
loss.backward() 到底在干什么?一篇讲透计算图与反向传播
loss.backward() 到底在干什么?一篇讲透计算图与反向传播
整理说明:本文基于 B 站视频【第05讲《计算图与反向传播:梯度如何流动》】公开信息、课程逐字稿与配套资料进行原创整理。不是逐字转写,而是把核心概念、手算流程、代码练习和排错方法整理成科研小白可以照着学的教程。
视频来源:B站 @Ai学术叫叫兽
视频链接:https://www.bilibili.com/video/BV1y5Ko6DEcR/
视频时长:约 19 分 28 秒

很多同学第一次看到 PyTorch 里的这行代码:
loss.backward()
第一反应通常是:这是不是一个“魔法按钮”?
明明我们只看到一个 Loss,点一下 backward(),模型里成千上万个参数突然就都有了梯度。哪个权重要变大,哪个偏置要变小,每个参数该改多少,好像模型自己都知道了。
但它不是魔法。
反向传播的本质其实很朴素:用计算图记录计算路线,再用链式法则沿着路线反向追责。
这一讲只解决一个核心问题:
模型预测错了以后,最终错误是怎么分摊到前面每一个参数上的?
如果你能把这个问题讲清楚,后面学深层神经网络、CNN、YOLO 训练、Loss 曲线、梯度消失和梯度爆炸,就不会只是在背术语。
文末也给大家整理了复盘清单和资料领取话术。PPT、讲义和动画资料可以无偿送给大家,适合课后反复对着复盘。
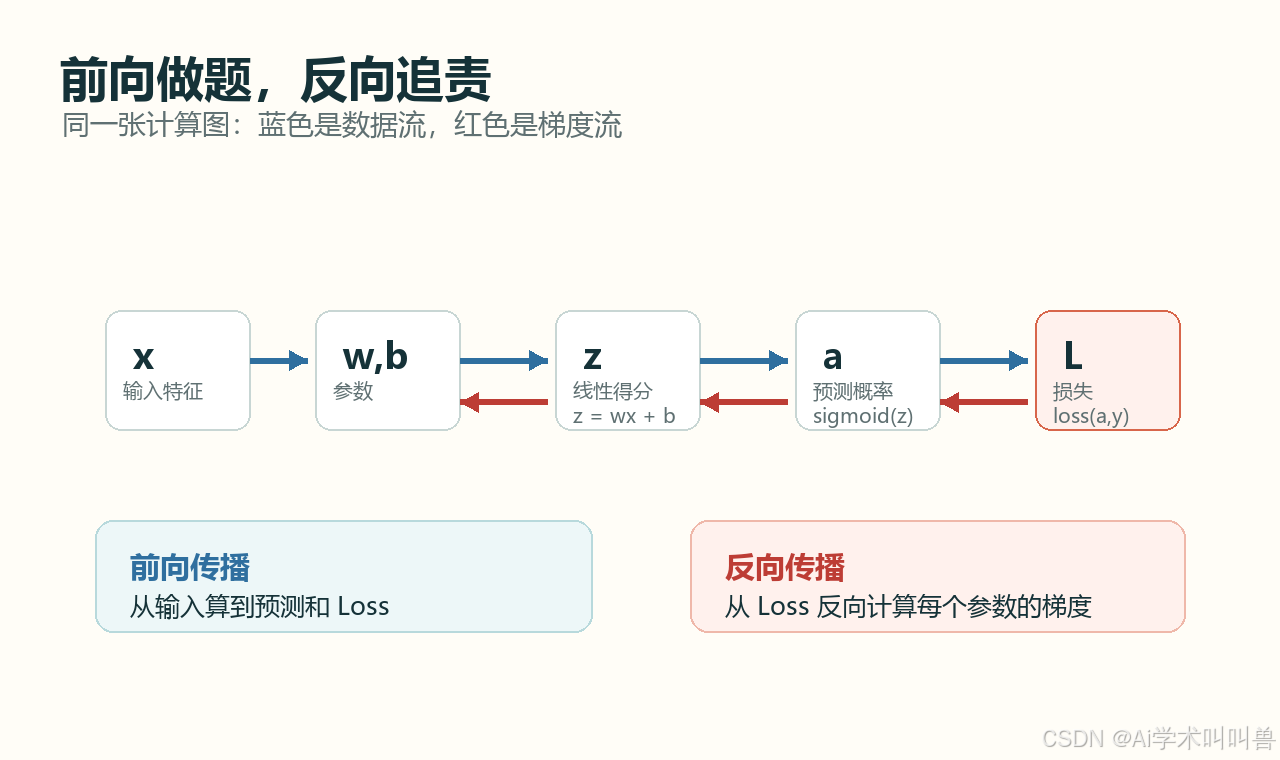
01 先建立一个画面:前向做题,反向追责
上一讲我们讲过一个最简单的神经元:
z = w·x + b
a = sigmoid(z)
L = loss(a, y)
它的前向过程很像学生做题:
输入 x 进来,模型用权重 w 和偏置 b 算出线性得分 z,再通过 sigmoid 得到预测概率 a,最后和真实标签 y 比较,得到 Loss。
这一步回答的是:
模型怎么做预测?
但训练真正关心的是下一步:
预测错了以后,模型怎么知道每个参数应该怎么改?
这就像考试总分低了,不能只说“考差了”。你还要追问:
| 问题 | 在模型里对应什么 |
|---|---|
| 哪道题扣分最多? | 哪个计算节点对 Loss 影响大 |
| 是概念错,还是计算错? | 是前向输出异常,还是梯度传递异常 |
| 下次该补哪里? | 哪个参数该往什么方向更新 |
| 是小修小补,还是大幅调整? | 梯度大小和学习率共同决定更新步长 |
所以,反向传播可以先理解成一句话:
Loss 是最后的错误结果,计算图是路线图,链式法则是追责方法,梯度是每个参数收到的调整通知。
02 六个关键词:把反向传播拆成小白能懂的语言
反向传播难,很多时候不是因为公式本身难,而是几个词混在一起了。
我们先把 6 个核心概念讲清楚。

| 概念 | 一句话理解 | 小白记法 |
|---|---|---|
| 计算图 | 用节点和箭头表示计算依赖关系 | 计算路线图 |
| 前向传播 | 从输入一路算到预测和 Loss | 模型先做一遍题 |
| 局部导数 | 某个节点输出对输入的敏感程度 | 每一小段有多敏感 |
| 链式法则 | 把路径上的局部导数乘起来 | 一段一段追影响 |
| 反向传播 | 从 Loss 出发反向计算每个参数梯度 | 从结果往回分责任 |
| 梯度 | Loss 对参数的变化率 | 参数该往哪改、改多猛 |
把这几个词连起来,就是本讲最重要的一句话:
计算图记录计算路线,前向传播得到 Loss,局部导数描述每一小段敏感度,链式法则把敏感度串起来,反向传播把梯度传回参数,优化器再根据梯度更新参数。
这句话能顺口说出来,反向传播的主线就稳了。
03 为什么一定要画计算图?
很多初学者会问:既然最后都是求导,为什么不直接背公式?
因为神经网络不是一个短公式,而是一条很长的计算链。
以单神经元为例:
x, w, b → z → a → L
每个箭头表示一次依赖:
| 节点 | 它从哪来 | 它到哪去 |
|---|---|---|
x |
输入特征 | 参与计算 z |
w |
权重参数 | 参与计算 z |
b |
偏置参数 | 参与计算 z |
z |
w·x + b |
送入 sigmoid |
a |
sigmoid(z) |
和标签比较算 Loss |
L |
loss(a, y) |
反向传播从这里开始 |
计算图的价值不只是“画得好看”,而是它能回答训练排错里最关键的三个问题:
- 这个变量从哪里来?
- 这个变量到哪里去?
- 如果 Loss 异常,错误信号能不能沿着这条路传回来?
真实训练里,很多问题并不是链式法则错了,而是计算图在某一步断了。
比如你不小心写了:
value = tensor.item()
或者把参与求导的张量转成了 NumPy 数组再参与计算,前面的梯度可能就断了。表面看 Loss 还在,实际上参数已经收不到有效梯度。
所以对科研小白来说,计算图不是可有可无的图示,而是训练排错地图。
04 手把手手算一遍:梯度到底怎么传到 w?
我们用一个小到能手算的例子:
z = w x + b
a = sigmoid(z)
L = (a - y)^2
前向传播按顺序算:
- 用
x、w、b算出z - 把
z放进 sigmoid 得到a - 把
a和标签y比较得到L
现在问题来了:
如果 Loss 大了,怎么知道 w 应该怎么改?
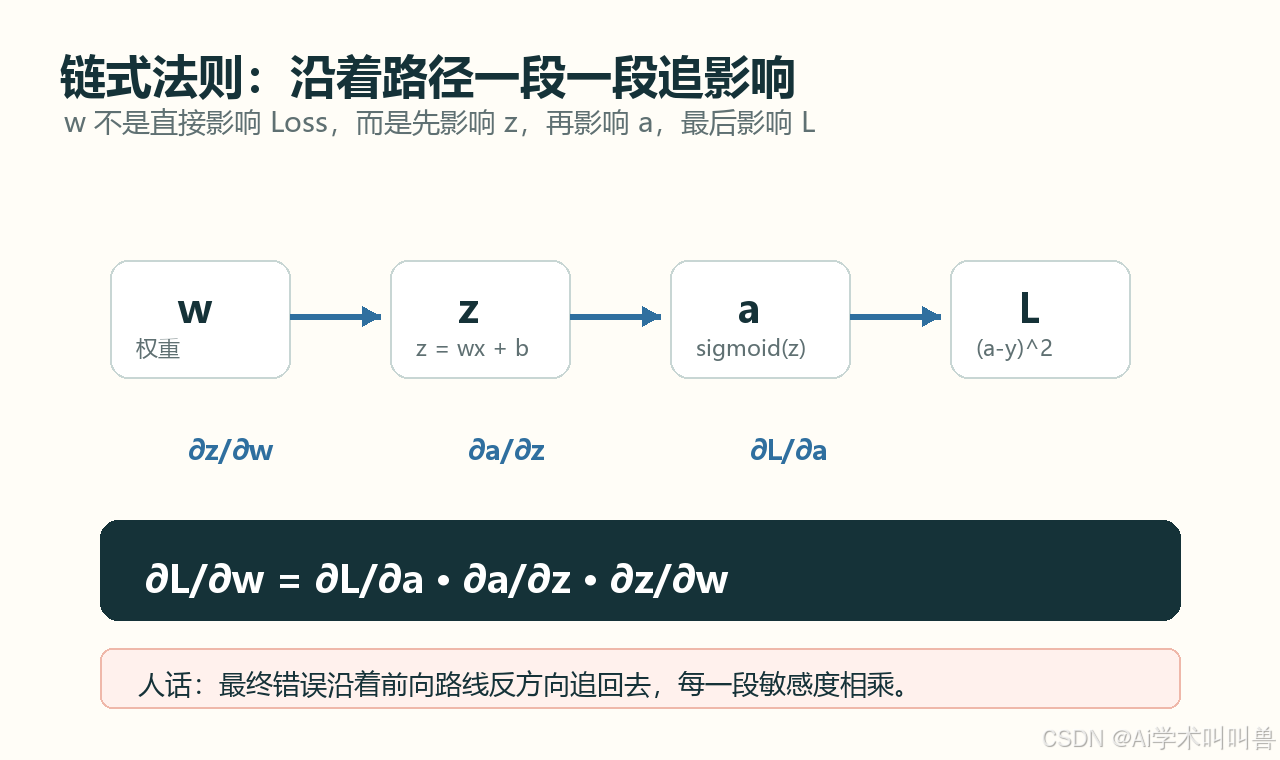
反向传播不会从 L 一步跳到 w,它会沿着计算图一段一段问:
L → a → z → w
每一段都问一个“敏感度”:
| 追问 | 数学表达 | 人话解释 |
|---|---|---|
| Loss 对预测有多敏感? | ∂L/∂a |
a 变一点,Loss 变多少 |
| 预测对线性得分有多敏感? | ∂a/∂z |
z 变一点,sigmoid 输出变多少 |
| 线性得分对权重有多敏感? | ∂z/∂w |
w 变一点,z 变多少 |
链式法则就是把三段影响乘起来:
∂L/∂w = ∂L/∂a · ∂a/∂z · ∂z/∂w
为了让它更落地,我们带一个数字例子:
x = 2
w = 0.5
b = 0
y = 1
z = 0.5 × 2 + 0 = 1
a = sigmoid(1) ≈ 0.731
L = (0.731 - 1)^2 ≈ 0.072
各段导数:
∂L/∂a = 2(a - y) ≈ -0.538
∂a/∂z = a(1-a) ≈ 0.197
∂z/∂w = x = 2
所以:
∂L/∂w ≈ -0.538 × 0.197 × 2 ≈ -0.212
这个负号很重要。它表示:在当前位置,w 增大一点,Loss 会下降。所以梯度下降更新时:
w ← w - α∂L/∂w
如果学习率 α = 0.1:
w_new = 0.5 - 0.1 × (-0.212) = 0.5212
也就是说,权重会被稍微调大一点。
这就是反向传播最核心的直觉:
最终错误不是凭空分给参数的,而是沿着前向计算走过的路,反方向追回去的。
05 PyTorch 里 backward() 做了什么?
很多人学反向传播,是从 PyTorch 这一套训练代码开始的:
optimizer.zero_grad()
pred = model(x)
loss = criterion(pred, y)
loss.backward()
optimizer.step()
这一段可以拆成 5 步:
| 代码 | 对应机制 | 小白解释 |
|---|---|---|
optimizer.zero_grad() |
清空旧梯度 | 先把上次的责任通知清掉 |
pred = model(x) |
前向传播 | 模型做题,得到预测 |
loss = criterion(pred, y) |
计算 Loss | 拿预测和答案对分 |
loss.backward() |
反向传播 | 沿计算图反向计算梯度 |
optimizer.step() |
参数更新 | 根据梯度真正改参数 |
注意两个最容易混的点:
第一,backward() 只是计算梯度,它不会直接更新参数。
第二,真正改变参数的是 optimizer.step()。
你可以把训练想象成一次“批改作业”:
前向传播:学生先做题
计算 Loss:老师打分
反向传播:分析每一步错在哪里
优化器更新:根据分析结果调整学习方式
06 科研小白实操:用 20 行代码看见梯度
下面这个最小例子,建议你真的跑一遍。
代码文件我已经放在本文资料包里:
code_snippets/01_manual_scalar_backprop.py
code_snippets/02_pytorch_autograd_backward.py
如果你只想先看 PyTorch 版,可以运行:
python code_snippets/02_pytorch_autograd_backward.py
核心代码如下:
import torch
x = torch.tensor(2.0)
y = torch.tensor(1.0)
w = torch.tensor(0.5, requires_grad=True)
b = torch.tensor(0.0, requires_grad=True)
z = w * x + b
a = torch.sigmoid(z)
loss = (a - y) ** 2
loss.backward()
print("z =", z.item())
print("a =", a.item())
print("loss =", loss.item())
print("dL/dw =", w.grad.item())
print("dL/db =", b.grad.item())
你会看到 w.grad 和 b.grad 不再是空的。
这说明 PyTorch 已经根据计算图,帮你把 Loss → a → z → w/b 这条链路走完了。

建议你做 3 个小实验:
- 把
w = 0.5改成w = -2.0,看看 Loss 和梯度怎么变。 - 把标签
y = 1.0改成y = 0.0,观察梯度方向是否变化。 - 在
loss.backward()后加一行print(w.grad),再运行两次,理解为什么训练循环里要zero_grad()。
小白阶段不要急着改复杂模型。先把这个极简例子跑懂,你以后看 CNN 和 YOLO 的训练循环,会轻松很多。
07 梯度不是误差:这是很多人卡住的地方
这一讲里最容易混淆的一句话是:
误差告诉你错了,梯度告诉你往哪改。
它们不是一回事。
| 对比项 | 误差 / Loss | 梯度 |
|---|---|---|
| 关注什么 | 预测和标签差多少 | 参数变化会怎样影响 Loss |
| 作用 | 衡量当前结果好不好 | 指导参数往哪更新 |
| 例子 | 这次考试扣了 20 分 | 应该重点补哪类题 |
| 代码位置 | loss = criterion(pred, y) |
loss.backward() 后的 param.grad |
如果只知道 Loss 大,你只知道模型错了。
但你不知道:
- 是哪个参数影响更大?
- 应该增大还是减小?
- 每个参数应该改大步还是小步?
这些信息都来自梯度。
所以调模型时,不要只盯着 Loss 曲线,也要学会检查梯度:
for name, p in model.named_parameters():
if p.grad is not None:
print(name, p.grad.abs().mean().item())
如果很多层梯度接近 0,可能存在梯度消失、计算图断裂或学习信号太弱。
如果梯度特别大,Loss 还来回震荡,可能存在梯度爆炸或学习率过大。
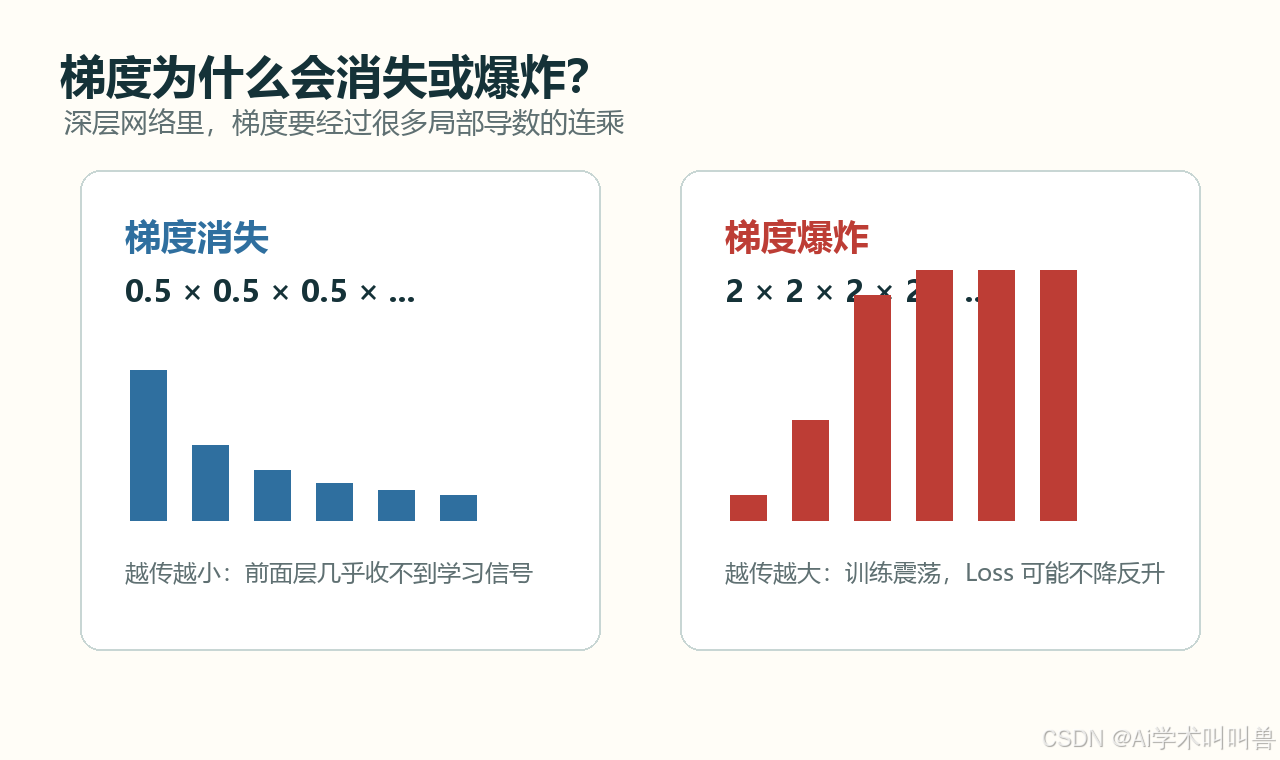
08 梯度消失和梯度爆炸,为什么会出现?
深层网络里,梯度要经过很多层才能传回前面的参数。
每经过一层,都会乘上一个局部导数。
如果很多局部导数都小于 1:
0.5 × 0.5 × 0.5 × 0.5 × ... → 越乘越小
梯度就可能越来越小,这叫梯度消失。
如果很多局部导数都大于 1:
2 × 2 × 2 × 2 × ... → 越乘越大
梯度就可能越来越大,这叫梯度爆炸。
这就是为什么后面学深层神经网络时,要讨论:
- 激活函数怎么选
- 参数怎么初始化
- 学习率怎么设置
- 是否需要归一化
- 是否需要残差连接
它们不是“高级装饰”,而是在帮助梯度稳定流动。
09 真实训练排错:按这 5 步检查
很多科研小白一遇到训练异常,就马上想换模型、换优化器、换更大的网络。
先别急。
真实项目里,大量问题都出在数据、shape、标签和计算链路上。
建议按下面 5 步排查:
| 步骤 | 你要问什么 | 常见问题 |
|---|---|---|
| 1. 输入是什么 | 进入模型的是图片、张量还是特征? | 通道顺序错、归一化错、batch 维丢失 |
| 2. 输出是什么 | 输出是概率、logits、Loss 还是指标? | 把 logits 当概率、Loss 对象搞错 |
| 3. shape 对吗 | 预测和标签形状是否匹配? | [B, C] 和 [B] 搞混 |
| 4. 梯度通吗 | param.grad 是否存在、是否为 0? |
计算图断裂、忘记 requires_grad |
| 5. 参数更新了吗 | optimizer.step() 后参数是否变化? |
忘记 step、学习率为 0、梯度被清空 |
最重要的是:
不要一上来就换模型。先确认输入、输出、中间变量、梯度、参数更新这条链路是通的。
10 结合图像任务理解:错误会传回前面的卷积核
放到图像模型里,反向传播就更有画面感了。
比如一个猫狗分类模型,把猫预测成了狗。
Loss 变大以后,错误信号不会只停在最后一层。
它会沿着计算图一路往回传:
分类输出 → 分类层权重 → 高级特征 → 中级特征 → 低级卷积核
前面的卷积核并不是天生会看边缘、纹理和形状。
它们一开始通常是随机初始化的。之所以后来能学出边缘、纹理、局部结构,是因为每一次预测错误都会通过反向传播把调整信号传回来。
这也解释了为什么标签质量非常重要。
如果标签错了,Loss 给出的方向就会偏;反向传播会非常认真地把这个错误方向传给参数。
模型不是故意学错,是你给它的学习信号错了。
所以做科研项目时,永远记住三件事:
- 数据是否正确
- 标签是否可靠
- 梯度是否能稳定传回前面的层
11 常见误区:别再这样理解反向传播
| 误区 | 正确理解 |
|---|---|
| 反向传播是模型自己想明白了 | 它是链式法则在计算图上的高效应用 |
| 梯度就是误差本身 | 误差描述错多少,梯度描述往哪改 |
| 有 Loss 就一定能训练 | 有 Loss 只能衡量错误,不代表梯度稳定 |
| 层数越深一定越好 | 深层网络表达力更强,但梯度更难稳定传递 |
backward() 会自动更新参数 |
backward() 算梯度,optimizer.step() 才更新参数 |
| Loss 不降就换模型 | 先查数据、shape、标签、梯度和学习率 |
如果你刚入门,最该背的不是一堆公式,而是这句话:
前向传播让模型知道自己错了多少,反向传播让每个参数知道自己该怎么改。
12 随堂自测:3 道题判断你是否真的懂了
建议停 30 秒,自己答一下。
题 1:画出单神经元计算图
请画出:
z = w·x + b
a = sigmoid(z)
L = loss(a, y)
参考答案:
x, w, b → z → a → L
前向从左往右算,反向从右往左传梯度。
题 2:为什么链式法则适合多层网络?
因为多层网络本质上是很多函数一层一层嵌套起来。
前面参数不是直接影响 Loss,而是通过很多中间节点间接影响 Loss。链式法则可以把每一小段的局部影响乘起来,得到最前面参数对最终 Loss 的总影响。
题 3:误差和梯度有什么区别?
误差描述预测结果和标签差了多少。
梯度描述某个参数变化会怎样影响误差。
一句话:
误差告诉你错了,梯度告诉你往哪改。
13 课后按这个顺序学,别乱
如果你是科研小白,建议按下面 4 步复盘:
- 先看第 3 页核心定义表:把计算图、前向传播、局部导数、链式法则、反向传播、梯度讲顺。
- 再看第 5 页机制流程图:复述“前向计算 → 保存中间量 → 从 Loss 开始 → 局部反传 → 累积梯度 → 更新参数”。
- 然后手算第 6 页例子:用
z=wx+b、a=sigmoid(z)、L=(a-y)^2推一遍∂L/∂w。 - 最后跑本文代码:观察
loss.backward()后w.grad怎么出现。
如果你能做到这 4 件事,这一讲就过关了。
14 一句话总结
本讲可以压缩成一条训练链路:
计算图记录路线
前向传播得到 Loss
局部导数描述每一小段敏感度
链式法则把敏感度串起来
反向传播把梯度传回参数
优化器根据梯度更新参数
再压缩成一句人话:
前向是数据流,反向是梯度流;前向产生错误,反向分摊责任。
下一讲会进入向量化和 Batch:当样本很多、参数很多时,如何用矩阵一次性高效计算。
如果你想系统学习这套“从深度学习到 YOLO26”的课程,可以关注我。第05讲的 PPT、讲义、动画和本文代码练习都可以无偿送给大家。建议收藏本文,课后对着图和代码再走一遍,反向传播就不再是黑盒了。
更多推荐
 9
9 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)