




- @2401_84166811
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
所有的 props 都遵循着单向绑定原则,props 因父组件的更新而变化,自然地将新的状态向下流往子组件,而不会逆向传递。我们需要在 register.vue 中为 input.vue 绑定自定义事件, 子组件将数据以参数的形式传给父组件,并触发。对 error_message 进行数据监视, 每当error_message发生改变时,就进行一次提示。 格式无误: 将 input_data 中

router.pushUrl({ url: ‘pages/HomePage’, params: { msg: ‘hello world,我是上一个页面传递过来的’ } },// 调用router.showAlertBeforeBackPage()方法,设置返回询问框的信息。’ // 设置询问框的内容。Button(‘返回上一页’).onClick(() => {// 调用router.back()

总结起来,distcp命令是Hadoop中用于复制数据的工具,可以在不同的Hadoop集群之间、不同的Hadoop文件系统之间、甚至本地文件系统和Hadoop文件系统之间进行数据复制。以下是一个使用distcp命令的例子: 假设我们有两个Hadoop集群:源集群和目标集群,并且我们要将源集群上的/user/source_data目录中的数据复制到目标集群的/user/target_data目录中。

通常情况下,应用如果可自行决定创建多少个进程、自定义服务时,系统为保证用户体验,需要在后台运行管控、进程关联启动等方面对应用的运行状态进行强管理,从而降低系统总体的内存占用和功耗开销。Stage模型基于场景的服务扩展、严格的后台管控机制和受限的进程模型,重新定义了应用能力边界,使进程环境从“无序”到“有序”,规范了进程管理模型。

这里的hosts是批处理代码从需要读取的hosts,想批处理哪台服务器就写哪个host。

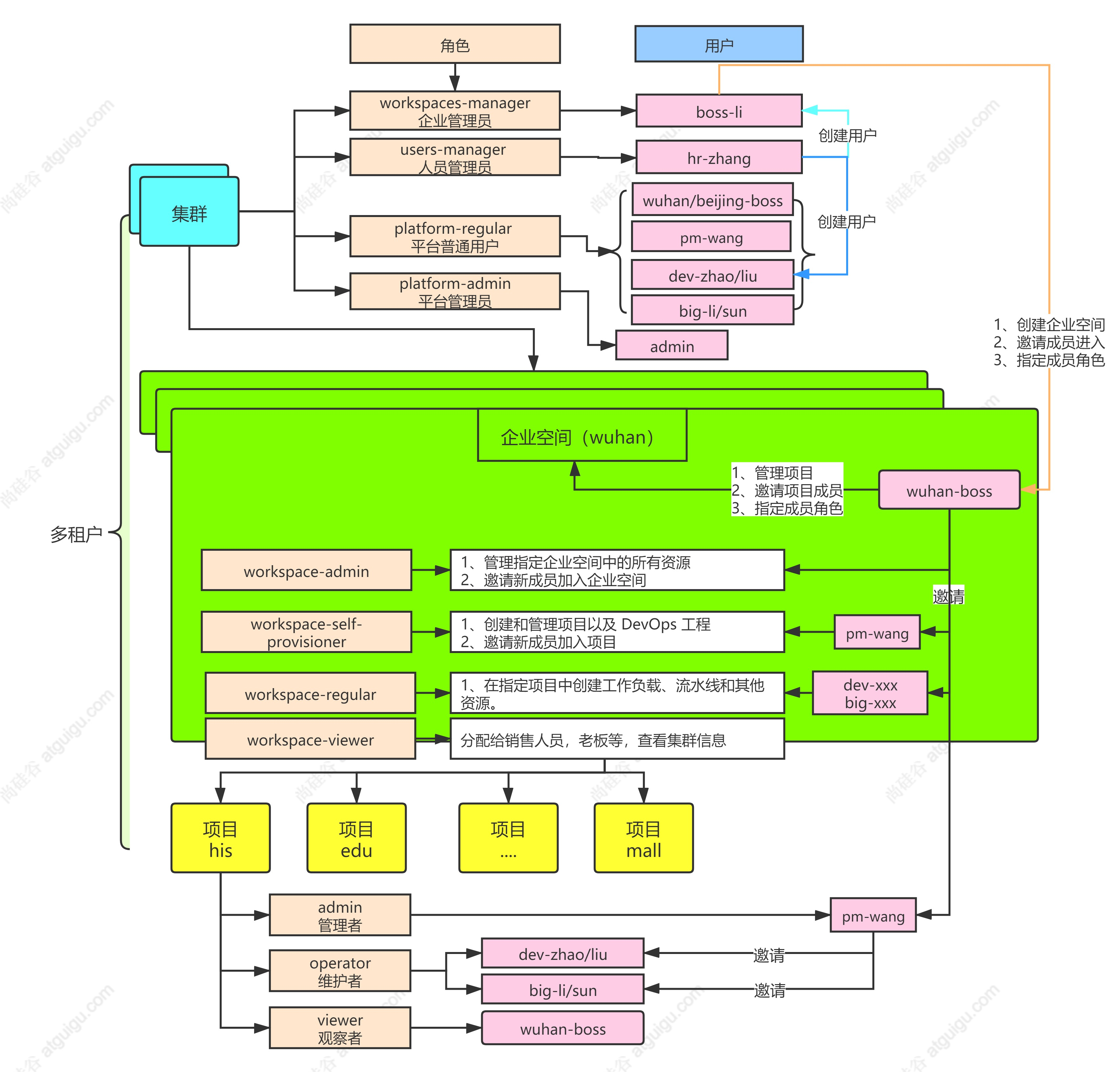
我们来看看多租户实战,首先什么是多租户?我们看到下面这图✅看图写作环节集群里面角色分为了企业管理员(workspaces-manager)、人员管理员(users-manager)、平台普通用户(platform-regular)、平台管理员(platform-admin)
需要注意的是,这里的Secondary节点必须是数据节点,可以是隐藏节点、延迟节点或Priority为 0 的节点,但仲裁节点(Arbiter)绝对不行。图中是一个一主两从的副本集,设置了w: “majority”,代表一个写操作,需要等待副本集中绝大多数节点(本例中是两个)应用完,才能给客户端反馈。Write Concern,可理解为写安全策略,简单来说,它定义了一个写操作,需要在几个节点上应用
我开始思考,是不是因为索引失效了,但是我是写的有主键的,按照MySQL的默认引擎InnoDB的索引方法,每次查询应该会走索引的,即使表中没有主键,也没有不重复的列,InnoDB也会自己用隐藏列中的rowid做唯一索引的。是这样的,如果主键连续递增,这么写sql雀氏非常完美,但是实际项目中,主键一般都是用雪花算法生成的,上一条的主键和下一条的主键之间一般不会是简单的加一减一的关系,所以我们取前500

一级入口重点内容executors不同executors之间,是否存在负载倾斜不同executors之间,是否存在负载倾斜storage分布式数据集的缓存级别,内存,磁盘缓存比例SQL初步了解不同执行计划的执行时间,确实是否符合预期jobs初步感知不同jobs的执行时间,确实是否符合预期stage初步感知不同stage的执行时间,确实是否符合预期记录了以action为粒度,记录了每个action作

用于大规模数据处理的统一分析引擎特点:对任意类型(结构化、半结构化、非结构化)的数据进行自定义计算。
