GraphRAG多智能体开发实战:基于LangGraph的智能助手构建全攻略,收藏这篇就够了!
本文详细介绍基于LangGraph构建的GraphRAG多智能体系统实现,该系统作为智能食物助手,能处理食谱发现、购物清单生成和超市产品定位等复杂场景。通过结合语义搜索和Cypher查询,在Neo4j知识图谱上执行多步骤推理,解决了传统RAG在结构化关系建模、多步推理和可解释性方面的不足。文章提供了从零开始构建系统的完整指南,展示了GraphRAG在需要结构化数据、复杂关系和可解释性应用中的优势。
本文详细介绍基于LangGraph构建的GraphRAG多智能体系统实现,该系统作为智能食物助手,能处理食谱发现、购物清单生成和超市产品定位等复杂场景。通过结合语义搜索和Cypher查询,在Neo4j知识图谱上执行多步骤推理,解决了传统RAG在结构化关系建模、多步推理和可解释性方面的不足。文章提供了从零开始构建系统的完整指南,展示了GraphRAG在需要结构化数据、复杂关系和可解释性应用中的优势。
在这篇文章中,我将介绍一个基于 LangGraph 构建的全面 GraphRAG 多智能体系统,它作为一个智能的食物助手。虽然我选择了膳食规划作为演示领域,但这个架构是一个多功能的框架,适用于需要复杂、多维度查询的结构化知识检索的众多行业。

这个系统能处理三种关键领域的复杂场景:
- • 根据饮食限制发现食谱
- • 为特定食谱生成购物清单
- • 在超市内映射商店产品的位置
通过结合语义搜索(semantic search)进行模糊匹配和精确的 Cypher 查询进行结构化数据检索,这个助手能在 Neo4j 知识图谱上执行多步骤推理,为复杂的查询提供语境相关的回答。
Github 仓库地址: https://github.com/PulsarPioneers/meal-planner-graphrag
1. 引言 — Naive RAG vs Graph RAG
为了这个项目,Naive RAG 方法不够用,原因如下:
- • 缺乏结构化关系建模:Naive RAG 从非结构化文本中检索信息,无法表示和推理实体之间的明确关系。这限制了它处理需要理解信息之间连接的查询的效果。
- • 有限的多步推理:它仅在单一层面处理查询,难以回答需要遍历多个数据点或结合结构化语境中各种来源信息的复杂问题。
- • 缺乏可解释性:由于检索仅基于文本相似度,很难追踪答案是如何构建的,也难以提供透明的推理路径。
因此,我们实现了 Graph RAG 系统来解决这些问题。基于图的框架具有以下优势:
- • 明确的实体关系表示:实体及其连接直接在知识图谱中建模,使系统能够理解和利用数据的结构。
- • 多跳和语境推理:系统可以遍历图谱,执行多步骤推理,结合相关节点的信息来回答复杂查询。
- • 基于模式的检索:通过利用图谱的模式(schema),可以精确地制定查询,检索结果与底层数据模型一致。
- • 提升的可解释性:每个答案的推理路径都可以通过图谱追踪,提供清晰的解释和更高的透明度。
这些功能使 Graph RAG 系统成为需要结构化数据、复杂关系和可解释性的应用的更强大且可靠的解决方案。
项目概览
Agentic Graph RAG 图示
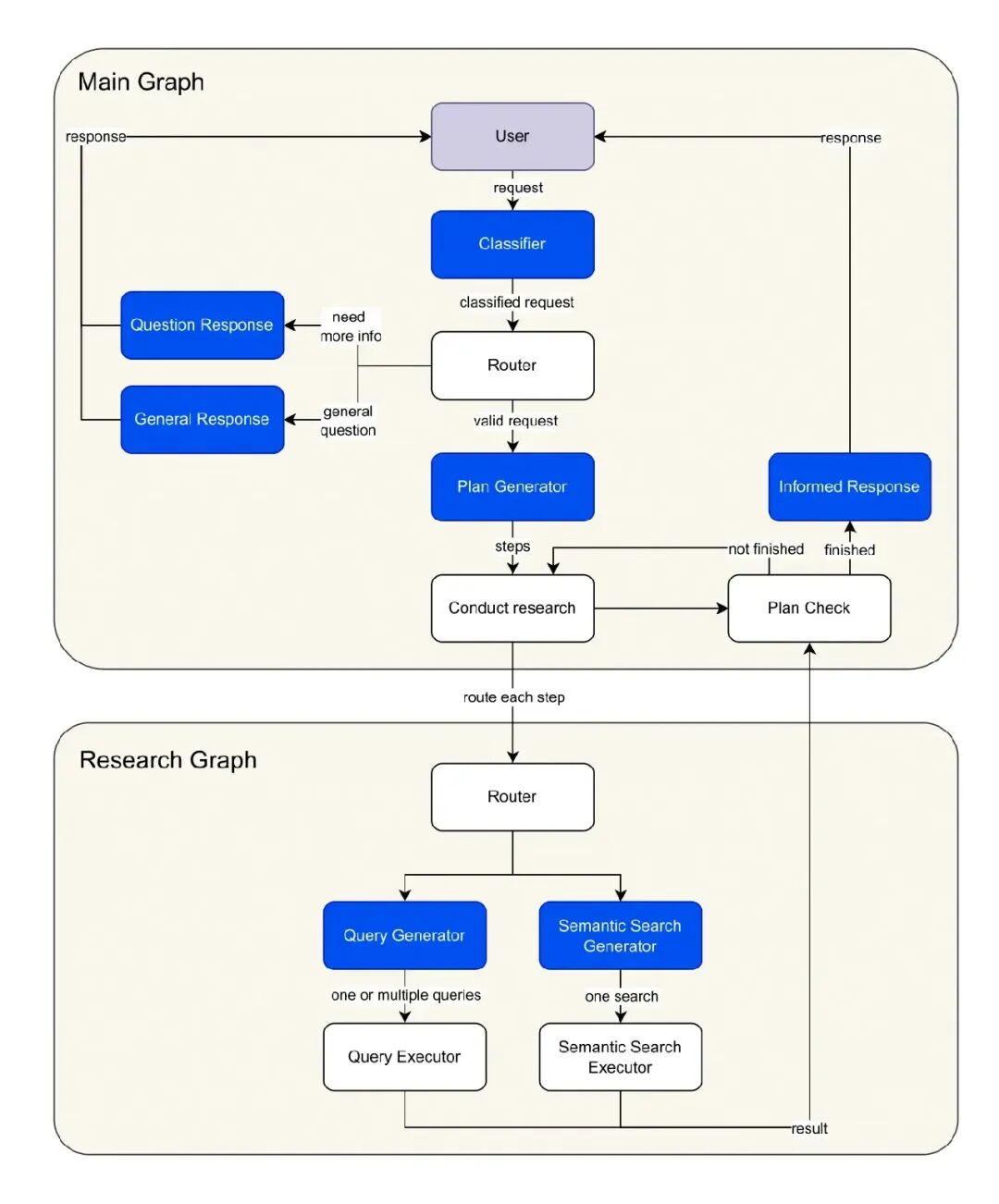
GraphRAG 工作流程步骤:
-
- 查询分析与路由:用户的请求首先被分析和分类,系统会根据查询将其路由到适当的工作流程节点。根据查询内容,系统可能进入下一步(生成研究计划)、提示用户提供更多信息,或者如果请求超出范围则立即回复。
-
- 研究计划生成:系统会根据用户查询的复杂性,构建一个详细的、逐步的研究计划,列出满足请求所需的具体行动。
-
- 研究图谱执行:针对研究计划中的每一步,系统会调用一个专门的子图。通过 LLM 生成 Cypher 查询,针对 Neo4j 知识图谱进行检索。使用语义搜索和结构化图查询的混合方法,检索相关节点和关系,确保结果的广度和精确度。
-
- 答案生成:利用检索到的图谱数据,系统通过 LLM 综合生成全面的回答,根据需要整合多个来源的信息。
在创建图谱时,可以根据需求选择不同的方法。我为了加快速度,自己用样本数据构建了图谱,但也可以使用各种工具。
下面我们来看一种使用 LLM 和 LangChain 构建 Neo4j 图谱的技术。
使用 LLM 构建 Neo4j 图谱
LLM 模型的选择会显著影响输出的准确性和细微差别。
import os
from langchain_openai import ChatOpenAI
os.environ["OPENAI_API_KEY"] = "your-openai-api-key"
llm = ChatOpenAI(temperature=0, model_name="gpt-4o")
LLMGraphTransformer 通过 LLM 解析和分类实体及其关系,将文本文档转换为结构化的图文档。
我们可以根据需求灵活定义需要提取的节点和关系类型。
例如,我们可能需要以下节点:
- • Recipe
- • Foodproduct
以及以下关系:
- • CONTAINS
可以通过以下方式指定:
from langchain_experimental.graph_transformers import LLMGraphTransformer
llm_transformer_filtered = LLMGraphTransformer(
llm=llm,
allowed_nodes=["Recipe", "Foodproduct"],
allowed_relationships=["CONTAINS"],
)
现在,我们可以传入示例文本并检查结果:
from langchain_core.documents import Document
text = """
我最喜欢的烹饪创作是让人无法抗拒的 Vegan Chocolate Cake Recipe。这个美味的甜点以其浓郁的可可风味和柔软湿润的口感而闻名。它完全是素食、无乳制品的,并且由于使用了特殊的无麸质面粉混合物,也是无麸质的。
要制作这个蛋糕,食谱包含以下食品及其相应数量:250克无麸质面粉混合物、80克高品质可可粉、200克砂糖和10克发酵粉。为了丰富口感和确保完美发酵,食谱还包含5克香草精。在液体成分中,需要240毫升杏仁奶和60毫升植物油。
这个食谱可以制作一个巧克力蛋糕,被视为类型为甜点的 Foodproduct。
"""
documents = [Document(page_content=text)]
graph_documents_filtered = await llm_transformer_filtered.aconvert_to_graph_documents(
documents
)
print(f"Nodes:{graph_documents_filtered[0].nodes}")
print(f"Relationships:{graph_documents_filtered[0].relationships}")
输出结果如下:
Nodes:[Node(id='Vegan Chocolate Cake Recipe', type='Recipe', properties={}), Node(id='Gluten-Free Flour Blend', type='Foodproduct', properties={}), Node(id='High-Quality Cocoa Powder', type='Foodproduct', properties={}), Node(id='Granulated Sugar', type='Foodproduct', properties={}), Node(id='Baking Powder', type='Foodproduct', properties={}), Node(id='Vanilla Extract', type='Foodproduct', properties={}), Node(id='Almond Milk', type='Foodproduct', properties={}), Node(id='Vegetable Oil', type='Foodproduct', properties={}), Node(id='Chocolate Cake', type='Foodproduct', properties={})]
Relationships:[Relationship(source=Node(id='Vegan Chocolate Cake Recipe', type='Recipe', properties={}), target=Node(id='Gluten-Free Flour Blend', type='Foodproduct', properties={}), type='CONTAINS', properties={}), Relationship(source=Node(id='Vegan Chocolate Cake Recipe', type='Recipe', properties={}), target=Node(id='High-Quality Cocoa Powder', type='Foodproduct', properties={}), type='CONTAINS', properties={}), Relationship(source=Node(id='Vegan Chocolate Cake Recipe', type='Recipe', properties={}), target=Node(id='Granulated Sugar', type='Foodproduct', properties={}), type='CONTAINS', properties={}), Relationship(source=Node(id='Vegan Chocolate Cake Recipe', type='Recipe', properties={}), target=Node(id='Baking Powder', type='Foodproduct', properties={}), type='CONTAINS', properties={}), Relationship(source=Node(id='Vegan Chocolate Cake Recipe', type='Recipe', properties={}), target=Node(id='Vanilla Extract', type='Foodproduct', properties={}), type='CONTAINS', properties={}), Relationship(source=Node(id='Vegan Chocolate Cake Recipe', type='Recipe', properties={}), target=Node(id='Almond Milk', type='Foodproduct', properties={}), type='CONTAINS', properties={}), Relationship(source=Node(id='Vegan Chocolate Cake Recipe', type='Recipe', properties={}), target=Node(id='Vegetable Oil', type='Foodproduct', properties={}), type='CONTAINS', properties={}), Relationship(source=Node(id='Vegan Chocolate Cake Recipe', type='Recipe', properties={}), target=Node(id='Chocolate Cake', type='Foodproduct', properties={}), type='CONTAINS', properties={})]
最后,生成的图文档可以存储到 Neo4j 图数据库中,通过 Neo4jGraph 的 add_graph_documents 方法初始化:
import os
from langchain_neo4j import Neo4jGraph
os.environ["NEO4J_URI"] = "bolt://localhost:7687"
os.environ["NEO4J_USERNAME"] = "neo4j"
os.environ["NEO4J_PASSWORD"] = "password"
graph = Neo4jGraph(refresh_schema=False)
graph.add_graph_documents(graph_documents_filtered)
然后,我们可以直接从 Neo4j 控制台查询图谱内容:
MATCH p=(r:Recipe)-[:CONTAINS]->(fp:Foodproduct) RETURN p LIMIT 25;

添加节点嵌入
为了更好地理解和消除用户输入的歧义,我们可以在需要时通过语义搜索增强图谱搜索。下面是一个使用 OpenAI 嵌入的示例。
例如,如果用户问:
“给我一个素食巧克力蛋糕食谱的所有原料”
我们需要找到图谱中与查询语义最接近的 Recipe 节点。为此,我们为每个 Recipe 节点存储一个基于其 ID 计算的嵌入。
以下是如何在 Neo4j 中生成和存储嵌入:
import openai
from neo4j import GraphDatabase
driver = GraphDatabase.driver("bolt://localhost:7687", auth=("neo4j", "password"))
recipe_id = "Vegan Chocolate Cake Recipe"
recipe_embedding = openai.embeddings.create(model="text-embedding-3-small", input=recipe_id).data[0].embedding
with driver.session() as session:
# 创建嵌入字段
session.run(
"MATCH (r:Recipe {id: $recipe_id}) SET r.embedding = $embedding",
recipe_id=recipe_id,
embedding=recipe_embedding
)
# 创建向量索引
session.run(
"CREATE VECTOR INDEX recipe_index IF NOT EXISTS FOR (r:Recipe) ON (r.embedding) OPTIONS {indexConfig: {`vector.dimensions`: 1536, `vector.similarity_function`: 'cosine'}}"
)
之后,我们就可以执行语义搜索:
query = "a chocolate cake recipe that is vegan"
query_embedding = openai.embeddings.create(
model="text-embedding-3-small",
input=query
).data[0].embedding
with driver.session() as session:
result = session.run(
"""
CALL db.index.vector.queryNodes('recipe_index', 1, $embedding)
YIELD node, score
RETURN node.id AS name, score
ORDER BY score DESC
""",
embedding=query_embedding
)
for record in result:
print(record["name"], "=>", record["score"])
输出:
Vegan Chocolate Cake Recipe => 0.9284169673919678
这只是一个简要概述,想了解更多技术细节,请查看 LangChain 文档,或者探索其他工具,如官方的 Neo4j LLM Knowledge Graph Builder。
正如我所说,我通过迭代引入样本数据创建了图谱。你可以在 Github 仓库中找到我使用的图谱数据转储!
设计工作流程
实现系统包括两个图谱:
- • 研究子图:负责生成多个 Cypher 查询,用于从 Neo4j 知识图谱中检索相关节点和关系。
- • 主图:包含主要工作流程,包括分析用户查询、生成完成任务所需的步骤,以及生成最终回答。
主图结构
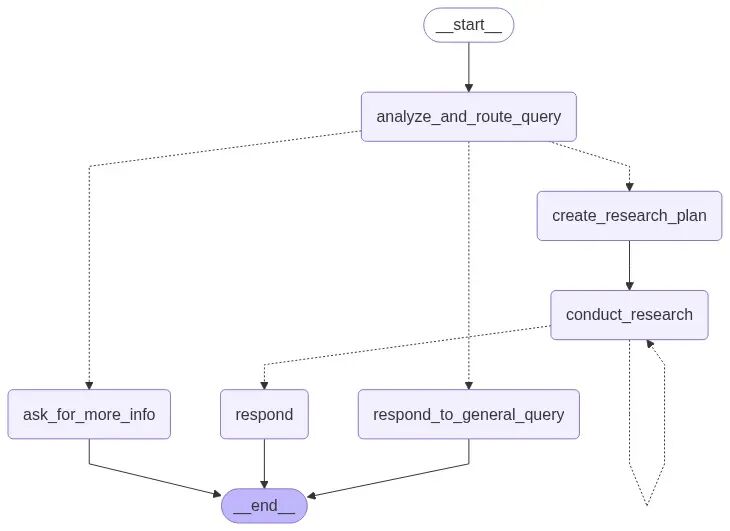
LangGraph 图谱预览
LangGraph 的核心概念之一是状态(state)。每次图谱执行都会创建一个状态,在图谱节点执行时在节点之间传递,每个节点在执行后会用其返回值更新这个内部状态。
让我们从构建图谱状态开始。为此,我们定义了两个类:
Router:包含用户查询的分类结果,分为“more-info”、“valid”或“general”。
from typing importLiteral
from pydantic import BaseModel
classRouter(BaseModel):
"""Classify user query."""
logic: str
type: Literal["more-info", "valid", "general"]
定义的图谱状态包括:
InputState:包含用户和智能体之间交换的消息列表。
from dataclasses import dataclass
from typing import Annotated
from langchain_core.messages import AnyMessage
from langgraph.graph import add_messages
@dataclass(kw_only=True)
classInputState:
"""
表示包含消息列表的输入状态。
属性:
messages (list[AnyMessage]):与状态相关联的消息列表,通过 add_messages 函数处理。
"""
messages: Annotated[list[AnyMessage], add_messages]
AgentState:包含 Router 对用户查询的分类、研究计划中要执行的步骤列表,以及智能体可以参考的检索到的图谱知识列表。
from dataclasses import dataclass, field
from typing import Annotated
from utils.utils import update_knowledge
from core.state_graph.states.main_graph.input_state import InputState
from core.state_graph.states.main_graph.router import Router
from core.state_graph.states.step import Step
@dataclass(kw_only=True)
classAgentState(InputState):
"""
表示主状态图中智能体的状态。
属性:
router (Router):智能体的路由逻辑。
steps (list[Step]):智能体执行的步骤序列。
knowledge (list[dict]):智能体累积的知识,通过 update_knowledge 函数更新。
"""
router: Router = field(default_factory=lambda: Router(type="general", logic=""))
steps: list[Step] = field(default_factory=list)
knowledge: Annotated[list[dict], update_knowledge] = field(default_factory=list)
步骤 1:分析和路由查询
analyze_and_route_query 函数返回并更新状态 AgentState 的 router 变量。route_query 函数根据之前的查询分类决定下一步。
具体来说,这一步会用一个 Router 对象更新状态,该对象的 type 变量包含以下值之一:“more-info”、“valid”或“general”。根据这些信息,工作流程将被路由到相应的节点(“create_research_plan”、“ask_for_more_info”或“respond_to_general_query”之一)。
asyncdefanalyze_and_route_query(state: AgentState, *, config: RunnableConfig) -> dict[str, Router]:
"""
分析当前智能体状态并确定下一步的路由逻辑。
参数:
state (AgentState):智能体的当前状态,包括消息和上下文。
config (RunnableConfig):运行配置。
返回:
dict[str, Router]:包含更新后的路由对象的字典。
"""
model = init_chat_model(
name="analyze_and_route_query", **app_config["inference_model_params"]
)
messages = [{"role": "system", "content": ROUTER_SYSTEM_PROMPT}] + state.messages
print("---ANALYZE AND ROUTE QUERY---")
print(f"MESSAGES: {state.messages}")
response = cast(
Router, await model.with_structured_output(Router).ainvoke(messages)
)
return {"router": response}
defroute_query(state: AgentState) -> Literal["create_research_plan", "ask_for_more_info", "respond_to_general_query"]:
"""
根据当前状态的路由类型确定智能体的下一步行动。
参数:
state (AgentState):智能体的当前状态,包括路由类型。
返回:
Literal["create_research_plan", "ask_for_more_info", "respond_to_general_query"]:
状态图中要执行的下一个节点/行动。
抛出:
ValueError:如果路由类型未知。
"""
_type = state.router.type
if _type == "valid":
return"create_research_plan"
elif _type == "more-info":
return"ask_for_more_info"
elif _type == "general":
return"respond_to_general_query"
else:
raise ValueError(f"Unknown router type {_type}")
对问题“推荐一些甜的食谱!”的输出示例:
{
"logic":"虽然提供了‘甜’的口味信息,但缺少其他强制性约束(饮食要求、用餐时间、食谱复杂性、餐点类型、烹饪时间和热量含量)。因此,需要更多信息才能推荐食谱。",
"type":"more-info"
}
请求被分类为“more-info”,因为它不包含提示中插入的所有强制性约束。
步骤 1.1:超出范围/需要更多信息
我们定义了 ask_for_more_info 和 respond_to_general_query 函数,它们通过调用 LLM 直接为用户生成回答:第一个函数在路由器确定需要更多用户信息时执行,第二个函数则为与主题无关的一般查询生成回答。在这种情况下,需要将生成的回答连接到消息列表中,更新状态中的 messages 变量。
asyncdefask_for_more_info(state: AgentState, *, config: RunnableConfig) -> dict[str, list[BaseMessage]]:
"""
根据当前路由逻辑向用户请求更多信息。
参数:
state (AgentState):智能体的当前状态,包括路由逻辑和消息。
config (RunnableConfig):运行配置。
返回:
dict[str, list[BaseMessage]]:包含请求更多信息的新消息的字典。
"""
model = init_chat_model(
name="ask_for_more_info", **app_config["inference_model_params"]
)
system_prompt = MORE_INFO_SYSTEM_PROMPT.format(logic=state.router.logic)
messages = [{"role": "system", "content": system_prompt}] + state.messages
response = await model.ainvoke(messages)
return {"messages": [response]}
asyncdefrespond_to_general_query(state: AgentState, *, config: RunnableConfig) -> dict[str, list[BaseMessage]]:
"""
根据智能体的当前状态和路由逻辑,为一般用户查询生成回答。
参数:
state (AgentState):智能体的当前状态,包括路由逻辑和消息。
config (RunnableConfig):运行配置。
返回:
dict[str, list[BaseMessage]]:包含生成的回答消息的字典。
"""
model = init_chat_model(
name="respond_to_general_query", **app_config["inference_model_params"]
)
system_prompt = GENERAL_SYSTEM_PROMPT.format(logic=state.router.logic)
print("---RESPONSE GENERATION---")
messages = [{"role": "system", "content": system_prompt}] + state.messages
response = await model.ainvoke(messages)
return {"messages": [response]}
对问题“慕尼黑的天气如何?”的输出示例:
{
"logic":"请求是关于慕尼黑当前天气的,与食谱、购物清单或超市产品位置用例无关。因此被分类为一般问题。",
"type":"general"
}
# ---RESPONSE GENERATION---
“我知道你想了解慕尼黑的天气,但我只能帮助处理食谱、食谱购物清单和超市中产品的位置。”
步骤 2:创建研究计划
如果查询分类返回“valid”,用户的请求与文档范围一致,工作流程将到达 create_research_plan 节点,该节点的函数会为与食物相关的查询创建一个逐步研究计划。
- •
review_research_plan:检查并改进研究计划的质量和相关性。 - •
reduce_research_plan:简化或压缩计划步骤,使其更高效。 - •
create_research_plan:协调整个过程,生成计划、压缩计划、审查计划并返回最终步骤。
asyncdefreview_research_plan(plan: Plan) -> Plan:
"""
审查研究计划以确保其质量和相关性。
参数:
plan (Plan):要审查的研究计划。
返回:
Plan:审查并可能修改后的研究计划。
"""
formatted_plan = ""
for i, step inenumerate(plan["steps"]):
formatted_plan += f"{i+1}. ({step['type']}): {step['question']}\n"
model = init_chat_model(
name="create_research_plan", **app_config["inference_model_params"]
)
system_prompt = REVIEW_RESEARCH_PLAN_SYSTEM_PROMPT.format(
schema=neo4j_graph.get_structured_schema, plan=formatted_plan
)
reviewed_plan = cast(
Plan, await model.with_structured_output(Plan).ainvoke(system_prompt)
)
return reviewed_plan
asyncdefreduce_research_plan(plan: Plan) -> Plan:
"""
通过简化或压缩步骤来减少研究计划。
参数:
plan (Plan):要减少的研究计划。
返回:
Plan:减少后的研究计划。
"""
formatted_plan = ""
for i, step inenumerate(plan["steps"]):
formatted_plan += f"{i+1}. ({step['type']}): {step['question']}\n"
model = init_chat_model(
name="reduce_research_plan", **app_config["inference_model_params"]
)
system_prompt = REDUCE_RESEARCH_PLAN_SYSTEM_PROMPT.format(
schema=neo4j_graph.get_structured_schema, plan=formatted_plan
)
reduced_plan = cast(
Plan, await model.with_structured_output(Plan).ainvoke(system_prompt)
)
return reduced_plan
asyncdefcreate_research_plan(
state: AgentState, *, config: RunnableConfig
) -> dict[str, list[str] | str]:
"""
根据智能体的当前知识和消息创建、减少和审查研究计划。
参数:
state (AgentState):智能体的当前状态,包括知识和消息。
config (RunnableConfig):运行配置。
返回:
dict[str, list[str] | str]:包含审查计划的最终步骤和空知识列表的字典。
"""
formatted_knowledge = "\n".join([item["content"] for item in state.knowledge])
model = init_chat_model(
name="create_research_plan", **app_config["inference_model_params"]
)
system_prompt = RESEARCH_PLAN_SYSTEM_PROMPT.format(
schema=neo4j_graph.get_structured_schema, context=formatted_knowledge
)
messages = [{"role": "system", "content": system_prompt}] + state.messages
print("---PLAN GENERATION---")
# 生成计划
plan = cast(Plan, await model.with_structured_output(Plan).ainvoke(messages))
print("Plan")
for i, step inenumerate(plan["steps"]):
print(f"{i+1}. ({step['type']}): {step['question']}")
# 减少计划
reduced_plan = cast(Plan, await reduce_research_plan(plan=plan))
print("Reduced Plan")
for i, step inenumerate(reduced_plan["steps"]):
print(f"{i+1}. ({step['type']}): {step['question']}")
# 审查计划
reviewed_plan = cast(Plan, await review_research_plan(plan=reduced_plan))
print("Reviewed Plan")
for i, step inenumerate(reviewed_plan["steps"]):
print(f"{i+1}. ({step['type']}): {step['question']}")
return {"steps": reviewed_plan["steps"], "knowledge": []}
对问题“推荐一些食谱。我是素食者,不知道早餐吃什么。热量要低于1000卡路里。没有其他偏好。”的输出示例:
{
"steps":
[
{"type":"semantic-search","question":"通过在 Diet 节点的 name 属性中搜索‘Vegetarian’来查找适合素食的食谱。"},
{"type":"semantic-search","question":"通过在 MealMoment 节点的 name 属性中搜索‘Breakfast’来查找适合早餐的食谱。"},
{"type":"query-search","question":"检索既是素食又在早餐时段提供的食谱,方法是取步骤1和步骤2结果的交集。过滤这些食谱,确保其包含的原料总热量低于1000卡路里。使用 CONTAINS 关系计算 FoodProduct 节点的总热量。限制50个。"}
]
}
在这个例子中,用户的请求需要三个步骤来检索信息。
步骤 3:进行研究
这个函数从研究计划中取第一个步骤并用它进行研究。研究过程中,函数调用 researcher_graph 子图,返回所有新收集的知识,我们将在下一节探讨。最后,我们通过移除刚执行的步骤来更新状态中的 steps 变量。
asyncdefconduct_research(state: AgentState) -> dict[str, Any]:
"""
使用研究图执行研究步骤并更新智能体的知识。
参数:
state (AgentState):智能体的当前状态,包括步骤和知识。
返回:
dict[str, Any]:包含更新后的知识和剩余步骤的字典。
"""
response = await research_graph.ainvoke(
{"step": state.steps[0], "knowledge": state.knowledge}
)
knowledge = response["knowledge"]
step = state.steps[0]
print(
f"\n{len(knowledge)} pieces of knowledge retrieved in total for the step: {step}."
)
return {"knowledge": knowledge, "steps": state.steps[1:]}
步骤 4:构建研究子图
研究图示
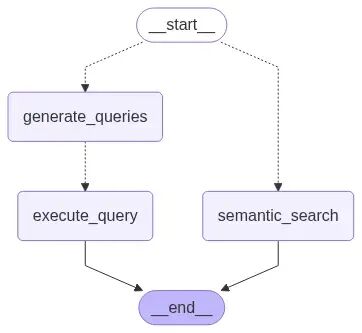
如上图所示,图谱包括:
- • 查询生成和执行步骤,或
- • 语义搜索步骤
与主图一样,我们继续定义状态 QueryState(研究图中 execute_query 节点的私有状态)和 ResearcherState(研究图的状态)。
@dataclass(kw_only=True)
classQueryState:
"""研究图中管理研究查询的状态类。"""
query: str
classStep(TypedDict):
"""单个研究步骤"""
question: str
type: Literal["semantic_search", "query_search"]
@dataclass(kw_only=True)
classResearcherState:
"""研究图的状态。"""
step: Step
queries: list[str] = field(default_factory=list)
knowledge: Annotated[list[dict], update_knowledge] = field(default_factory=list)
步骤 4.1:语义搜索
这一步骤在 Neo4j 图数据库上执行基于向量的语义搜索,根据相似性而非精确匹配来查找相关节点。
它由两个函数组成:
- •
semantic_search:使用 LLM 确定搜索参数并协调语义搜索的执行。 - •
execute_semantic_search:使用 OpenAI 嵌入和 Neo4j 的向量索引执行实际的向量相似性搜索。
defexecute_semantic_search(node_label: str, attribute_name: str, query: str):
"""在 Neo4j 向量索引上执行语义搜索。
此函数使用 OpenAI 嵌入执行基于向量的相似性搜索,查找与提供的查询语义相似的 Neo4j 图数据库中的节点。它将查询转换为嵌入向量,并在相应的向量索引中搜索最相似的节点。
参数:
node_label (str):要搜索的节点类型标签(例如,‘Recipe’,‘FoodProduct’)。
attribute_name (str):要在节点中搜索的属性(例如,‘name’,‘description’)。
query (str):查找语义相似内容的搜索查询。
返回:
list:包含匹配节点的属性字典列表,按相似性得分排序(从高到低)。
"""
index_name = f"{node_label.lower()}_{attribute_name}_index"
top_k = 1
query_embedding = (
openai.embeddings.create(model=app_config["embedding_model"], input=query)
.data[0]
.embedding
)
nodes = (
f"node.name as name, node.{attribute_name} as {attribute_name}"
if attribute_name != "name"
elsef"node.{{attribute_name}} as name"
)
response = neo4j_graph.query(
f"""
CALL db.index.vector.queryNodes('{index_name}', {top_k}, {query_embedding})
YIELD node, score
RETURN {nodes}
ORDER BY score DESC"""
)
print(
f"Semantic Search Tool invoked with parameters: node_label: '{node_label}', attribute_name: '{attribute_name}', query: '{query}'"
)
print(f"Semantic Search response: {response}")
return response
asyncdefsemantic_search(state: ResearcherState, *, config: RunnableConfig):
"""在研究图中执行语义搜索以查找相关节点。
此函数分析研究问题以确定最佳搜索参数,并在 Neo4j 图数据库上执行语义搜索。它使用 LLM 确定应搜索的节点类型和属性,然后执行基于向量的相似性搜索,查找可以帮助回答问题的语义相关内容。
参数:
state (ResearcherState):当前研究者状态,包含研究步骤问题和累积的知识。
config (RunnableConfig):运行配置。
返回:
dict[str, list]:包含语义搜索结果的“knowledge”键的字典,格式化为知识项。
"""
classResponse(TypedDict):
node_label: str
attribute_name: str
query: str
model = init_chat_model(
name="semantic_search", **app_config["inference_model_params"]
)
vector_indexes = neo4j_graph.query("SHOW VECTOR INDEXES YIELD name RETURN name;")
print(f"vector_indexes: {vector_indexes}")
system_prompt = SEMANTIC_SEARCH_SYSTEM_PROMPT.format(
schema=neo4j_graph.get_structured_schema,
vector_indexes=str(vector_indexes)
)
messages = [
{"role": "system", "content": system_prompt},
{"role": "human", "content": state.step["question"]},
]
response = cast(
Response, await model.with_structured_output(Response).ainvoke(messages)
)
sem_search_response = execute_semantic_search(
node_label=response["node_label"],
attribute_name=response["attribute_name"],
query=response["query"],
)
search_names = [f"'{record['name']}'"for record in sem_search_response]
joined_search_names = ", ".join(search_names)
knowledge = {
"id": new_uuid(),
"content": f"在 {response['node_label']}.{response['attribute_name']} 上执行语义搜索,查找与‘{response['query']}’相似的值\n结果:{joined_search_names}",
}
return {"knowledge": [knowledge]}
对生成步骤的输出示例:
[
{"type":"semantic_search","question":"通过在 Diet 节点的 name 属性中搜索‘Vegetarian’来查找适合素食的食谱。"},
{"type":"semantic_search","question":"通过在 MealMoment 节点的 name 属性中搜索‘Breakfast’来查找适合早餐的食谱。"}
]
# -- 新知识 --
Semantic Search Tool invoked with parameters: node_label: 'Diet', attribute_name: 'name', query: 'Vegetarian'
Semantic Search response: [{'name': 'Vegetarian'}]
Semantic Search Tool invoked with parameters: node_label: 'MealMoment', attribute_name: 'name', query: 'Breakfast'
Semantic Search response: [{'name': 'Breakfast'}]
步骤 4.2:生成查询
这一步骤根据研究计划中的问题(一个步骤)生成搜索查询。此函数使用 LLM 生成多样化的 Cypher 查询来帮助回答问题。它由三个函数组成:
- •
generate_queries:主函数,生成初始查询并应用两种校正方法。 - •
correct_query_by_llm:使用具有模式感知的语言模型校正 Cypher 查询。 - •
correct_query_by_parser:使用基于解析器的查询校正器进行结构校正。
asyncdefcorrect_query_by_llm(query: str) -> str:
"""使用语言模型校正 Cypher 查询。
此函数使用 LLM 根据 Neo4j 图谱模式审查和校正 Cypher 查询。它提供模式感知校正,确保查询格式正确并使用有效的关系和节点。
参数:
query (str):要校正的 Cypher 查询。
返回:
str:校正后的 Cypher 查询。
"""
model = init_chat_model(
name="correct_query_by_llm", **app_config["inference_model_params"]
)
system_prompt = FIX_QUERY_SYSTEM_PROMPT.format(
schema=neo4j_graph.get_structured_schema
)
messages = [
{"role": "system", "content": system_prompt},
{"role": "human", "content": query},
]
response = await model.ainvoke(messages)
return response.content
defcorrect_query_by_parser(query: str) -> str:
"""使用基于解析器的校正器校正 Cypher 查询。
此函数使用 CypherQueryCorrector 基于图谱模式解析和校正 Cypher 查询。它从文本中提取 Cypher 查询并应用结构校正。
参数:
query (str):包含要校正的 Cypher 查询的文本。
返回:
str:校正后的 Cypher 查询。
"""
corrector_schema = [
Schema(el["start"], el["type"], el["end"])
for el in neo4j_graph.get_structured_schema.get("relationships", [])
]
cypher_query_corrector = CypherQueryCorrector(corrector_schema)
extracted_query = extract_cypher(text=query)
corrected_query = cypher_query_corrector(extracted_query)
return corrected_query
asyncdefgenerate_queries(
state: ResearcherState, *, config: RunnableConfig
) -> dict[str, list[str]]:
"""为研究步骤生成和校正 Cypher 查询。
此函数根据研究问题和现有知识上下文生成多个 Cypher 查询。它使用 LLM 生成初始查询,然后应用基于 LLM 和基于解析器的校正,确保查询对 Neo4j 图数据库有效且格式正确。
参数:
state (ResearcherState):当前研究者状态,包含研究步骤问题和累积的知识。
config (RunnableConfig):运行配置。
返回:
dict[str, list[str]]:包含校正后 Cypher 查询列表的“queries”键的字典。
"""
classResponse(TypedDict):
queries: list[str]
print("---GENERATE QUERIES---")
formatted_knowledge = "\n\n".join(
[f"{i+1}. {item['content']}"for i, item inenumerate(state.knowledge)]
)
model = init_chat_model(
name="generate_queries", **app_config["inference_model_params"]
)
system_prompt = GENERATE_QUERIES_SYSTEM_PROMPT.format(
schema=neo4j_graph.get_schema, context=formatted_knowledge
)
messages = [
{"role": "system", "content": system_prompt},
{"role": "human", "content": state.step["question"]},
]
response = cast(
Response, await model.with_structured_output(Response).ainvoke(messages)
)
response["queries"] = [
await correct_query_by_llm(query=q) for q in response["queries"]
]
response["queries"] = [
correct_query_by_parser(query=q) for q in response["queries"]
]
print(f"Queries: {response['queries']}")
return {"queries": response["queries"]}
对问题(在语义搜索查询执行后)的输出示例:
“推荐一些食谱。我是素食者,不知道早餐吃什么。热量要低于1000卡路里。没有其他偏好。”
MATCH (r:Recipe)-[:FITS_DIET]->(:Diet {name: 'Vegetarian'}),
(r)-[:SERVED_DURING]->(:MealMoment {name: 'Breakfast'}),
(r)-[c:CONTAINS]->(fp:FoodProduct)
WITH r, SUM(c.grams * (fp.calories / 100.0)) AS total_calories
WHERE total_calories < 1000
RETURN r.name AS recipe_name, total_calories
LIMIT 5
执行后的输出:
# -- 新知识 --
╒════════════════════════════╤══════════════════╕
│recipe_name │total_calories
╞════════════════════════════╪══════════════════╡
│"Mascarpone Dessert" │945.8000000000001
├────────────────────────────┼──────────────────┤
│"Buffalo Mozzarella Salad" │668.88
├────────────────────────────┼──────────────────┤
│"Raisin and Almond Snack" │374.69999999999993
├────────────────────────────┼──────────────────┤
│"Mozzarella and Basil Salad"│528.4
└────────────────────────────┴──────────────────┘
步骤 4.3:构建子图
defbuild_research_graph():
builder = StateGraph(ResearcherState)
builder.add_node(generate_queries)
builder.add_node(execute_query)
builder.add_node(semantic_search)
builder.add_conditional_edges(
START,
route_step,
{"generate_queries": "generate_queries", "semantic_search": "semantic_search"},
)
builder.add_conditional_edges(
"generate_queries",
query_in_parallel, # type: ignore
path_map=["execute_query"],
)
builder.add_edge("execute_query", END)
builder.add_edge("semantic_search", END)
return builder.compile()
research_graph = build_research_graph()
步骤 5:检查完成
使用条件边(conditional_edge),我们构建了一个循环,其结束条件由 check_finished 函数的返回值决定。此函数检查由 create_research_plan 节点创建的步骤列表中是否还有步骤需要处理。一旦所有步骤完成,流程将进入 respond 节点。
defcheck_finished(state: AgentState) -> Literal["respond", "conduct_research"]:
"""
根据已执行的步骤确定智能体是应该回答还是继续研究。
参数:
state (AgentState):智能体的当前状态,包括已执行的步骤。
返回:
Literal["respond", "conduct_research"]:
如果还有步骤,则为“conduct_research”,否则为“respond”。
"""
iflen(state.steps or []) > 0:
return"conduct_research"
else:
return"respond"
步骤 6:回答
根据进行的研究生成对用户查询的最终回答。此函数使用对话历史和研究者智能体检索的文档,制定全面的回答。
asyncdefrespond(
state: AgentState, *, config: RunnableConfig
) -> dict[str, list[BaseMessage]]:
"""
根据智能体的累积知识和消息为用户生成最终回答。
参数:
state (AgentState):智能体的当前状态,包括知识和消息。
config (RunnableConfig):运行配置。
返回:
dict[str, list[BaseMessage]]:包含生成的回答消息的字典。
"""
print("--- RESPONSE GENERATION STEP ---")
model = init_chat_model(name="respond", **app_config["inference_model_params"])
formatted_knowledge = "\n\n".join([item["content"] for item in state.knowledge])
prompt = RESPONSE_SYSTEM_PROMPT.format(context=formatted_knowledge)
messages = [{"role": "system", "content": prompt}] + state.messages
response = await model.ainvoke(messages)
return {"messages": [response]}
步骤 7:构建主图
defbuild_main_graph():
builder = StateGraph(AgentState, input=InputState)
builder.add_node(analyze_and_route_query)
builder.add_node(ask_for_more_info)
builder.add_node(respond_to_general_query)
builder.add_node(create_research_plan)
builder.add_node(conduct_research)
builder.add_node("respond", respond)
builder.add_edge("create_research_plan", "conduct_research")
builder.add_edge(START, "analyze_and_route_query")
builder.add_conditional_edges("analyze_and_route_query", route_query)
builder.add_conditional_edges("conduct_research", check_finished)
builder.add_edge("respond", END)
return builder.compile()
结果
我们可以通过以下问题测试其性能:
“给我‘pasta alla carbonara’食谱的购物清单。”
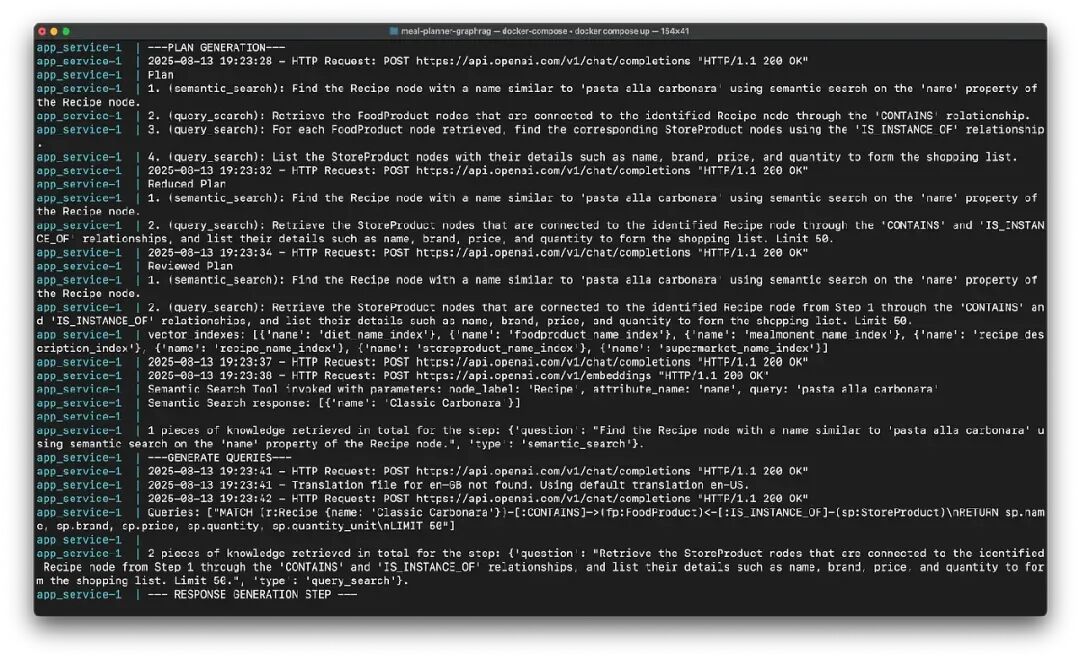
控制台日志
从控制台日志中可以看到,主图创建了以下审查计划:
-
- semantic_search:通过在 Recipe 节点的‘name’属性上进行语义搜索,查找名称类似于‘pasta alla carbonara’的 Recipe 节点。
-
- query_search:检索通过步骤1识别的 Recipe 节点,通过‘CONTAINS’和‘IS_INSTANCE_OF’关系连接的 StoreProduct 节点,并列出其详细信息,如名称、品牌、价格和数量,形成购物清单。限制50个。
执行第一步后,我们得知与‘pasta alla carbonara’对应的 Recipe 节点的准确名称是‘Classic Carbonara’。
app_service-1 | Semantic Search Tool invoked with parameters: node_label: 'Recipe', attribute_name: 'name', query: 'pasta alla carbonara'
app_service-1 | Semantic Search response: [{'name': 'Classic Carbonara'}]
然后执行第二步,使用以下 Cypher 查询:
MATCH (r:Recipe {name: 'Classic Carbonara'})-[:CONTAINS]->(fp:FoodProduct)<-[:IS_INSTANCE_OF]-(sp:StoreProduct)
RETURN sp.name, sp.brand, sp.price, sp.quantity, sp.quantity_unit
LIMIT 50
然后我们得到最终回答。

实时演示 — 使用 Chainlit 制作的 UI
通过检查图谱内容,我们看到完整的结果是正确的。
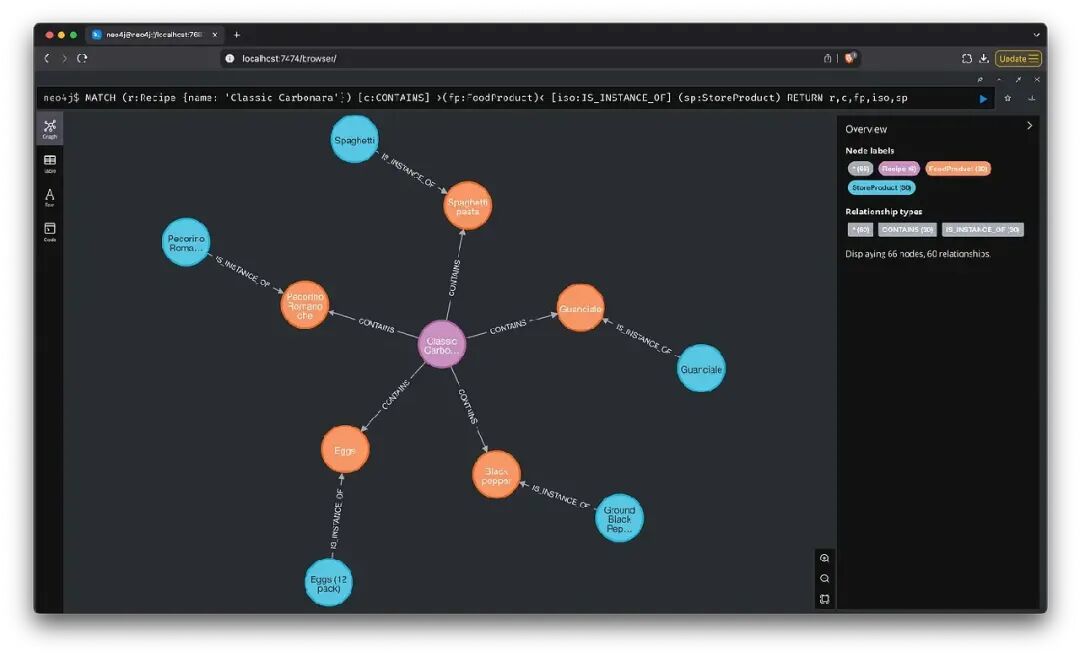
结论
Graph RAG:技术挑战与考虑
尽管性能有所提升,实施 Graph RAG 并非没有挑战:
- • 延迟:智能体交互的复杂性增加通常会导致响应时间更长。在速度和准确性之间找到平衡是一个关键挑战。
- • 评估与可观察性:随着 Agentic RAG 系统变得更加复杂,持续的评估和可观察性变得必要。
总之,Graph RAG 在 AI 领域标志着重大突破。通过将大语言模型的能力与自主推理和信息检索相结合,Graph RAG 引入了新的智能和灵活性标准。随着 AI 的持续发展,Graph RAG 将在各行各业中扮演重要角色,改变我们使用技术的方式。
Github 仓库地址:
https://github.com/PulsarPioneers/meal-planner-graphrag
如何学习AI大模型 ?
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。【保证100%免费】🆓
CSDN粉丝独家福利
这份完整版的 AI 大模型学习资料已经上传CSDN,朋友们如果需要可以扫描下方二维码&点击下方CSDN官方认证链接免费领取 【保证100%免费】
读者福利: 👉👉CSDN大礼包:《最新AI大模型学习资源包》免费分享 👈👈
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
👉1.大模型入门学习思维导图👈
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
对于从来没有接触过AI大模型的同学,我们帮你准备了详细的学习成长路线图&学习规划。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。(全套教程文末领取哈)
👉2.AGI大模型配套视频👈
很多朋友都不喜欢晦涩的文字,我也为大家准备了视频教程,每个章节都是当前板块的精华浓缩。

👉3.大模型实际应用报告合集👈
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(全套教程文末领取哈)

👉4.大模型实战项目&项目源码👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战项目来学习。(全套教程文末领取哈)
👉5.大模型经典学习电子书👈
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。(全套教程文末领取哈)
👉6.大模型面试题&答案👈
截至目前大模型已经超过200个,在大模型纵横的时代,不仅大模型技术越来越卷,就连大模型相关的岗位和面试也开始越来越卷了。为了让大家更容易上车大模型算法赛道,我总结了大模型常考的面试题。(全套教程文末领取哈)
为什么分享这些资料?
只要你是真心想学AI大模型,我这份资料就可以无偿分享给你学习,我国在这方面的相关人才比较紧缺,大模型行业确实也需要更多的有志之士加入进来,我也真心希望帮助大家学好这门技术,如果日后有什么学习上的问题,欢迎找我交流,有技术上面的问题,我是很愿意去帮助大家的!
这些资料真的有用吗?
这份资料由我和鲁为民博士共同整理,鲁为民博士先后获得了北京清华大学学士和美国加州理工学院博士学位,在包括IEEE Transactions等学术期刊和诸多国际会议上发表了超过50篇学术论文、取得了多项美国和中国发明专利,同时还斩获了吴文俊人工智能科学技术奖。目前我正在和鲁博士共同进行人工智能的研究。
资料内容涵盖了从入门到进阶的各类视频教程和实战项目,无论你是小白还是有些技术基础的,这份资料都绝对能帮助你提升薪资待遇,转行大模型岗位。


CSDN粉丝独家福利
这份完整版的 AI 大模型学习资料已经上传CSDN,朋友们如果需要可以扫描下方二维码&点击下方CSDN官方认证链接免费领取 【保证100%免费】
读者福利: 👉👉CSDN大礼包:《最新AI大模型学习资源包》免费分享 👈👈

一座年轻的奋斗人之城,一个温馨的开发者之家。在这里,代码改变人生,开发创造未来!
更多推荐
 17
17 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)