过他们的打车服务,玩家有小马智行,百度,文远知行,AutoX等。上到宇宙第
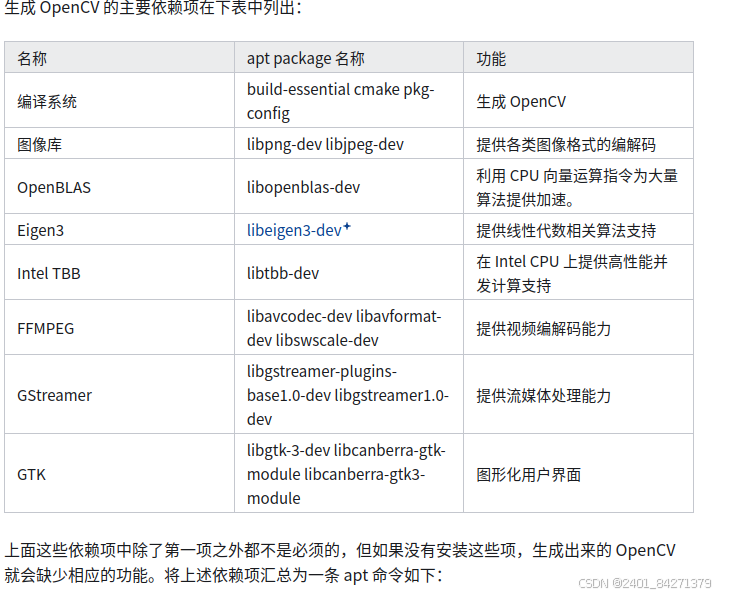
你需要下载OpenCV 4.8.1的源码以及opencv_contrib模块(包含额外的算法和模块)。或者你可以通过git命令来下载:cd opencv。
视觉语言导航(Vision-Language Navigation, VLN)是一个多学科交叉的研究领域,它涉及到自然语言处理、计算机视觉和机器人导航等多个方面。在这个领域中,研究人员致力于开发能够理解自然语言指令并在复杂环境中进行自主导航的机器人或智能体。
核心定义具身智能(Embodied Intelligence)是基于物理身体与动态物理环境交互的智能系统,通过 “感知 - 行动” 闭环实现适应性行为,是人工智能与机器人学的交叉领域,核心是 “给智能一个物理载体”。与传统 AI 的核心差异维度传统 AI(如 ChatGPT、图像识别)具身 AI(如家庭机器人、自动驾驶)交互环境静态、封闭的数字世界动态、开放的物理世界数据输入单一 / 特定模态(文
与语言模型可依赖海量公开文本不同,自动驾驶需依赖大量真实行车视频、车辆状态及对应的人类驾驶行为数据,且必须覆盖夜间、雨雪、施工区、临时障碍物等稀有场景。端到端分为狭义端到端与广义端到端,狭义端到端指通过单一神经网络将原始信号直接映射为控制指令;其中,数据闭环的效率、算力部署的规模与验证体系的完备性,共同构成了端到端系统能否稳定落地并持续演进的关键支撑。在早期的自动驾驶系统中,感知任务主要集中于二维
自动驾驶的技术栈正在经历前所未有的重构。无论是追求极致效率的 Conventional E2E,还是探索认知上限的 VLM-centric,亦或是博采众长的 Hybrid 架构,每一条技术路线都在为最终的“类人驾驶”贡献拼图。本文所构建的 GE2E(广义端到端) 统一视角,旨在为研究者们提供一个清晰的坐标系。我们不再纠结于单一范式的优劣,而是透过现象看本质——如何用数据驱动的方式,实现从传感器输入
SLAM比较专业的解释为:机器从未知环境的未知地点出发,在运动过程中通过传感器重复观测到的环境特征定位自身位置和姿态,再根据自身位置构建周围环境的增量式地图,从而达到同时定位和地图构建的目的。定位更新是指在已知机器人初始位姿的条件下,结合本体运动模型,通过将观测到的特征与地图中的特征进行匹配,求取它们之间的差别,进而更新机器人位姿的定位方法。建立了场景地图,剩下的就是根据地图实现自身的定位,这也是