- @2301_80132162
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本文总结了常见数据结构与算法的核心知识点。顺序存储(如数组)支持随机访问但插入删除慢,链式存储(如链表)插入删除快但不支持随机访问。栈和队列部分介绍了共享栈、循环队列及其实现方式。KMP算法通过next数组实现主串不回退的匹配。树结构包括哈夫曼树(带权路径最小)、完全二叉树、堆(大/小根堆)、二叉排序树(中序有序)及其平衡版本(AVL树通过旋转保持平衡)。红黑树放宽平衡条件减少调整。B树和B+树是
这些命令一般,例如。Claude.md。
本文介绍了智能体(Agent)系统的核心概念与技术架构。主要内容包括:1)ReAct和Plan-Act两种执行架构,前者通过推理-执行循环完成任务,后者采用规划-执行-重规划流程;2)Function Calling与MCP协议,分别规范LLM输出格式和工具调用方式;3)上下文工程和子智能体技术,优化任务处理效率;4)记忆系统实现,通过RAG和语义嵌入进行信息检索;5)心跳机制和Crob Job系
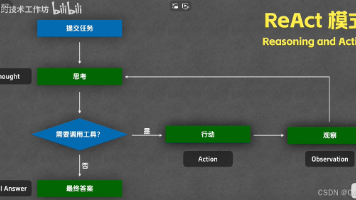
这些命令一般,例如。Claude.md。
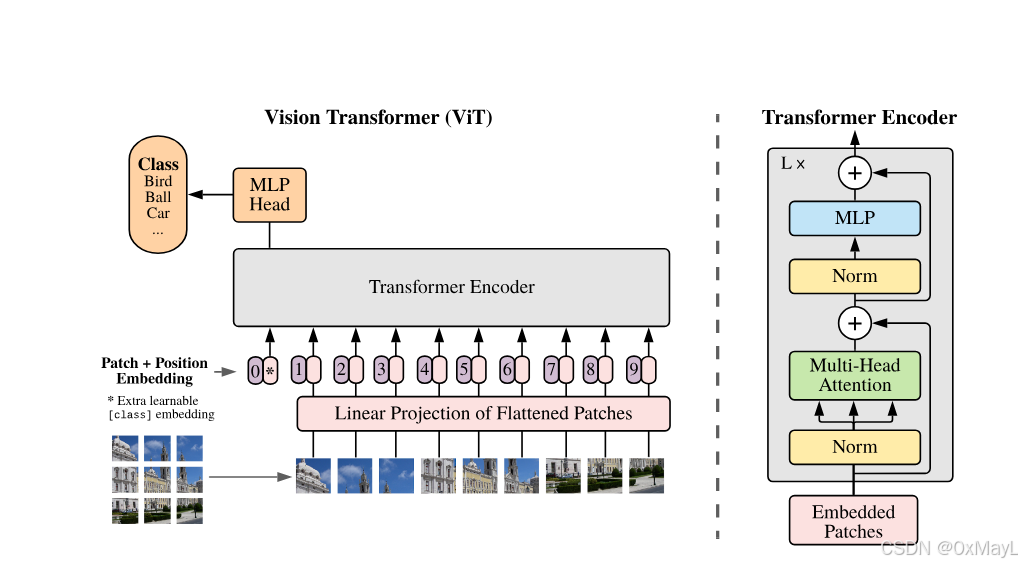
🔤我们注意到 Vision Transformer 的图像特异性电感偏差比 CNN 小得多。在 CNN 中,局部性、二维邻域结构和平移等方差被烘焙到整个模型的每一层中🔤。
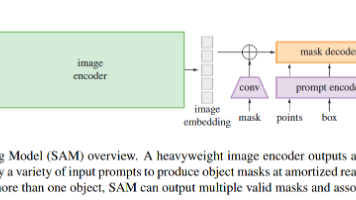
本文提出了一种基于提示的通用图像分割模型SAM。模型采用ViT-H作为图像编码器,支持点、框、文本和掩膜等多种提示方式。提示编码器将稀疏提示转换为嵌入向量,掩膜则通过卷积处理后与图像嵌入叠加。掩膜解码器采用类似DETR和MaskFormer的结构,通过交叉注意力机制生成掩膜预测。为处理提示的二义性,模型会输出3个候选掩膜及其置信度。训练时使用焦点损失和Dice损失的组合,并在SA-1B数据集上进行
这些命令一般,例如。Claude.md。
的含义,并结合作者的因果推导、公式和例子说明为什么这是反事实公平研究中一个此前被忽视、但极其关键的问题。(如性别、种族)在**获得正向预测(positive prediction)**方面是否存在差异。注意:对于连续标签(如 Law School 的成绩),论文采用。这在现实中非常普遍(如:性别→教育资源→考试成绩→录取)。也就是:真实标签是 0,但模型预测成 1 的比例。即使生成器生成的数据是公
作者对于ZS3和GZS3的新定义方式,还是比较有意思简单来说就是把语义分割看成两个部分先对图像进行分块,例如RR表示多个区域,这些区域不重叠然后找到一种标签映射关系LL,用于将这些区域映射到标签集合。
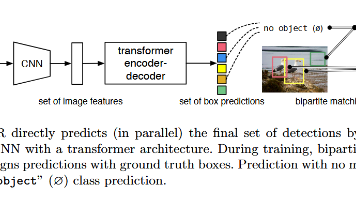
由于N的数量肯定是大于图像中真实锚框的数量和标签集M,因此作者引入了一个No Object作为新的标签集。,这N个锚框经过FFN分别得到分类结果和锚框坐标。这些query向量首先经过自注意力进行交互。总损失:N个分类损失,M个锚框和GIoU损失。DETR设计了N个可以学习的query。就像NMS一样,作者需要减少锚框的数量。首先通过CNN+1x1卷积得到特征图,,N的数量大于图像中实际存在的数量。