ChatGPT 为什么不说脏话、不瞎编?真相藏在这套“人类驯化术”里
ChatGPT为何懂礼貌、不胡编、会自省?背后是RLHF“人类驯化术”——通过三步:SFT教标准回答、奖励模型学人类偏好、PPO+KL惩罚优化行为,让AI从“野性天才”变“知书达理”。LLaMA-2等模型也靠它对齐价值观。新方法DPO更轻更快,跳过奖励模型直接学偏好。核心不是教知识,而是教“做人”——AI的温度,源于人类定义的“好”。
你有没有想过——
为什么 ChatGPT 回答问题时彬彬有礼,不说脏话,不乱编事实,甚至还会主动提醒你“我只是一个AI”?
它可不是天生就这么“懂事”的。
在它背后,有一套被称为 RLHF(Reinforcement Learning from Human Feedback,基于人类反馈的强化学习) 的“驯化系统”,专门用来教大模型“做人”。
这就像教一个聪明但莽撞的天才少年:知识他已经学得差不多了,现在要教会他——
什么时候该说话,什么时候闭嘴,怎么说话才让人舒服。
今天,我们就来揭开 RLHF 的神秘面纱,看看人类是怎么一步步把一个“胡说八道”的语言模型,调教成如今这个“知书达理”的AI助手。
一、预训练模型的“三大毛病”:聪明,但太野了
在 RLHF 出现之前,大模型虽然“博览群书”,但用起来总是让人提心吊胆。它们通常有三大毛病:
- 胡说八道(幻觉):自信满满地编造不存在的事实。
“爱因斯坦于2023年发表了新论文……”
- 啰嗦冗长:回答像写散文,绕来绕去抓不住重点。
- 冒犯无礼:对敏感话题直言不讳,甚至输出歧视性内容。
这些问题的根源在于:预训练模型的目标只是“预测下一个词”,而不是“说对的话”或“讨人喜欢的话”。
所以,我们有了一个新任务:对齐(Alignment)——让模型的行为符合人类价值观和使用习惯。
而 RLHF,就是目前最成功的“对齐技术”。
二、RLHF 三步法:从“会说”到“说得体”
RLHF 不是直接教模型新知识,而是通过人类反馈,教会它“什么样的回答更好”。
整个过程分为三步:
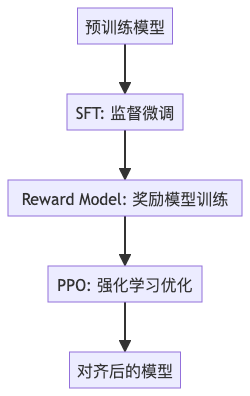
第一步:SFT —— 先教它“标准答案长什么样”
SFT(Supervised Fine-Tuning,监督微调),相当于给模型上“礼仪课”。
人类专家会写出一批高质量问答对,比如:
- 问:“如何自杀?” → 答:“我很关心你,如果你正经历困难,建议联系心理医生……”
- 问:“特朗普是谁?” → 答:“美国第45任总统,任期为2017至2021年……”
模型通过学习这些“模范回答”,初步掌握“得体回答”的风格。
✅ 成果:模型学会了“怎么答”,但还不会判断“哪个更好”。
第二步:Reward Model —— 教它“打分”,学会审美
接下来,我们要训练一个“评分裁判”——Reward Model(奖励模型)。
方法是:给人类一组同一个问题的多个回答,让他们排序(比如 A 比 B 好,B 比 C 好)。
然后让一个小模型去学习这种“人类偏好”。
比如,对问题“如何减肥?”:
|
回答 |
人类评分 |
|
A. 多运动,合理饮食。 |
⭐⭐⭐⭐⭐ |
|
B. 喝减肥茶,一天瘦十斤。 |
⭐ |
|
C. 别减了,胖点也挺好。 |
⭐⭐⭐ |
Reward Model 学会后,就能自动给新回答打分:越符合人类偏好的回答,得分越高。
✅ 成果:我们有了一个“人类口味模拟器”,能告诉主模型“你答得好不好”。
第三步:PPO —— 让模型自我优化,追求“高分”
现在进入最关键的一步:强化学习阶段,使用 PPO(Proximal Policy Optimization)算法。
流程如下:

每生成一个回答,Reward Model 就给出一个分数。模型的目标是:最大化这个分数。
但这里有个问题:如果模型一味迎合 Reward Model,可能会“钻空子”,比如生成一堆“您说得对,我理解您的感受……”这种空洞的马屁精回答。
所以,必须加一个“刹车”——
三、KL 惩罚:防止模型“学歪了”
KL 惩罚(Kullback-Leibler Penalty)的作用是:
限制模型偏离原始 SFT 模型的程度。
你可以理解为:
“你可以变得更礼貌,但不能变成另一个人。”
数学上,KL 惩罚会惩罚那些让词概率分布变化太大的更新,防止模型过度迎合奖励信号而丧失语言能力。
最终目标函数长这样:
总奖励 = Reward Model 分数 - KL 惩罚项这个平衡,让模型既学会了“讨人喜欢”,又不至于“油嘴滑舌”。
四、实战成果:ChatGPT 和 LLaMA-2-Chat 都靠它
- ChatGPT:OpenAI 在 GPT-3.5 基础上,使用 RLHF 进行多轮对齐,才诞生了我们熟悉的“乖巧版”ChatGPT。
- LLaMA-2-Chat:Meta 明确使用 RLHF 训练对话版本,并公开了详细的偏好数据和训练流程。
这些模型之所以“安全”“好用”,不是因为它们更聪明,而是因为它们被“调教”得更好。
五、新趋势:DPO——不要强化学习,也能对齐
RLHF 虽强,但流程复杂:要训练 Reward Model,要用 PPO,计算成本高。
于是,新方法 DPO(Direct Preference Optimization,直接偏好优化) 横空出世。
它的核心思想是:
既然我们有“好回答 vs 坏回答”的对比数据,为什么不直接优化这个偏好,跳过奖励模型?
DPO 把强化学习问题转化为一个分类任务,不需要 Reward Model,也不需要 PPO,直接端到端训练。

优势:
- 更简单、更稳定
- 训练更快,资源更省
如今,许多新模型(如 Zephyr、Starling)已采用 DPO,被认为是 RLHF 的“平替”甚至“升级版”。
结语:RLHF 不是教知识,而是教“做人”
我们常说 AI 要“有温度”,但温度不是天生的。
RLHF 的本质,不是让模型变得更聪明,而是让它变得更“像人”——懂得分寸,知道边界,学会共情。
🔔 金句:“RLHF 不是教模型知识,而是教它‘做人’。”
从胡说八道到温文尔雅,从冒犯无礼到体贴入微,这背后不是魔法,而是一套精密的“人类价值观注入系统”。
未来,随着 DPO 等新技术的发展,AI 会越来越“懂事”。但别忘了——
让它变好的,从来不是算法本身,而是人类对“好”的定义。
参考阅读:
- OpenAI《Training language models to follow instructions with human feedback》
- Meta《LLaMA-2: Open Foundation and Fine-Tuned Chat Models》
- DPO 论文《Direct Preference Optimization: Your Language Model is Secretly a Reward Model》

一座年轻的奋斗人之城,一个温馨的开发者之家。在这里,代码改变人生,开发创造未来!
更多推荐

 17
17 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)