




- @2401_83357065
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
在本项目教程中,我们曾经提到过部署 MCP 服务可以使用 Serverless。使用 Serverless 平台,开发者只需关注业务代码的编写,无需管理服务器等基础设施,系统会根据实际使用量自动扩容并按使用付费,从而显著降低运维成本和开发复杂度。因此,Serverless 很适合业务规模不确定的、流量波动大的场景,也很适合我们学习时快速部署一些小型项目,不用买服务器、不用的时候

MCP(Model Context Protocol,模型上下文协议)是一种开放标准,目的是增强 AI 与外部系统的交互能力。MCP 为 AI 提供了与外部工具、资源和服务交互的标准化方式,让 AI 能够访问最新数据、执行复杂操作,并与现有系统集成。根据官方定义,MCP 是一种开放协议,它标准化了应用程序如何向大模型提供上下文的方式。可以将 MCP 想象成 AI 应用的 USB 接口。

嵌入模型是 AI 理解非结构化数据的底层基石,核心是语义向量化。BGE-M3 凭借多语言、三合一检索、超长文本三大能力,成为当前最通用、最强悍的嵌入模型,全面覆盖检索、RAG、跨语言等工业场景。

例如:我直接在Ollama安装路径下创建了一个Models文件夹作为存储路径:D:\cloudsoft\ollama\models。变量值为:D:\cloudsoft\ollama\Models。在OllamaSetup.exe所在目录打开cmd命令行。变量名为:OLLAMA_MODELS。这里我选择7b的模型。
SpringAI整合了全球(主要是国外)的大多数大模型,而且对于大模型开发的三种技术架构都有比较好的封装和支持,开发起来非常方便。不同的模型能够接收的输入类型、输出类型不一定相同。SpringAI根据模型的输入和输出类型不同对模型进行了分类:大模型应用开发大多数情况下使用的都是基于对话模型(Chat Model),也就是输出结果为自然语言或代码的模型。目前SpringAI支持的大约19种对话模型,

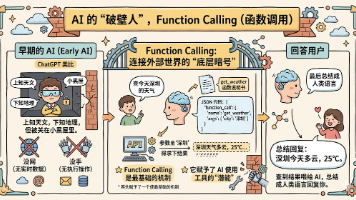
Function Calling(函数调用):是底层技术,让大模型拥有了“伸手”调取外部工具的能力。MCP(模型上下文协议):是接口标准,统一了全网工具的接入规格,让 AI 拥有了“Type-C”通用插口。Skills(技能):是上层的业务封装(26年初的新宠),它将 Prompt 指令和 MCP 工具组合在一起,按清晰的目录结构管理起来,变成了 AI 可以随拿随用、彻底告别重复劳动的“标准工作流
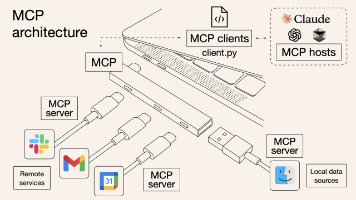
MCP 是什么:Anthropic 推出的开放标准协议,定义了 AI 应用和工具服务之间如何标准化通信,是 AI 工具世界的「USB-C」。为什么需要它:没有统一标准时,每个工具都要自己写集成,多模型场景下是 N×M 的重复工作量;MCP 把这个问题变成 N+M,工具写一次,全平台可用。三大角色:Host(AI 应用)通过内置的 Client(连接器)调用 MCP Server(工具服务),职责清
例如:我直接在Ollama安装路径下创建了一个Models文件夹作为存储路径:D:\cloudsoft\ollama\models。变量值为:D:\cloudsoft\ollama\Models。在OllamaSetup.exe所在目录打开cmd命令行。变量名为:OLLAMA_MODELS。这里我选择7b的模型。
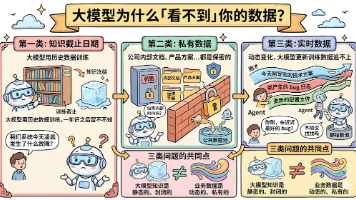
RAG 是什么:Retrieval-Augmented Generation,检索增强生成。先从知识库里找到相关内容,再把这些内容加进 Prompt,让大模型基于私有数据生成有据可查的回答。为什么需要它:大模型的知识是静态的、封闭的,而业务数据是动态的、私有的。把数据全量塞进 Prompt 行不通,超 token 限制、费钱、注意力稀释。RAG 用「按需检索 + 动态注入」绕开了这个死局。两大阶段
Function Calling(函数调用):是底层技术,让大模型拥有了“伸手”调取外部工具的能力。MCP(模型上下文协议):是接口标准,统一了全网工具的接入规格,让 AI 拥有了“Type-C”通用插口。Skills(技能):是上层的业务封装(26年初的新宠),它将 Prompt 指令和 MCP 工具组合在一起,按清晰的目录结构管理起来,变成了 AI 可以随拿随用、彻底告别重复劳动的“标准工作流