
猫头虎AI开源分享:马斯克真的开源了X平台推荐算法,6小时斩获1.6k Star,2026开源生态的王炸项目
马斯克兑现承诺,开源X平台推荐算法,引发科技圈轰动。该项目基于Grok Transformer架构,采用Rust+Python技术栈,6小时斩获1.6k Star。核心算法完全摒弃手工特征,通过模型自主学习用户偏好,并采用候选隔离计算、哈希加速等创新设计。马斯克强调这是社交平台首次实现算法透明化,未来将每四周更新一次代码。该开源不仅让外界首次看清X的内容推荐机制,更可能重塑社交媒体的算法信任体系。
猫头虎AI开源分享:马斯克真的开源了X平台推荐算法,6小时斩获1.6k Star,2026开源生态的王炸项目
摘要
x-algorithm 是由 xai-org 维护的开源算法项目,核心目标是打造一套通用、可扩展、高性能的算法库,覆盖机器学习、深度学习、数据处理、优化算法等多个领域,聚焦算法的工程化落地与易用性,同时兼顾学术研究与工业场景的适配性。
猫头虎AI开源forks仓库:
国内gitcode:https://gitcode.com/qq_44866828/x-algorithm
海外GitHub:https://github.com/MaoTouHU/x-algorithm
文章目录
正文
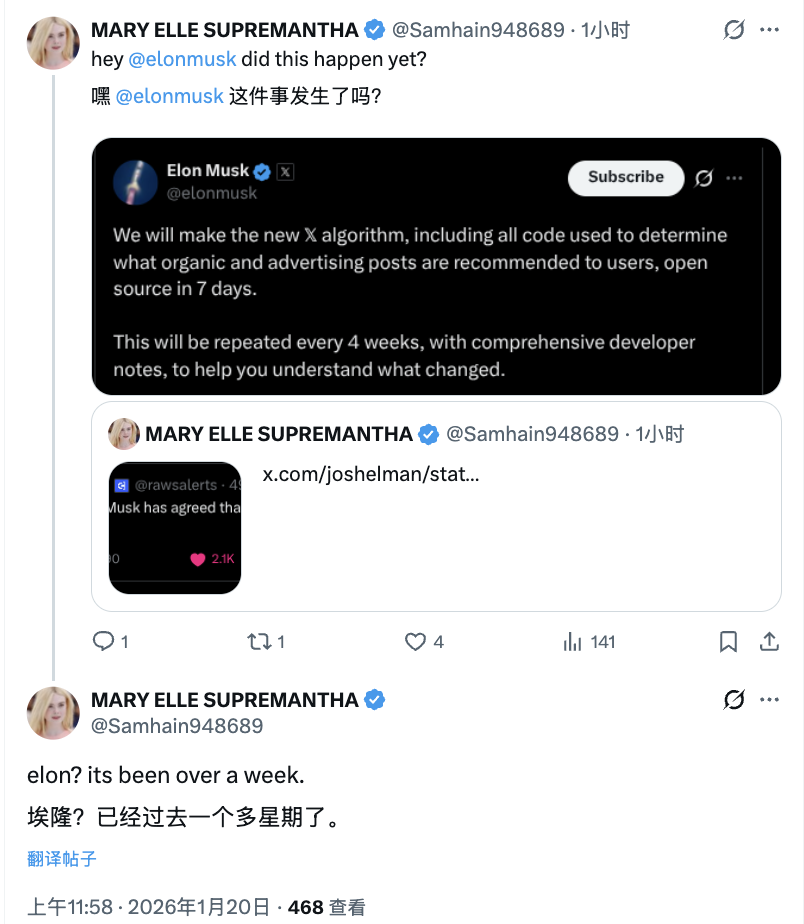
“我们将在 7 天内把 X 平台最新的内容推荐算法开源。”
几天前,X 平台掌舵者埃隆·马斯克抛出的这句话,直接把科技圈和开发者圈的情绪拉满——因为这意味着,外界第一次可能系统性看清:X 到底如何决定推荐哪些自然内容、哪些广告内容。
当时很多人半信半疑:这事儿真的会落地?还是又一个“语出惊人”的热搜瞬间?于是大家开始在 X 上“蹲点”,等他到底会不会“按时交卷”。
结果,答案来了,而且来得很硬核。
X 平台工程团队的 Engineering 官方账号于今天正式宣布:X 全新推荐算法开源——并且强调,该算法采用了与 xAI 的 Grok 模型相同的 Transformer 架构。
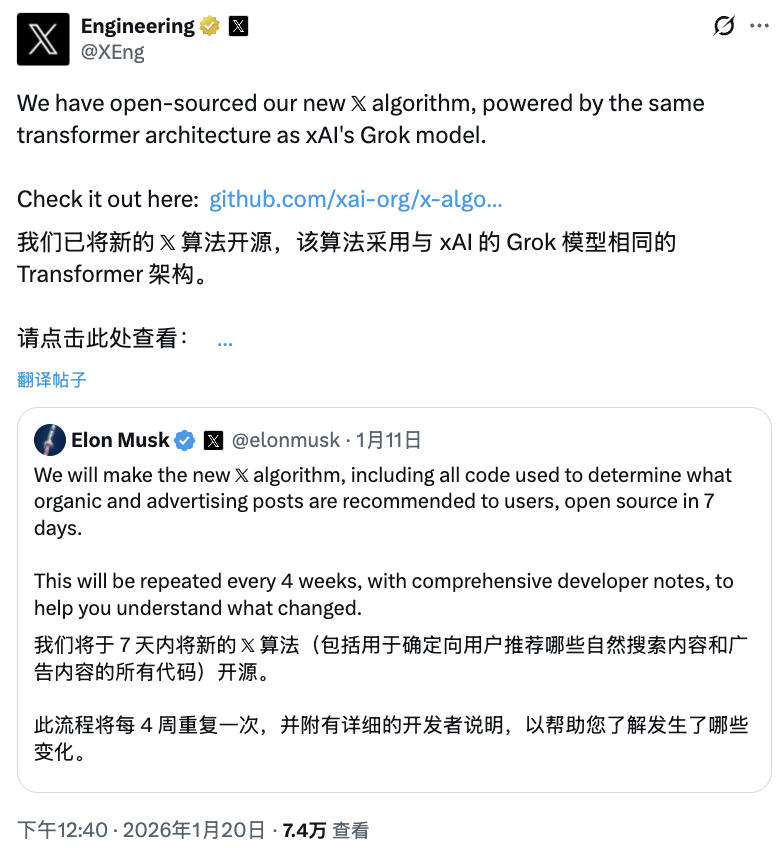
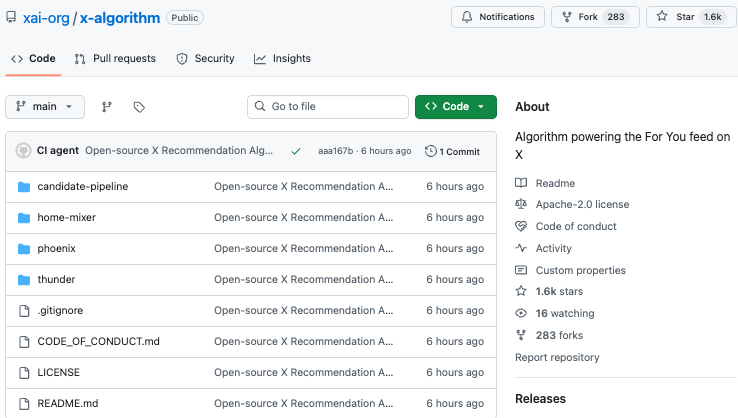
与此同时,相关 GitHub 仓库同步公开:https://github.com/xai-org/x-algorithm ,上线仅六小时就拿下 1.6k Star,热度直接起飞。
更关键的是:这不是象征性“丢一段代码”摆个姿态。对于那个被讨论了很多年的问题——“X 的推荐系统到底是怎么运作的?”
这一次,终于不是猜测、不是传闻,而是可以直接翻源码。
从“放话”到“交卷”:马斯克为什么非要开源算法?
聊这次开源,得先理解马斯克对“透明”的执念。
在社交平台领域,推荐算法本质上就是“注意力分配机器”:用户刷到的每条动态、每个广告位,背后都是算法在结合用户行为、内容特征、商业诉求后做出的选择。长期以来,这些算法几乎都是各家平台最核心的“黑箱机密”——外界最多靠逆向工程和经验猜测,很少有人真正见过底层逻辑。
但马斯克偏要掀开盖子。
接手 X 平台前后,他多次公开吐槽“算法不透明”,并把 X 定位成一个更接近「自由广场」的产品形态。这次立下“开源 Flag”,与其说是临时起意,不如说是他改造 X 的关键动作:
- **对外:**用开源让全球开发者与用户一起监督算法逻辑,降低“算法偏见”“流量操纵”等争议,同时也更容易面对监管层面的压力;
- **对内:**借助开源社区的力量共同优化系统,让改进效率更高、迭代更快,进一步巩固 X 的生态护城河。
而且这还不是“一次性开源”就结束。马斯克此前还提过一个更激进的节奏:
后续将每四周更新一次代码,并附开发者说明,明确标注算法与逻辑改动。
在社交平台行业里,这种“持续开源 + 透明更新”的玩法几乎是第一次出现。接下来我们就拆开仓库看看:这次到底开源了什么。
GitHub 开箱:X 的推荐算法,到底长什么样?
打开https://github.com/xai-org/x-algorithm 这个仓库,首先可以确认:这次开源的核心是 X 平台「For You(为你推荐)」信息流的推荐系统。
据 X 工程团队介绍,「For You」内容主要来自两大来源:
- 站内内容(Thunder 模块):用户关注账号发布的帖子;
- 站外内容(Phoenix 召回模块):从全网内容库中筛选召回的帖子。
两类内容汇总后,会进入 Phoenix 模型进行分析。该模型基于 Grok Transformer 架构:
Transformer 实现移植自 xAI 开源的 Grok-1,并针对推荐系统场景做了适配与调整。
模型会根据用户点赞、回复、转发等互动历史,预测用户对每篇帖子的多类互动概率,最终用概率的加权组合得到内容得分并排序。
更值得注意的是,X 工程团队明确表示:系统已经剔除所有手工设计特征与绝大多数启发式规则,核心计算几乎完全由 Grok Transformer 模型承担。换句话说,它的逻辑更接近——让模型从用户互动序列中自己学习“相关性”。
系统架构如下所示:
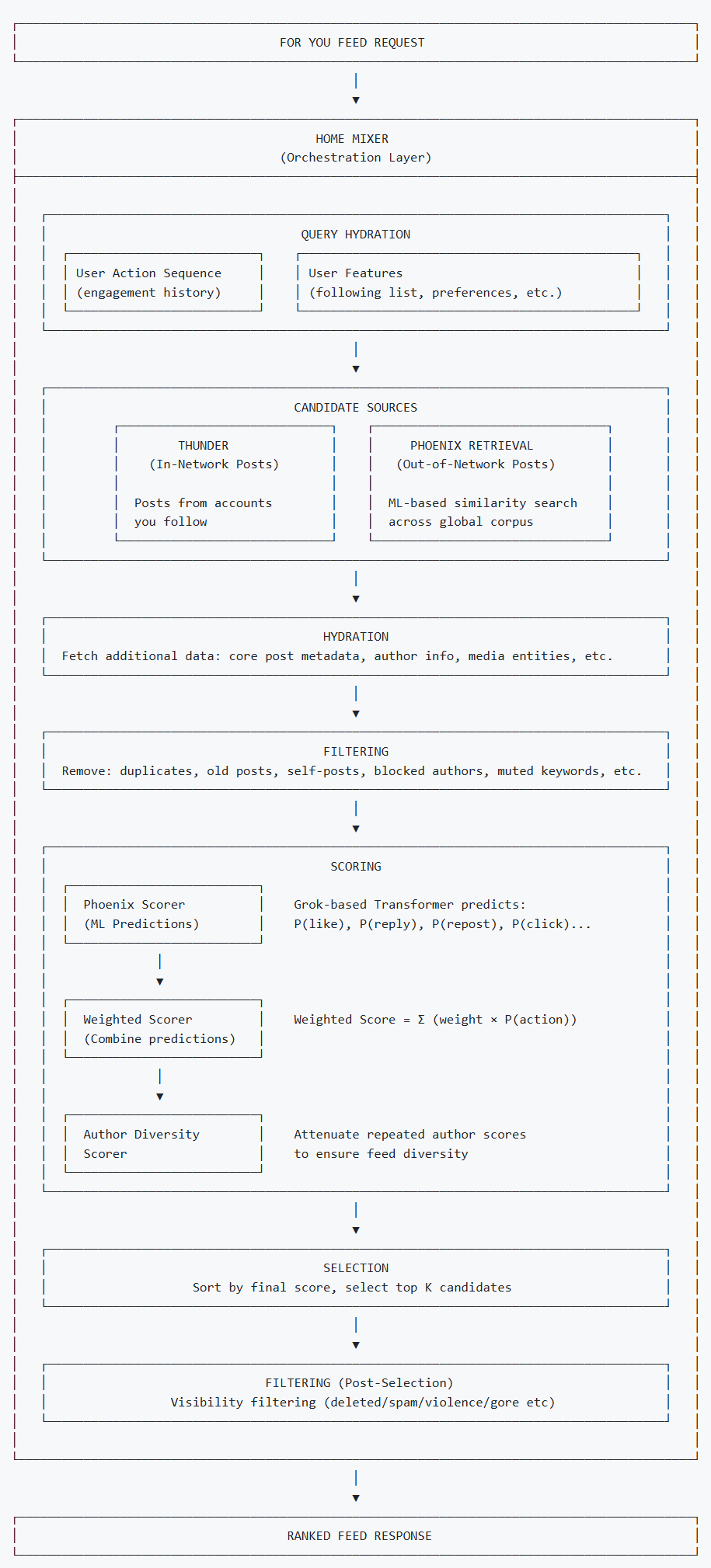
Rust 为主、Python 为辅:「For You」推荐系统拆解
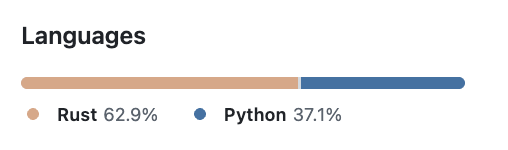
从技术栈看,该仓库主要使用 Rust + Python,并采用 Apache License 2.0 开源许可。
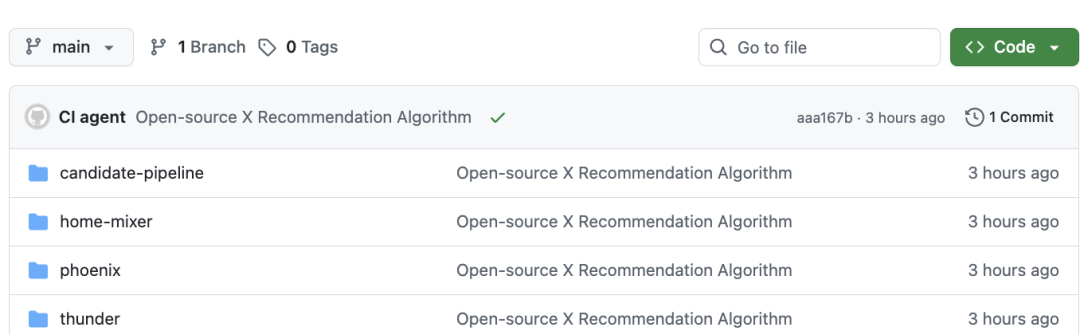
项目按功能模块划分清晰,核心模块分工也比较明确:
- phoenix/:包含 Grok 模型适配、推荐系统模型(recsys_model.py)、召回模型(recsys_retrieval_model.py)等核心代码,以及模型运行与测试脚本;
- home-mixer/:Rust 编写的推荐系统“编排层”,包含候选内容补全、查询数据补全、打分器、过滤器等核心逻辑;
- thunder/:Rust 编写,负责处理站内内容(关注账号帖子)的检索、反序列化、Kafka 消息处理等;
- candidate-pipeline/:候选内容流水线的关键模块,连接内容源与后续处理环节。
整体执行流程也很“工程化”:从响应信息流请求开始,系统会经历 7 个核心阶段完成筛选与推送,每一步都围绕“更匹配用户兴趣、更少重复、更少低质、更少打扰”来设计。
第一步:调取用户核心数据(用户画像起点)
算法启动时会先做“用户数据补全”,抓取用户近期互动记录(点赞、回复、转发、点击等),同时调取关注列表、偏好设置等基础元数据,为后续推荐建立“用户画像”的基础框架。
第二步:抓取两类候选内容(站内 + 站外)
基于用户数据,从两大渠道抓取候选内容:
- 站内候选:由 Thunder 模块处理,来源是用户关注账号发布的近期帖子;
- 站外候选:由 Phoenix 召回模块通过机器学习从全网内容库挖掘“你没关注但可能喜欢”的帖子,是推荐陌生内容的关键来源。
第三步:补全内容完整信息(让打分更可靠)
对候选内容做信息补全,例如:文本、图片/视频素材、作者信息(用户名、认证状态)、视频时长、订阅权限等,确保每条候选内容都具备完整维度,避免“信息缺失导致误判”。
第四步:打分前先过滤无效内容(省算力 + 提体验)
进入模型打分前先做前置过滤,直接剔除:
- 重复帖子、过期内容、用户本人内容
- 来自屏蔽/静音账号的内容、包含静音关键词的内容
- 用户已看过/近期刚推送过的内容
- 无权限访问的付费内容
这一步的本质是:把“明显不该出现”的内容先踢掉,避免占用后续计算资源。
第五步:多维度打分并排序(核心竞争力所在)
过滤后的内容进入 Scoring 环节,系统会调用四类打分器计算得分:
- Phoenix 打分器:从基于 Grok 的 Transformer 模型中获取预测结果
- 加权打分器:将预测结果整合为最终相关性得分
- 作者多样性打分器:降低重复作者内容得分,保证信息流多样性
- 站外内容打分器(OON Scorer):调整全网挖掘内容的得分,平衡站内与站外内容比例
第六步:筛选 Top-K(进入决赛圈)
按得分排序,选取得分最高的前 K 条候选内容进入最终阶段。
第七步:最终验证后推送(上线前最后一道闸)
即便得分很高,也要通过最终合规性与有效性校验,确认无误后才正式推送到用户信息流中。
X 推荐系统的 5 个关键设计:它为什么像“新一代推荐框架”?
在底层设计上,X 这套推荐系统的差异点非常明确:
- 摒弃手工特征:核心依赖 Grok Transformer 从用户互动序列中自主学习相关性,降低数据流水线与基础设施复杂度;
- 候选隔离计算:推理过程中候选内容之间互不影响,仅围绕用户上下文打分,得分更稳定且可缓存;
- 哈希函数加速检索:召回与排序环节使用多个哈希函数查找嵌入向量,提高运行效率;
- 多行为概率预测:不仅预测“相关性”,还预测用户多种行为概率,打分维度更完整;
- 流水线可组合架构:基于 candidate-pipeline 构建可组合流水线,支持并行执行、优雅错误处理,并且可快速新增内容源、补全规则、过滤器与打分器,扩展性很强。
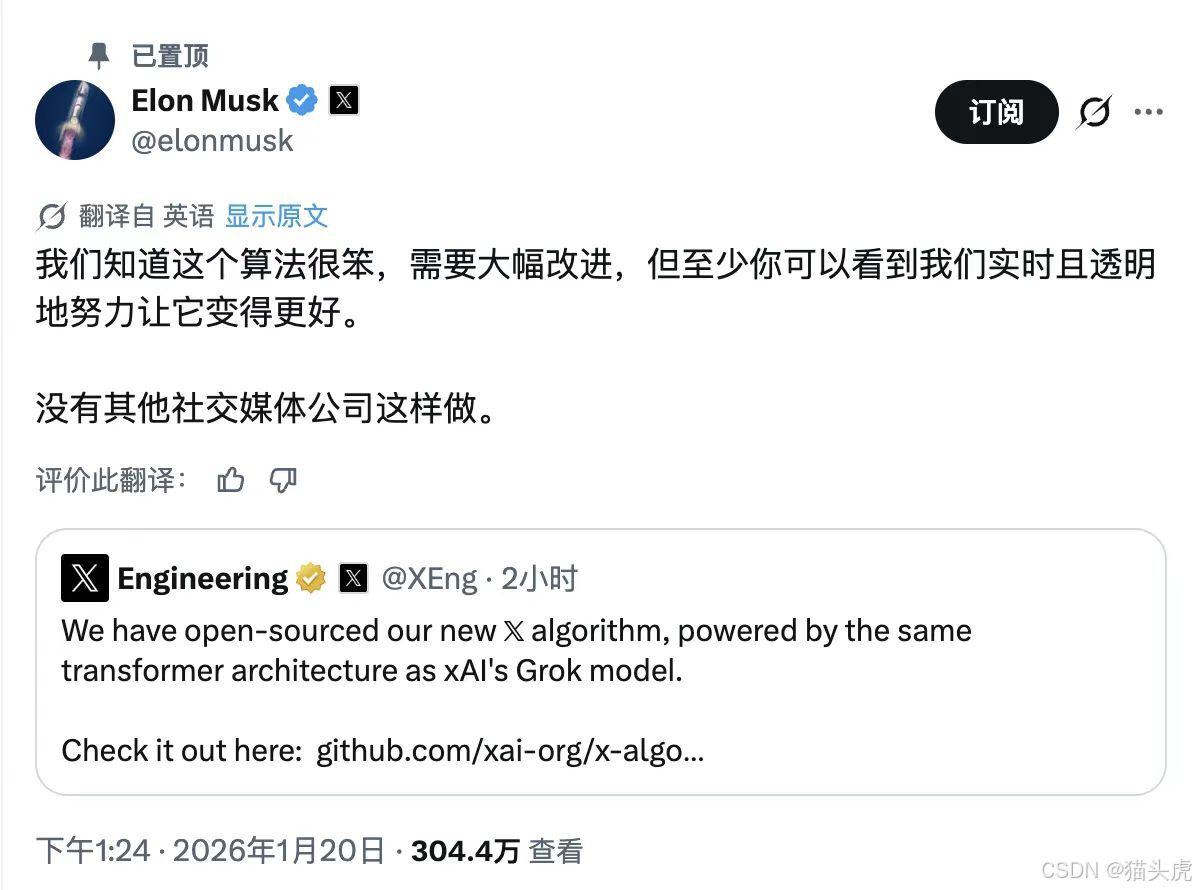
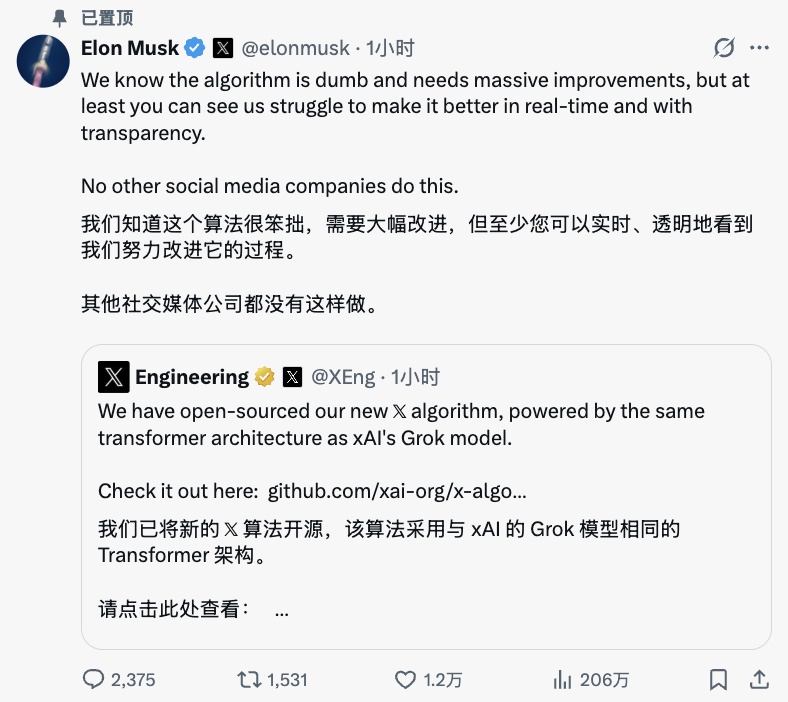
马斯克:“其他社交媒体公司都没有这样做”
开源之际,马斯克的态度也非常直白:
“我们知道这个算法很笨拙,需要大幅改进,但至少你可以实时、透明地看到我们努力改进它的过程。”
并补了一句很有“马斯克风格”的话:
“其他社交媒体公司都没有这样做。”
这波开源也迅速引发热议。
对普通开发者而言,价值远不止“看个代码热闹”——它意味着注意力分配机制第一次有机会从“不可见黑箱”变成“可理解系统”。正如网友 AbundanceVsWar 的评论所表达的核心观点:
当影响力分配不透明时,注意力会被感知为零和、被操控、充满政治性;而开源让规则可见,从而让系统更容易被理解、被讨论、被改进——理解本身就会改变行为。

当然,也有人担心:一旦开源,作弊门槛会不会变低?优质内容是否会被“算法玩法”挤爆?甚至导致推荐生态短期失衡?


整体来看,马斯克这波操作已经把一个更大的问题摆上台面:
如果 X 的“开源 + 透明更新”被证明有效,会不会倒逼其他平台跟进?
用户对算法透明的需求只会越来越高。谁先把“规则公开”这件事做到位,谁就可能在用户心智里建立新的信任优势。
至于马斯克的“第一步”之后还会抛出多少惊喜?我们不妨继续盯住这个仓库——2026 开源生态的“王炸项目”,也许才刚刚开始。
参考资料

一起探索未来云端世界的核心,云原生技术专区带您领略创新、高效和可扩展的云计算解决方案,引领您在数字化时代的成功之路。
更多推荐



 12
12 0
0- 0



 已为社区贡献186条内容
已为社区贡献186条内容

所有评论(0)