用SDK跑通了一个具身智能交互方案
目录
- 前言:数字人赛道很热,但落地很冷
- 一、数字人落地的三个技术硬伤
- 二、参数流:换一条技术路线
- 三、实战接入:30分钟跑通一个具身智能数字人
- 四、户外出行向导场景的深度探索
- 五、关于具身智能交互的思考
- 六、实际体验总结
用SDK跑通了一个具身智能交互方案
从技术瓶颈到实战接入,聊聊为什么参数流才是数字人真正可落地的解法
主题方向:数字人落地
前言:数字人赛道很热,但落地很冷
2025年到现在,AI圈子最不缺的就是"数字人"。各大厂商都在推,开发者群里天天有人问方案,但真到落地的项目,大家不约而同卡在了同一个问题:交互体验撑不起业务场景。
“数字人要像真人一样能对话、能打断、能接话”。对比市面各类数字人方案后,最终依托AI 终端时代全域具身交互底层基础设施 —— 魔珐星云,搭配轻量化具身驱动 SDK 完成完整落地实践,平台以自研 LAM 文生 3D 多模态大模型为核心底座,补齐纯文本大模型缺失的具象交互载体短板。这篇文章把跑通整个选型思考和技术实践过程记录下来,给同样在做数字人落地的朋友一个参考。
大家可以使用平台感受一下实际交互效果:3D数字人
一、数字人落地的三个技术硬伤
先说说为什么现有方案落地困难。对于选型,核心痛点集中在三个地方:
1. 视频流架构的延迟困局
目前市面上大多数数字人走的是视频流方案——云端渲染出视频帧,通过WebRTC或类似协议推到前端播放。这个链路是:用户语音 → ASR → 大模型推理 → TTS合成 → 云端渲染视频帧 → 编码推流 → 前端解码播放。
算一下每一步的耗时,ASR约200-400ms,大模型首token约300-800ms,TTS合成约200-500ms,云端渲染+编码约100-300ms,推流+解码约100-300ms。整个链路下来,端到端延迟普遍在2-5秒。用户说完一句话,等两三秒才看到反应,这在展厅、门店这种需要即时互动的场景里根本没法用。
而且视频流方案要持续传输视频帧数据,带宽成本高、并发上限低。一个政务大厅5块屏幕同时跑就已经需要专线网络了。
2. 交互打断的"伪实时"
很多数字人方案号称"支持打断",但底层还是视频流,打断的实质是切断当前视频流、重新请求新的视频流。这意味着用户打断后,还得再走一遍完整的渲染-推流链路,实际体验就是"打断后卡顿一秒,然后接上新的回答"。这种打断是协议层的切断,不是语义层的实时切换。
真正自然的交互打断是什么?是对方说到一半你插嘴,对方立刻停住、表情变化、然后接上你的新话题。这是真人对话的节奏,也是具身智能交互的基本要求。
3. 云端渲染的成本悖论
视频流方案依赖云端GPU渲染,这意味着每一路并发都需要一块GPU的算力。做一个连锁门店的项目,100块屏幕 = 100路并发 = 至少十几块A100,月成本直接奔着六位数去了。用户一听报价就摇头,落地自然就黄了。
这就是数字人落地的核心矛盾:要交互体验就得低延迟,低延迟就得实时渲染,实时渲染用视频流就得烧GPU,烧GPU就推高成本,成本高就落不了地。
二、参数流:换一条技术路线
魔珐星云的技术路线和视频流方案有本质区别,它走的是参数流。
简单说,视频流是"云端画好每一帧图片,传给你看";参数流是"云端算好表情参数和动作参数,传给你的设备自己画"。这个区别非常关键:
- 数据量:一帧视频是几百KB到几MB,一组参数只有几KB,数据量差了两个数量级
- 渲染位置:视频流在云端渲染,参数流在端侧渲染(即AI端渲)
- 带宽要求:参数流对网络带宽的需求极低,弱网环境也能跑
- 并发能力:云端不承担渲染压力,所以可以支撑千万级屏幕同时在线
更关键的是,参数流架构下配合AI端侧解算技术,从用户说话到数字人做出反应的完整链路,端到端≈500ms。这个数字在视频流方案里是不可想象的。
我去理解这个技术架构的时候画了张图:
传统视频流架构:
用户 → ASR → 大模型 → TTS → 云端GPU渲染 → 视频编码 → WebRTC推流 → 前端解码播放
↑ 瓶颈:GPU+带宽+延迟
魔珐星云参数流架构:
用户 → ASR → 大模型 → TTS + 表情/动作参数生成 → 参数流传输 → 端侧AI渲染 → 直接呈现
↑ 优势:几KB参数 + 端侧渲染 + 低延迟
参数流之所以能做到低延迟,核心是把渲染这件事从云端搬到了端侧。而AI端渲和端侧解算技术,让百元级的硬件芯片就能跑起来3D数字人的实时渲染,不需要GPU,不需要游戏引擎。这就是为什么星云能做到低成本、低延迟、高并发——三个在视频流方案里互斥的指标,在参数流架构下同时满足了。
三、实战接入:30分钟跑通一个具身智能数字人
接下来上代码。我这次选的场景是门店导购——在零售门店的屏幕上放一个可以实时对话的数字人导购,用户可以直接问产品信息、查库存、要推荐。
开发工具和模型选型
先说技术栈:
- AI Coding工具:trae + Claude 3.5 Sonnet,用来快速搭建前端项目框架和调试代码
- 大模型:豆包 1.5 pro作为数字人的对话大脑,通过星云SDK的流式speak接口对接
- 星云SDK:具身驱动JS SDK,负责数字人渲染、语音合成和驱动
- 前端:原生HTML + JavaScript,极简方案,方便移植到各种终端
Step 1:在魔珐星云平台创建应用
登录魔珐星云平台,进入应用中心,创建一个"具身驱动"应用。在这里选择数字人角色、音色和表演风格。
截图位置:平台应用中心创建驱动应用的界面
创建完成后,你会拿到 appId 和 appSecret,这是后续接入的凭证。
Step 2:极简Demo代码
下面是一个完整的可运行Demo,实现了"用户输入文字 → DeepSeek大模型流式回复 → 星云数字人实时说话"的完整链路:
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>魔珐星云 × 豆包 具身智能数字人 Demo</title>
<style>
* { margin: 0; padding: 0; box-sizing: border-box; }
body {
display: flex;
height: 100vh;
background: #1a1a2e;
font-family: -apple-system, BlinkMacSystemFont, sans-serif;
}
.avatar-container {
flex: 1;
position: relative;
}
.chat-panel {
width: 400px;
background: #16213e;
display: flex;
flex-direction: column;
border-left: 1px solid #0f3460;
}
.chat-header {
padding: 16px 20px;
background: #0f3460;
color: #e94560;
font-size: 16px;
font-weight: 600;
}
.chat-messages {
flex: 1;
overflow-y: auto;
padding: 16px;
}
.msg {
margin-bottom: 12px;
padding: 10px 14px;
border-radius: 8px;
max-width: 85%;
font-size: 14px;
line-height: 1.5;
}
.msg-user {
background: #e94560;
color: white;
margin-left: auto;
}
.msg-bot {
background: #0f3460;
color: #eee;
}
.chat-input {
display: flex;
padding: 12px;
gap: 8px;
border-top: 1px solid #0f3460;
}
.chat-input input {
flex: 1;
padding: 10px 14px;
border-radius: 8px;
border: 1px solid #0f3460;
background: #1a1a2e;
color: #eee;
font-size: 14px;
outline: none;
}
.chat-input input:focus {
border-color: #e94560;
}
.chat-input button {
padding: 10px 20px;
border-radius: 8px;
border: none;
background: #e94560;
color: white;
font-size: 14px;
cursor: pointer;
transition: background 0.2s;
}
.chat-input button:hover {
background: #c73a50;
}
.chat-input button:disabled {
background: #555;
cursor: not-allowed;
}
</style>
</head>
<body>
<!-- 数字人渲染容器 -->
<div class="avatar-container">
<div id="sdk" style="width: 100%; height: 100%;"></div>
</div>
<!-- 对话面板 -->
<div class="chat-panel">
<div class="chat-header">AI门店导购 · 具身智能数字人</div>
<div class="chat-messages" id="chatMessages"></div>
<div class="chat-input">
<input type="text" id="userInput" placeholder="试试问:有什么推荐?" />
<button id="sendBtn" onclick="handleSend()">发送</button>
</div>
</div>
<!-- 引入星云SDK -->
<script src="https://media.xingyun3d.com/xingyun3d/general/litesdk/xmovAvatar@latest.js"></script>
<script>
// ==================== 配置区 ====================
const APP_ID = 'your_appid'; // 替换为你的appId
const APP_SECRET = 'your_appsecret'; // 替换为你的appSecret
const DEEPSEEK_API_KEY = 'your_key'; // 替换为你的DeepSeek API Key
const DEEPSEEK_URL = 'https://api.deepseek.com/chat/completions';
// 门店导购的系统提示词
const SYSTEM_PROMPT = `你是一位专业的门店AI导购,名叫小星。
你的职责是热情、专业地为顾客推荐商品,回答产品相关问题。
回答要简洁自然,像真人导购一样口语化,每句话控制在50字以内。`;
// ==================== 初始化星云数字人 ====================
let avatar = null;
let isSpeaking = false;
function initAvatar() {
avatar = new XmovAvatar({
containerId: '#sdk',
appId: APP_ID,
appSecret: APP_SECRET,
gatewayServer: 'https://nebula-agent.xingyun3d.com/user/v1/ttsa/session',
hardwareAcceleration: 'prefer-hardware', // 开启硬件加速,提升渲染性能
onStateChange(state) {
console.log('[数字人状态]', state);
},
onMessage(msg) {
console.log('[SDK消息]', msg);
},
onStatusChange(status) {
console.log('[连接状态]', status);
},
onVoiceStateChange(status) {
// 监控语音播放状态,用于控制对话节奏
if (status === 'start') isSpeaking = true;
if (status === 'end') isSpeaking = false;
console.log('[语音状态]', status);
},
enableLogger: false,
});
// 连接并初始化数字人
avatar.initModel({
onDownloadProgress(progress) {
console.log(`[资源加载] ${progress}%`);
}
}, 'normal');
}
// ==================== 对接大模型 + 流式驱动数字人 ====================
async function streamChat(userMessage) {
appendMessage('user', userMessage);
const response = await fetch(DEEPSEEK_URL, {
method: 'POST',
headers: {
'Content-Type': 'application/json',
'Authorization': `Bearer ${DEEPSEEK_API_KEY}`,
},
body: JSON.stringify({
model: 'deepseek-chat',
messages: [
{ role: 'system', content: SYSTEM_PROMPT },
{ role: 'user', content: userMessage },
],
stream: true, // 开启流式输出
}),
});
const reader = response.body.getReader();
const decoder = new TextDecoder();
let fullText = '';
let buffer = '';
let isFirstChunk = true;
while (true) {
const { done, value } = await reader.read();
if (done) break;
buffer += decoder.decode(value, { stream: true });
const lines = buffer.split('\n');
buffer = lines.pop(); // 保留未完成的行
for (const line of lines) {
if (!line.startsWith('data: ') || line === 'data: [DONE]') continue;
try {
const json = JSON.parse(line.slice(6));
const content = json.choices?.[0]?.delta?.content;
if (!content) continue;
fullText += content;
// 关键:通过 is_start / is_end 控制流式驱动
// 星云SDK的speak方法支持流式调用,与大模型的流式输出天然适配
if (isFirstChunk) {
// 积攒一小段内容后再首次调用,确保语速稳定
if (fullText.length >= 6) {
avatar.speak(fullText, true, false); // is_start=true
isFirstChunk = false;
}
}
} catch (e) { /* 忽略解析异常 */ }
}
}
// 最后一次speak,is_end=true,表示本段回答结束
if (fullText.length > 0) {
if (isFirstChunk) {
// 内容很短,直接一次性发送
avatar.speak(fullText, true, true);
} else {
avatar.speak('', false, true); // is_end=true
}
}
appendMessage('bot', fullText);
document.getElementById('sendBtn').disabled = false;
}
// ==================== UI辅助 ====================
function appendMessage(role, text) {
const div = document.createElement('div');
div.className = `msg msg-${role === 'user' ? 'user' : 'bot'}`;
div.textContent = text;
document.getElementById('chatMessages').appendChild(div);
document.getElementById('chatMessages').scrollTop = 99999;
}
function handleSend() {
const input = document.getElementById('userInput');
const text = input.value.trim();
if (!text || isSpeaking) return;
input.value = '';
document.getElementById('sendBtn').disabled = true;
streamChat(text);
}
// 回车发送
document.getElementById('userInput').addEventListener('keydown', (e) => {
if (e.key === 'Enter') handleSend();
});
// 页面加载后初始化
window.addEventListener('load', initAvatar);
// 页面卸载前释放资源
window.addEventListener('beforeunload', () => {
if (avatar) avatar.destroy();
});
</script>
</body>
</html>
Step 3:代码核心逻辑解读
这个Demo的核心就是星云SDK的speak流式调用和大模型流式输出的对接。
星云SDK的 speak(ssml, is_start, is_end) 方法设计了三个关键参数:
| 参数 | 含义 |
|---|---|
ssml |
要说的文字内容,支持SSML标记语言控制KA动作 |
is_start |
是否是本次回答的第一段语音 |
is_end |
是否是本次回答的最后一段语音 |
这和大模型的SSE流式输出天然适配——大模型每吐出一个token片段,就可以直接喂给speak方法驱动数字人说话。不需要等大模型生成完整个回答再开始播报,而是"边生成边说",这正是参数流架构实现低延迟的关键之一。
代码里有两个实践要点:
1. 首次speak积攒一小段内容:避免大模型刚开始输出时token过碎导致数字人说话节奏不均匀
2. speak结束后用 `interactive_idle()` 切换状态:回到待机互动状态,为下一次对话做准备(代码中可按需添加)
Step 4:加入SSML让数字人更生动
星云支持SSML标记语言,可以让数字人在说话的同时做出特定动作(KA,即Key Animation):
// 数字人边说欢迎语边做欢迎动作
avatar.speak(
`<speak>
<ue4event>
<type>ka_intent</type>
<data><ka_intent>Welcome</ka_intent></data>
</ue4event>
欢迎光临!今天店里新品上架,我帮您看看有什么感兴趣的吧~
</speak>`,
true,
true
);
// 数字人做舞蹈动作
avatar.speak(
`<speak>
<ue4event>
<type>ka</type>
<data><action_semantic>dance</action_semantic></data>
</ue4event>
</speak>`,
true,
true
);
通过KA指令,数字人不再只是"站着说话",而是可以配合语义做出挥手、欢迎、舞蹈等动作,真正实现具身智能交互——不只是语音回应,而是有表情、有肢体联动的完整拟人表达。
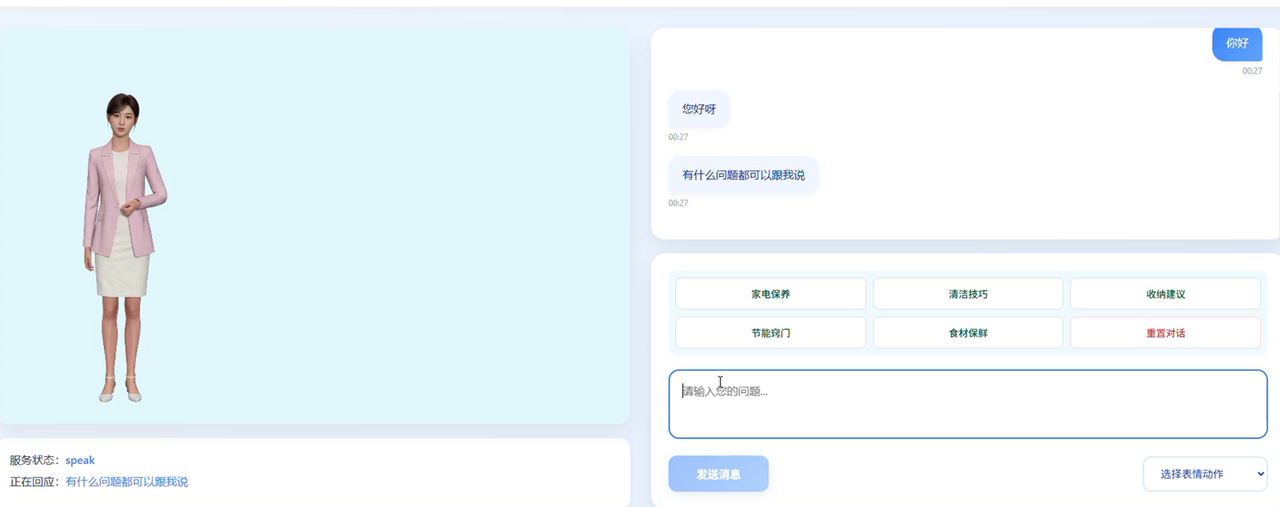
四、户外出行向导场景的深度探索
上面是基础Demo,真实落地时还需要考虑更多业务细节。我在出行导引这个场景上做了比较深入的探索。
1. 主动迎宾 + 被动响应的双模态
出行场景有一个特殊性:顾客经过时数字人要主动打招呼,顾客停留后要能即时对话。星云SDK提供了状态管理API来支持这种双模态:
<template>
<div class="travel-container">
<!-- 顶部导航 -->
<header class="header">
<div class="logo-area">
<div class="logo-icon">
<svg viewBox="0 0 24 24" fill="none" stroke="currentColor" stroke-width="2">
<path d="M12 2L2 7l10 5 10-5-10-5z"/>
<path d="M2 17l10 5 10-5"/>
<path d="M2 12l10 5 10-5"/>
</svg>
</div>
<div class="logo-text">
<h1>户外出行向导</h1>
<p class="subtitle">轻旅行 · 周边游专属数字人</p>
</div>
</div>
...
</header>
<!-- 主内容区 -->
<div class="main-content">
<!-- 数字人展示区 -->
<div class="avatar-section">
<div class="avatar-container">
<div :id="containerId" class="avatar-render-area"></div>
...
</div>
<!-- 旅行状态面板 -->
<div class="status-panel">...</div>
</div>
<!-- 交互区 -->
<div class="interaction-section">
<!-- 功能标签页 -->
<div class="tab-bar">
<button v-for="tab in tabs" :key="tab.id"
:class="['tab-btn', { active: activeTab === tab.id }]"
@click="activeTab = tab.id">
<span class="tab-icon">{{ tab.icon }}</span>
<span class="tab-label">{{ tab.label }}</span>
</button>
</div>
<!-- 对话记录 -->
<div class="chat-history" ref="chatContainer">...</div>
<!-- 输入控制区 -->
<div class="input-controls">...</div>
</div>
</div>
<!-- 底部状态栏 -->
<footer class="footer">...</footer>
</div>
</template>
状态流转是:idle(待机)→ interactive_idle(待机互动)→ speak(说话)→ interactive_idle → idle。这套状态机设计很清晰,和出行导引的实际业务节奏完全对得上。
2. 多大模型灵活切换
星云SDK本身不绑定特定大模型,speak方法接收的是文本输入,所以你可以自由选择对话大脑。在门店场景里,我的做法是:
- 日常出行问答:豆包1.5pro,性价比高,响应快
- 专业产品咨询:可以接入企业自有知识库 + RAG,保证回答的专业性和准确性
- 多语言场景(如免税店):接入支持多语言的模型
切换大模型对星云SDK来说没有任何感知,因为它只关心"喂进来什么文本",不管文本从哪来。这种SDK轻量化接入联动主流大模型的设计,极大降低了技术选型的耦合度。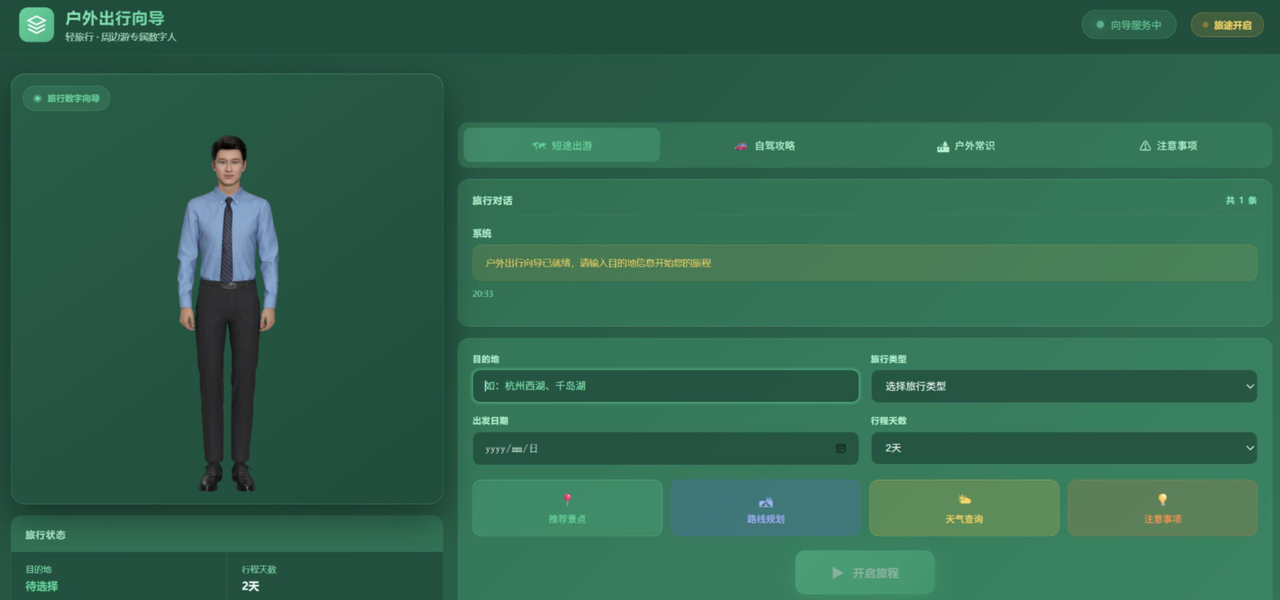
3. 硬件成本的实测
这是我实际测算的成本对比(以100块门店屏幕为例):
| 项目 | 视频流方案 | 星云参数流方案 |
|---|---|---|
| 服务端GPU | 约15块A100(月租约7.5万) | 无需GPU渲染 |
| 带宽成本 | 视频推流约5Mbps/路,100路约500Mbps专线 | 参数流约几十Kbps/路,普通宽带即可 |
| 终端硬件 | 需要解码能力较强的终端 | RK3566(720P)或RK3588(1080P),百元级芯片 |
| 月度总成本 | 约10万+ | 约1-2万(含平台服务费) |
百元级硬件芯片即可部署运行,这不是宣传话术,是实测结果。RK3566这颗芯片的成本也就几十块钱,在弱网环境下参数流照样跑,因为每秒传输的数据就几KB。
五、关于具身智能交互的思考
在用星云做这个项目的过程中,我对"具身智能交互"这个概念有了更具体的理解。
传统数字人之所以交互体验差,根本原因是交互被拆成了独立的模块——语音识别是语音识别,大模型是大模型,TTS是TTS,渲染是渲染,每个模块独立工作,靠接口串联。这种"拼积木"式的架构,每个环节的延迟都会叠加,最终造成整体响应慢、打断不自然、表情和语音不同步。
星云的三层架构——多模态感知层 → 大模型 + 智能体认知层 → 多模态具身表达层——本质上是在做端到端的协同优化。参数流不是简单的"把视频帧换成参数",而是让语音、表情、动作的生成在同一个管线里同步进行,从语义理解到具象表达是连贯的、一体的。这样数字人的反应才不会"嘴动了但表情没跟上"或者"话停了但动作还在播"。
这也是为什么星云能实现端到端≈500ms的驱动响应——不是因为某个单环节做得快,而是整条链路被设计成了参数驱动的统一管线。
六、实际体验总结
最后说说我自己用下来的感受。
这个出行导引的Demo从零搭建到跑通,整体花了一个下午。其中trae帮我快速搭了前端框架,核心的星云SDK对接部分参考官方文档,API设计确实简洁——创建实例、初始化、speak,三个核心步骤就跑起来了。
真正让我觉得这个方案适合落地的,是三个实际体验:
1. 延迟体感确实接近真人对话。500ms这个数字在体感上的差异是质的——不是"等等再说",而是"边听边说"。在门店场景里,顾客问完一个问题,数字人几乎是即时回应的,这个体验和传统视频流方案完全不同。
2. 硬件门槛真的低。我拿一块RK3588的开发板就跑起来了1080P的渲染,不需要GPU,不需要游戏引擎。对于要铺几十一百块屏幕的连锁门店来说,这块省下来的硬件和运维成本是实实在在的。
3. SDK的全兼容性。一套SDK同时适配屏幕端数字人和服务机器人两类终端,Android、iOS、鸿蒙、Web全支持。对于需要多终端部署的项目来说,不用为每个平台单独开发,省了大量的适配工作。
当然也有需要注意的地方:SDK目前要求localhost或https环境才能调用,本地开发需要用localhost而不是IP地址访问;首次连接需要加载角色资源,有几秒的加载时间(后续连接会快很多);流式speak时首次调用建议积攒一小段内容再传入,避免语速不均匀。
总的来说,如果你在做数字人相关的落地项目,特别是政务、教育、零售这类需要实时交互的场景,魔珐星云的参数流方案值得认真评估。它解决的不是一个功能问题,而是"数字人从能用变成好用"的体验问题——而体验,才是数字人能不能真正落地的关键。
相关资源:
-
SDK文档:https://xingyun3d.com/developers/52-183
-
AI Coding Skill说明文档:https://rsjqcmnt5p.feishu.cn/wiki/ULNQwoiKwid2tVkTpAlcMb49nKg

纵情码海钱塘涌,杭州开发者创新动! 属于杭州的开发者社区!致力于为杭州地区的开发者提供学习、合作和成长的机会;同时也为企业交流招聘提供舞台!
更多推荐

 10
10 0
0- 0



 已为社区贡献28条内容
已为社区贡献28条内容

所有评论(0)