
如何在 Elasticsearch 中选择精确 kNN 搜索和近似 kNN 搜索
使用嵌入计算查询的 kNN 有两种主要方法:精确和近似。 这篇文章将帮助你:了解什么是精确和近似 kNN 搜索 如何为这些方法准备索引 如何确定哪种方法最适合你的用例
作者:来自 Elastic Carlos Delgado
kNN 是什么?
语义搜索(semantic search)是相关性排名的强大工具。 它使你不仅可以使用关键字,还可以考虑文档和查询的实际含义。
语义搜索基于向量搜索(vector search)。 在向量搜索中,我们要搜索的文档具有为其计算的向量嵌入。 这些嵌入是使用机器学习模型计算的,并作为向量返回,与我们的文档数据一起存储。
执行查询时,将使用相同的机器学习模型来计算查询文本的嵌入。 语义搜索包括通过将查询嵌入与文档嵌入进行比较来查找最接近查询的结果。
kNN(或 k nearest neighbors - k 最近邻)是一种用于获取与特定嵌入最接近的前 k 个结果的技术。
使用嵌入计算查询的 kNN 有两种主要方法:精确和近似。 这篇文章将帮助你:
- 了解什么是精确和近似 kNN 搜索
- 如何为这些方法准备索引
- 如何确定哪种方法最适合你的用例
精确 kNN:搜索所有内容
计算更接近结果的一种方法是将所有现有文档嵌入与查询的文档嵌入进行比较。 这将确保我们获得尽可能最接近的匹配,因为我们将比较所有匹配。 我们的搜索结果将尽可能准确,因为我们正在考虑整个文档语料库并将所有文档嵌入与查询嵌入进行比较。
当然,与所有文档进行比较有一个缺点:需要时间。 我们将使用相似度函数对所有文档逐一计算嵌入相似度。 这也意味着我们将线性扩展 —— 文档数量增加一倍可能需要两倍的时间。
可以使用 script_score 和用于计算向量之间相似度的向量函数在向量场上进行精确搜索。
近似 kNN:一个很好的估计
另一种方法是使用近似值而不是考虑所有文档。 为了提供 kNN 的有效近似,Elasticsearch 和 Lucene 使用分层导航小世界 HNSW (Hierachical Navigation Small Worlds)。
HNSW 是一种图数据结构,它维护不同层中靠近的元素之间的链接。 每层都包含相互连接的元素,并且还与其下方层的元素相连接。 每层包含更多元素,底层包含所有元素。

可以把它想象成开车:有高速公路、道路和街道。在高速公路上行驶时,你会看到一些描述高层次区域(如城镇或社区)的出口标志。然后你会到达一条有具体街道指示的道路。一旦你到达某条街道,你就可以找到具体的地址,以及同一社区内的其他地址。
HNSW(Hierarchical Navigable Small World)结构类似于此,它创建了不同层次的向量嵌入。它计算离初始查询较近的 “高速公路”,选择看起来更有希望的出口,继续寻找更接近目标地址的地方。这在性能方面非常优秀,因为它不必考虑所有文档,而是使用这种多层次的方法快速找到接近目标的近似结果。
但是,这只是一个近似值。并不是所有节点都是互联的,这意味着可能会忽略某些更接近特定节点的结果,因为它们可能没有连接。节点的互联程度取决于 HNSW 结构的创建方式。
HNSW 的效果取决于多个因素:
-
它是如何构建的。HNSW 的构建过程会考虑一定数量的候选节点,作为某一特定节点的近邻。增加考虑的候选节点数量会使结构更精确,但会在索引时花费更多时间。dense vector index_options 中的 ef_construction 参数用于此目的。
-
搜索时考虑的候选节点数量。在寻找更近结果时,过程会跟踪一定数量的候选节点。这个数量越大,结果越精确,但搜索速度会变慢。kNN 参数中的 num_candidates 控制这种行为。
-
我们搜索的分段数量。每个分段都有一个需要搜索的 HNSW 图,其结果需要与其他分段图的结果结合。分段越少,搜索的图就越少(因此速度更快),但结果集的多样性会减少(因此精度较低)。
总的来说,HNSW 在性能和召回率之间提供了良好的权衡,并允许在索引和查询两方面进行微调。
使用 HNSW 进行搜索可以在大多数情况下通过 kNN 搜索部分完成。对于更高级的用例,也可以使用 kNN 查询,例如:
- 将 kNN 与其他查询结合(作为布尔查询或固定查询的一部分)
- 使用 function_score 微调评分
- 提高聚合和字段折叠(field collapse)的多样性
你可以在这篇文章中查看关于 kNN 查询及其与 kNN 搜索部分的区别。我们将在下面深入讨论何时使用这种方法与其他方法。
为精确和近似搜索建立索引
dense_vector 字段类型
对于存储嵌入,dense_vector 字段有两种主要的索引类型可供选择:
-
flat 类型(包括 flat 和 int8_flat):存储原始向量,不添加 HNSW 数据结构。使用 flat 索引类型的 dense_vector 将始终使用精确的 kNN,kNN 查询将执行精确查询而不是近似查询。
-
HNSW 类型(包括 hnsw 和 int8_hnsw):创建 HNSW 数据结构,允许使用近似 kNN 搜索。
这是否意味着你不能对 HNSW 字段类型使用精确的 kNN?并非如此!你可以通过 script_score 查询使用精确 kNN,也可以通过 kNN 部分和 kNN 查询使用近似 kNN。这样可以根据你的搜索用例提供更多的灵活性。
使用 HNSW 字段类型意味着需要构建 HNSW 图结构,这需要时间、内存和磁盘空间。如果你只会使用精确搜索,可以使用 flat 向量字段类型。这确保了你的嵌入索引是最佳的,并且占用更少的空间。
请记住,在任何情况下都应避免将嵌入存储在 _source 中,以减少存储需求。
量化
使用量化技术,无论是 flat(int8_flat)还是 HNSW(int8_hnsw)类型的索引,都可以帮助你减少嵌入的大小,从而使用更少的内存和磁盘存储来保存嵌入信息。
由于搜索性能依赖于尽可能多地将嵌入存储在内存中,因此你应该始终寻找减少数据的方法。使用量化是在内存和召回率之间进行权衡。
如何在精确搜索和近似搜索之间做出选择?
没有一种适用于所有情况的答案。你需要考虑多个因素,并进行实验,以找到性能和准确性之间的最佳平衡:
数据规模
不应该不惜一切代价避免搜索所有内容。根据你的数据规模(文档数量和嵌入维度),进行精确的 kNN 搜索可能是合理的。
作为一个经验法则,如果需要搜索的文档少于一万,可能表明应该使用精确搜索。请记住,可以提前过滤需要搜索的文档数量,因此通过应用过滤条件可以限制实际需要搜索的文档数量。
近似搜索在文档数量方面具有更好的扩展性,因此如果你有大量文档需要搜索,或者预计文档数量会显著增加,应该选择近似搜索。

过滤 - filtering
过滤非常重要,因为它减少了需要考虑搜索的文档数量。在决定使用精确搜索还是近似搜索时,需要考虑这一点。可以使用 query filters 来减少需要考虑的文档数量,无论是精确搜索还是近似搜索。
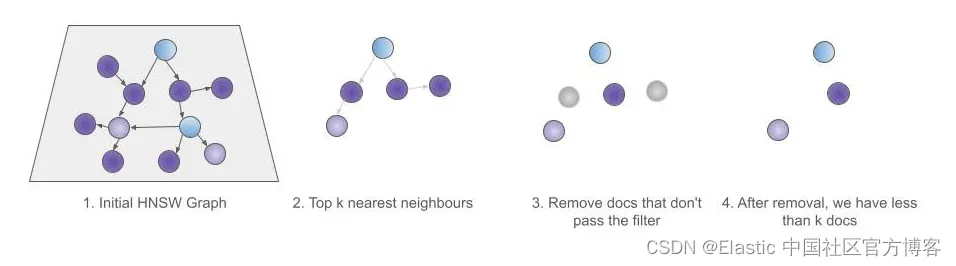
然而,近似搜索在过滤时采用了不同的方法。在使用 HNSW 进行近似搜索时,查询过滤器将在检索到前 k 个结果后应用。这就是为什么与 kNN 查询一起使用查询过滤器被称为 kNN 的后过滤。
这种特定的 kNN 查询过滤器被称为 kNN 预过滤器,因为它在检索结果之前应用,而不是之后。因此,在使用 kNN 查询的上下文中,常规查询过滤器被称为后过滤器。
幸运的是,还有另一种与 kNN 一起使用的方法,即在 kNN 查询本身中指定过滤器。 当遍历 HNSW 图收集结果时,此过滤器适用于图元素,而不是事后应用。 这确保返回前 k 个元素,因为将遍历图 - 跳过未通过过滤器的元素 - 直到我们获得前 k 个元素。
即将推出的功能
即将推出的一些改进将有助于精确和近似 kNN。
Elasticsearch 将增加将 dense_vector 类型从 flat 升级到 HNSW 的功能。这意味着你可以先使用 flat 向量类型进行精确 kNN,当需要扩展时可以开始使用 HNSW。使用近似 kNN 时,你的段将透明地被搜索,并在合并时自动转换为 HNSW。
一个新的精确 kNN 查询将被添加,以便使用简单的查询来对 flat 和 HNSW 字段进行精确 kNN,而不是依赖于 script score 查询。这将使精确 kNN 更加简便。
结论
那么,你应该在文档上使用近似 kNN 还是精确 kNN 呢?请检查以下几点:
- 文档数量:如果少于一万(应用过滤器后),可能适合使用精确搜索。
- 你的搜索是否使用了过滤器:这会影响要搜索的文档数量。如果需要使用近似 kNN,请记住使用 kNN 预过滤器以获取更多结果,代价是性能下降。
你可以通过使用 HNSW dense_vector 进行索引,并将 kNN 搜索与 script_score 进行精确 kNN 的对比,来比较两种方法的性能。这允许在使用相同字段类型的情况下比较两种方法(如果决定使用精确搜索,请记住将 dense_vector 字段类型更改为 flat)。
祝你搜索愉快!
准备将 RAG 集成到你的应用中吗?想尝试在向量数据库中使用不同的 LLMs 吗? 查看我们在 Github 上的 LangChain、Cohere 等示例笔记本,并参加即将开始的 Elasticsearch 工程师培训吧!
原文:kNN in Elasticsearch: How to choose between exact and approximate kNN search — Elastic Search Labs

欢迎加入北京社区
更多推荐

 37
37 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)