




- @2301_79176091
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
LangGraph提供了三种关键特性来优化状态管理:1. Overwrite机制允许绕过默认的reducer合并逻辑,直接覆盖状态值(如重置聊天记录);2. 输入输出模式分离通过独立定义input_schema和output_schema,实现数据暴露控制;3. 私有状态传递支持节点间共享临时数据而不泄露到最终输出。这些特性共同解决了状态更新策略、接口清晰度和数据安全性等生产级AI应用的核心需求,
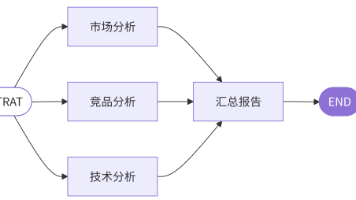
本文介绍了五种基于LangGraph的工作流模式,通过预先定义执行路径实现任务自动化处理: 提示链模式 线性流程:前一步输出作为后一步输入 示例:大纲→初稿→润色→终稿的内容创作流程 并行化模式 多任务同时执行 示例:市场/竞品/技术分析同时进行 路由模式 动态路径选择 示例:客服系统根据问题类型智能分流 协调者-工作者模式 动态任务分配 示例:协调者拆分文档,工作者并行处理不同章节 评估器-优化
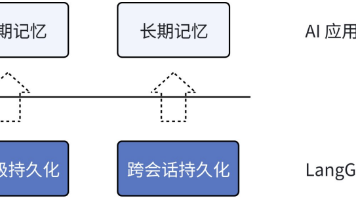
本文介绍了LangGraph持久化实现的三大核心应用能力:记忆管理、人机交互和时间旅行。首先,记忆功能分为短期记忆(单次会话)和长期记忆(跨会话),支持消息修剪、删除和总结等管理操作。其次,人机交互通过中断机制实现流程暂停和人工干预,适用于审批、编辑、验证等场景,并强调了中断使用的四大黄金规则。最后,时间旅行功能允许回溯和修改历史状态,用于调试分析和探索替代路径。这些能力共同构成了LangGrap
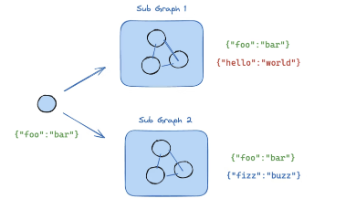
本文介绍了LangGraph中的三个核心概念:运行时上下文、流式处理和子图,及其应用方法。 1. 运行时上下文 功能:管理程序运行时的数据和环境信息,分为静态(单次运行不变)和动态(运行中变化)两类。 应用:通过dataclass定义结构,在节点中通过runtime参数访问,支持个性化响应、权限控制等场景。 示例:智能旅行助手根据用户语言、会员等级等静态数据提供个性化服务,同时记录动态对话历史。
本文介绍了HTTP Cookie和Session的工作原理及应用。Cookie是服务器发送到浏览器的小块数据,用于跟踪用户状态,分为会话Cookie和持久Cookie。文章详细讲解了Set-Cookie头的格式、属性(如expires、path、secure等)及安全性考虑。通过实验演示了Cookie的写入、自动提交、过期时间和路径限制等功能。Session是服务器端的会话管理机制,通过Sessi

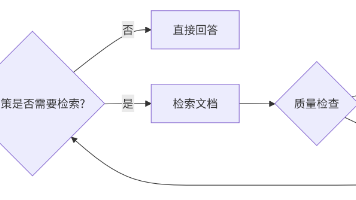
本文介绍了基于 LangGraph 实现的智能代理式 RAG(检索增强生成)系统,相比传统线性 RAG 具有更强的鲁棒性和动态调整能力。系统通过模块化设计将工作流程分解为决策节点、检索节点、问题优化节点和答案生成节点,形成"检索-检查-优化-再检索"的质量闭环。案例以技术文档问答为例,展示了如何通过本地嵌入模型处理知识库、构建检索工具,并利用条件路由实现动态查询优化。该系统能在初次检索失败时自动重
构建 Graph 图,首先需要【定义状态】,然后【定义并添加节点和边】,最后【编译】它。编译提供 了对图形结构的一些基本检查(没有孤立节点等)LangGraph 所谓的“编译” 与 传统意义上的语言编译完全不同,LangGraph 编译本质是在运行时动 态构建和验证一个复杂的图,而非翻译代码。C++的编译是“完整编译”或“静态编译”的典范。 它追求在程序运行之前,就将所有代码“解 决”完毕,生成一
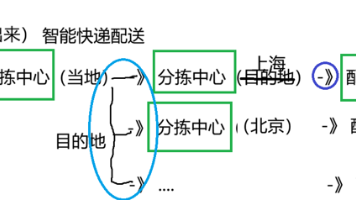
构建 Graph 图,首先需要【定义状态】,然后【定义并添加节点和边】,最后【编译】它。编译提供 了对图形结构的一些基本检查(没有孤立节点等)LangGraph 所谓的“编译” 与 传统意义上的语言编译完全不同,LangGraph 编译本质是在运行时动 态构建和验证一个复杂的图,而非翻译代码。C++的编译是“完整编译”或“静态编译”的典范。 它追求在程序运行之前,就将所有代码“解 决”完毕,生成一
LangGraph:智能体服务的操作系统内核 LangGraph是专为构建复杂AgentServer设计的底层框架,解决了状态管理、流程编排等核心难题。相比传统单次对话的AI系统,它具备三大核心能力:1)长期记忆,可跨会话保存上下文;2)多步任务编排,支持复杂流程执行(如旅行规划场景下的天气查询、景点推荐等串联操作);3)容错与干预机制,允许人工介入和故障恢复。其图计算架构通过节点(处理单元)、边
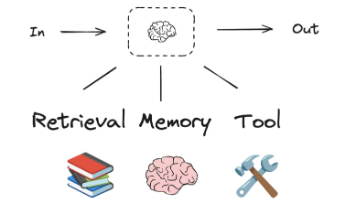
LangGraph:智能体服务的操作系统内核 LangGraph是专为构建复杂AgentServer设计的底层框架,解决了状态管理、流程编排等核心难题。相比传统单次对话的AI系统,它具备三大核心能力:1)长期记忆,可跨会话保存上下文;2)多步任务编排,支持复杂流程执行(如旅行规划场景下的天气查询、景点推荐等串联操作);3)容错与干预机制,允许人工介入和故障恢复。其图计算架构通过节点(处理单元)、边