- @2201_75437633
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本文总结了PyTorch中RNN循环神经网络的原理与实践应用。RNN通过隐藏状态传递时序信息,适合处理序列数据。文章详细解析了RNN的数学公式、多层网络结构、输入输出维度,并对比了独热编码与词嵌入的差异。同时提供了基于MNIST手写数字分类的完整PyTorch实现代码,包括数据预处理、模型定义、训练流程等关键环节。该实现支持CPU/GPU运行,适合初学者快速上手RNN在序列任务中的应用。

本文总结了PyTorch深度学习中的梯度下降算法要点:梯度下降通过计算损失函数对参数的偏导数(梯度),沿负梯度方向更新参数以最小化损失函数。学习率控制参数更新步长。相比穷举法,梯度下降能高效缩小参数搜索范围。文中提供了梯度下降和随机梯度下降的Python实现代码,前者批量计算梯度,后者每次使用单个样本更新参数,导致更频繁的梯度更新。两种方法都通过迭代优化权重w,使预测值逐渐接近真实值,并可视化训练

摘要:本文总结了B站UP主刘二大人《PyTorch深度学习实践》中逻辑斯蒂回归的核心知识点。逻辑斯蒂回归通过在线性模型后添加Sigmoid激活函数实现二分类,使用交叉熵损失函数优化模型。文章详细讲解了模型结构、损失计算和反向传播过程,并提供了完整的PyTorch实现代码,包括数据生成、模型定义、训练流程和评估方法。关键点包括Sigmoid函数的作用、BCE损失的计算以及梯度下降优化过程。该模型在模

本文总结了PyTorch深度学习中的梯度下降算法要点:梯度下降通过计算损失函数对参数的偏导数(梯度),沿负梯度方向更新参数以最小化损失函数。学习率控制参数更新步长。相比穷举法,梯度下降能高效缩小参数搜索范围。文中提供了梯度下降和随机梯度下降的Python实现代码,前者批量计算梯度,后者每次使用单个样本更新参数,导致更频繁的梯度更新。两种方法都通过迭代优化权重w,使预测值逐渐接近真实值,并可视化训练
摘要:本文总结了B站UP主刘二大人《PyTorch深度学习实践》中逻辑斯蒂回归的核心知识点。逻辑斯蒂回归通过在线性模型后添加Sigmoid激活函数实现二分类,使用交叉熵损失函数优化模型。文章详细讲解了模型结构、损失计算和反向传播过程,并提供了完整的PyTorch实现代码,包括数据生成、模型定义、训练流程和评估方法。关键点包括Sigmoid函数的作用、BCE损失的计算以及梯度下降优化过程。该模型在模
本文总结了B站UP主刘二大人《PyTorch深度学习实践》中卷积神经网络的核心知识点。主要内容包括:1)多通道卷积的数学表达式,详细说明了输入输出特征图的维度关系;2)通过图解展示了卷积操作的数值计算过程,包括输入特征图、卷积核、偏置及输出特征图的维度变化;3)介绍了PyTorch实现CNN的代码框架,包含数据准备、网络结构定义(Conv2d、MaxPool2d、Linear等层)、训练和测试流程

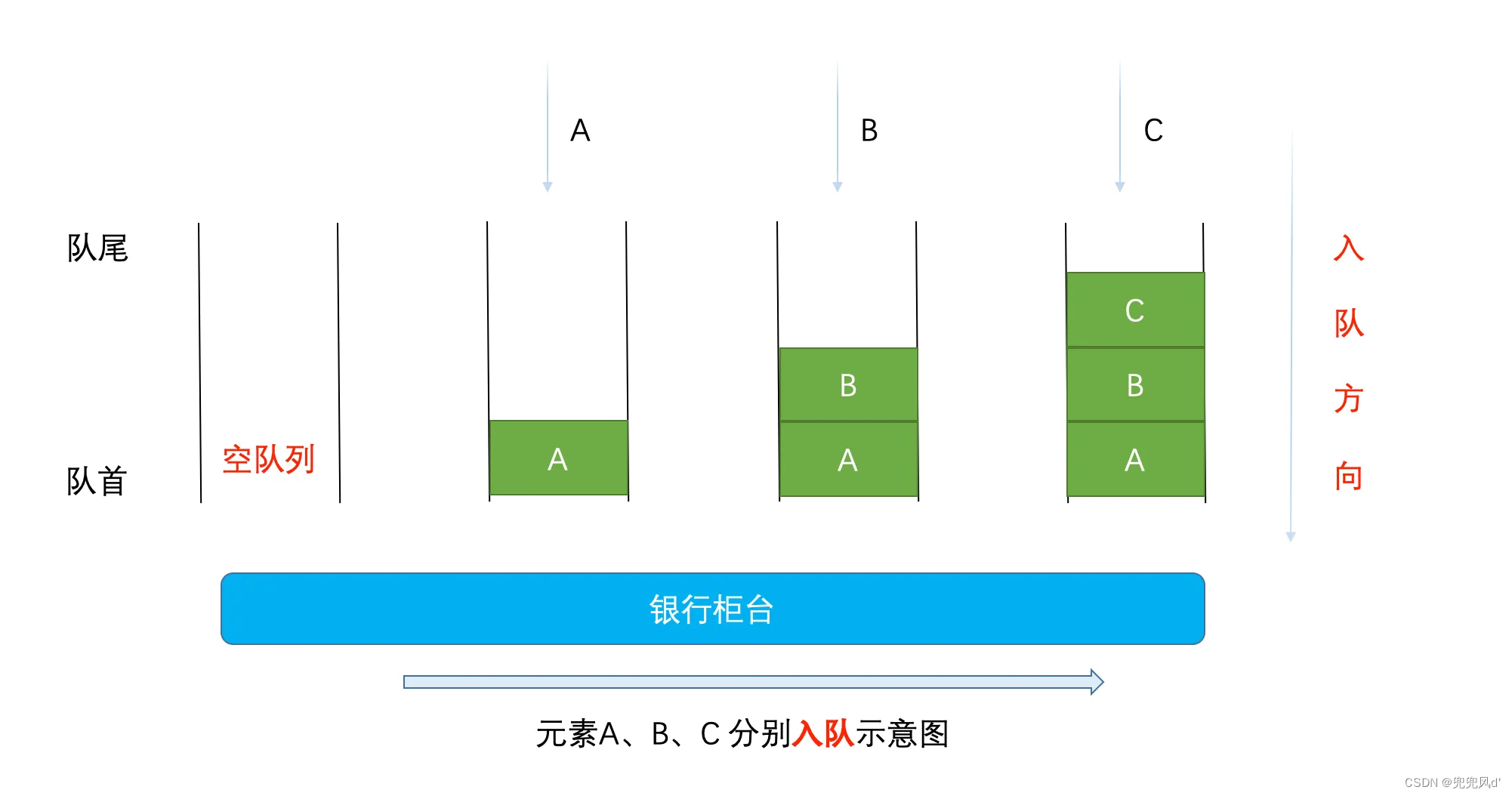
队列是一种线性数据结构,它的特点是先进先出。在队列中,元素的添加(入队)操作在队尾进行,而元素的移除(出队)操作则在队头进行。因此,队列可以被简单地描述为一个“先进先出”的容器。在Java中,队列接口继承自Collection接口,并提供了丰富的方法来操作队列中的元素。