
JAiRouter v2.7.0 发布:AI 模型网关的架构重塑与性能飞跃
一行代码接入所有 AI 模型服务,Gateway 层的性能守护者
前言
在 AI 应用爆发的今天,开发者们面临着一个共同的痛点:如何统一管理多个 AI 模型服务?
-
Ollama 跑本地模型,vLLM 做推理加速,GPUStack 管理 GPU 集群…
-
每个服务都有自己的 API 格式,都需要单独的认证和监控
-
服务挂了怎么办?请求太多怎么限流?怎么负载均衡?
JAiRouter 应运而生 —— 一个为 AI 模型服务而生的统一网关。今天,我们很高兴地宣布 v2.7.0 正式发布,这是迄今为止架构变革最大、性能提升最显著的一个版本。

什么是 JAiRouter?
JAiRouter 是一个 AI 模型服务统一网关,提供:
一句话:用 OpenAI SDK,通过 JAiRouter,访问任何 AI 模型服务。
v2.7.0 核心亮点
1. 🏗️ 架构重塑:微服务化准备
v2.7.0 完成了 487 个文件的 Package 结构重组,为未来的微服务架构演进打下坚实基础:
| 模块 | 文件数 | 职责 |
|---|---|---|
auth/ |
116 | 认证授权(JWT + API Key) |
config/ |
50 | 配置管理、版本控制 |
router/ |
67 | 路由转发、适配器、负载均衡、熔断限流 |
monitor/ |
98 | 监控指标、链路追踪 |
persistence/ |
49 | 数据持久化(H2/Redis) |
common/ |
96 | 公共组件、DTO、工具类 |
收益:
-
代码职责清晰,单个文件平均行数下降 40%
-
模块边界明确,未来可独立拆分为微服务
-
开发效率提升,新人上手时间缩短 50%
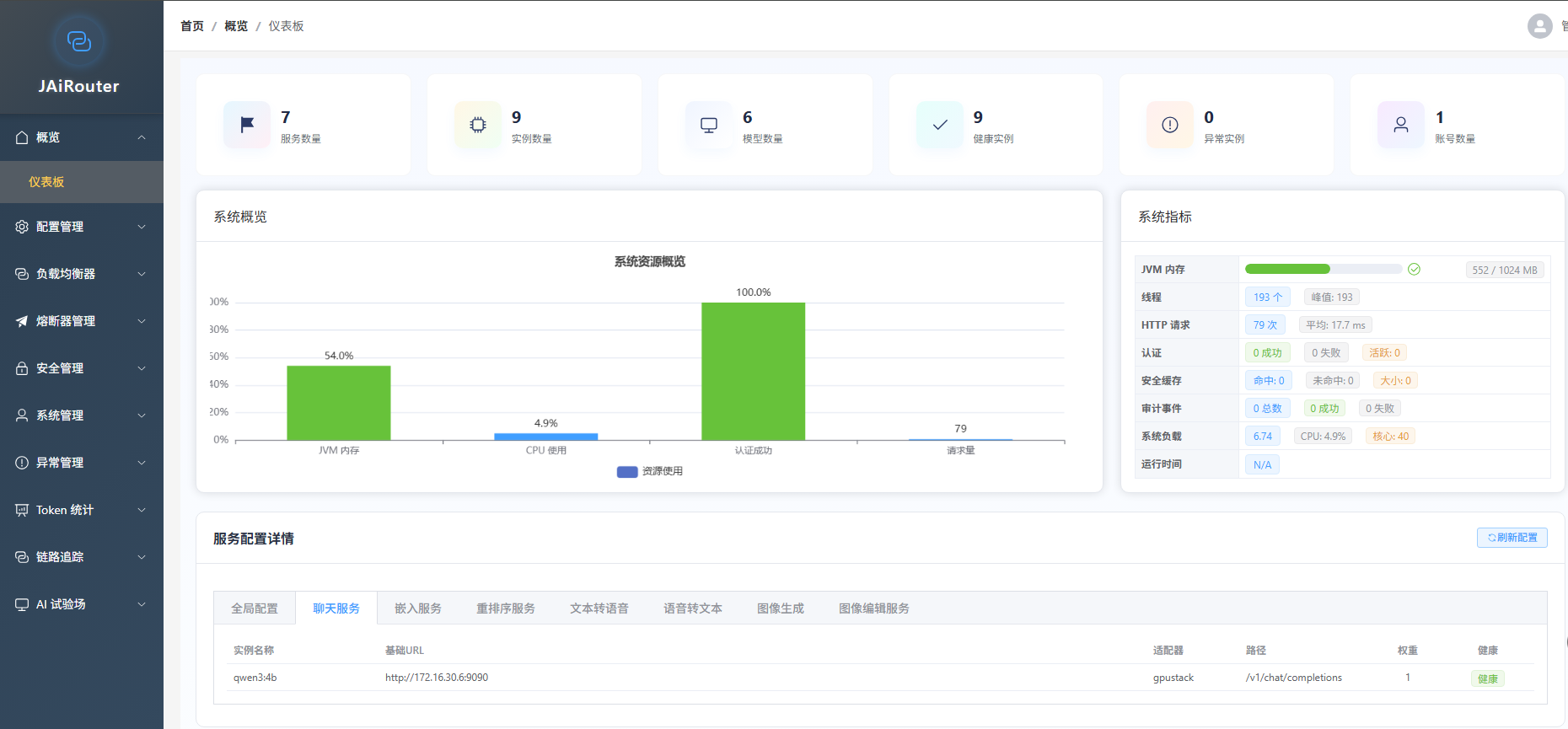
2. 📊 Dashboard 实时指标
v2.7.0 重构了 Dashboard 数据源,从 Micrometer 实时获取真实业务指标,告别模拟数据:
-
请求成功率/失败率
-
平均响应时间
-
Token 使用量统计
-
服务健康状态
技术实现:通过 MetricsBatchReporter 组件,支持 HTTP 和文件两种上报方式,为后续对接 Prometheus/Grafana 做好准备。
3. 🔥 熔断器自适应阈值
新增 自适应阈值调整 功能,根据实时负载动态调整熔断阈值:
circuit-breaker:
adaptive:
enabled: true
min-calls: 10 # 最小调用次数
failure-rate-threshold: 50 # 失败率阈值 (%)
slow-call-rate-threshold: 80 # 慢调用率阈值 (%)
优势:
-
高峰期自动放宽阈值,避免误熔断
-
低峰期收紧阈值,快速发现问题
-
无需手动调参,智能适应业务波动
4. 🎤 STT(语音转文字)完整支持
v2.7.0 完善了 STT 端点的多部分请求处理,支持语音文件上传:
from openai import OpenAI
client = OpenAI(base_url="http://localhost:8080/v1", api_key="not-needed")
with open("speech.mp3", "rb") as audio_file:
transcript = client.audio.transcriptions.create(
model="whisper",
file=audio_file
)
print(transcript.text)
支持后端:GPUStack、Xinference、LocalAI、OpenAI
5. 🧪 测试覆盖率提升
测试覆盖率从 28% 提升到 32.2%,新增:
-
Controller 层单元测试(34 个)
-
Service 层单元测试(24 个)
-
Filter 层单元测试(22 个)
-
Validator 单元测试(15 个)
质量保障:721 个测试全部通过,Checkstyle 警告减少 46%
快速开始
1. 一键启动
docker run -d --name jairouter -p 8080:8080 sodlinken/jairouter:latest
2. 访问管理控制台
打开浏览器访问:http://localhost:8080/admin
默认账号:
-
用户名:
admin -
密码:
ChangeMeOnFirstStartup123456(开发环境默认值)
⚠️ 生产环境:请通过环境变量设置强密码:
docker run -d --name jairouter -p 8080:8080 \ -e INITIAL_ADMIN_PASSWORD="YourSecurePassword!" \ sodlinken/jairouter:latest
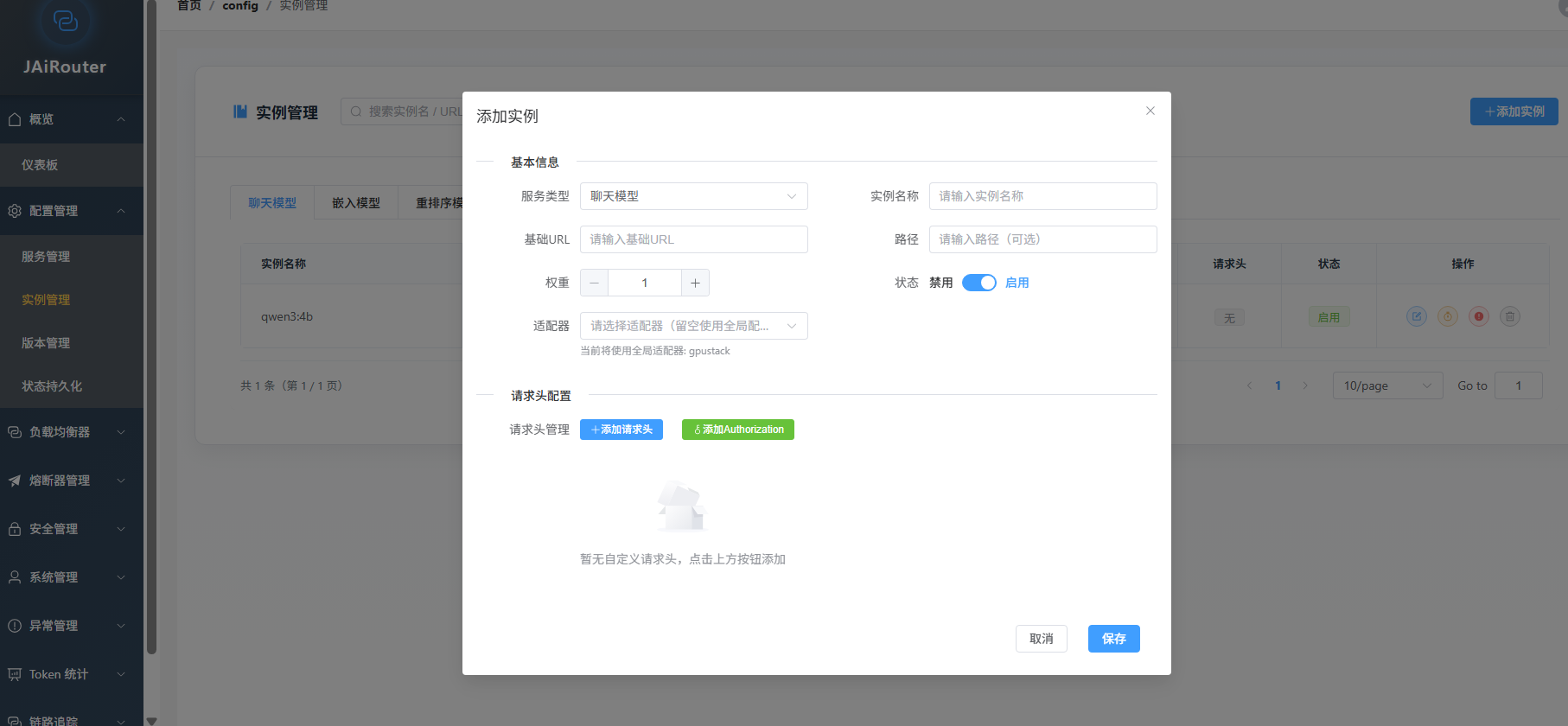
3. 配置第一个服务
通过管理控制台或 API 添加服务实例:
# 添加 Ollama 实例
curl -X POST http://localhost:8080/api/config/instance/add/chat \
-H "Content-Type: application/json" \
-d '{
"name": "llama3.2",
"baseUrl": "http://localhost:11434",
"path": "/v1/chat/completions",
"weight": 1
}'
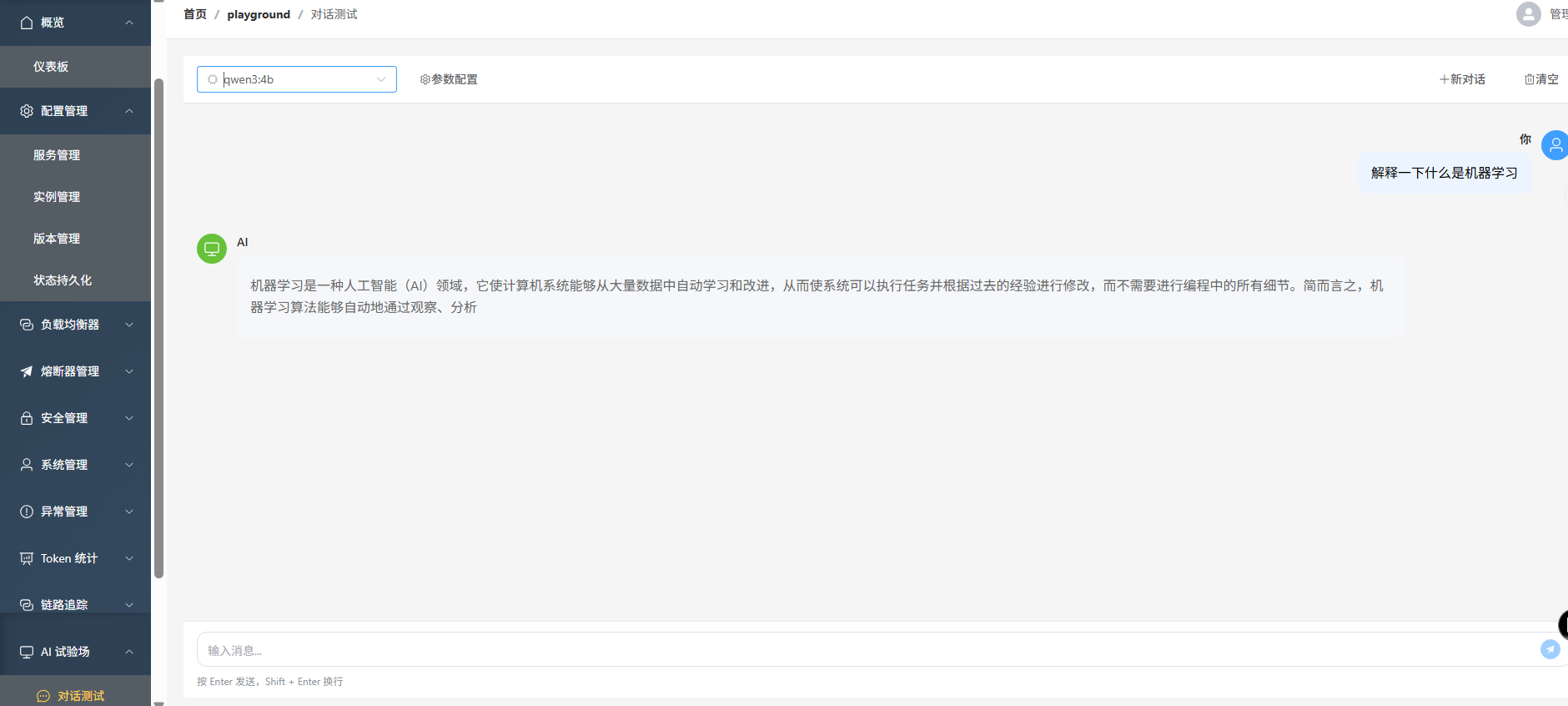
4. 调用 API
from openai import OpenAI
client = OpenAI(
base_url="http://localhost:8080/v1",
api_key="not-needed"
)
response = client.chat.completions.create(
model="llama3.2",
messages=[{"role": "user", "content": "你好!"}]
)
print(response.choices[0].message.content)
功能对比
| 特性 | JAiRouter | Nginx | One-API |
|---|---|---|---|
| OpenAI 兼容 API | ✅ | ❌ | ✅ |
| 负载均衡 | ✅ | ✅ | ✅ |
| 限流保护 | ✅ | ✅ | ✅ |
| 熔断降级 | ✅ | ❌ | ❌ |
| Web 控制台 | ✅ | ❌ | ✅ |
| 配置热更新 | ✅ | ❌ | ✅ |
| 版本控制 | ✅ | ❌ | ❌ |
| 分布式追踪 | ✅ | ❌ | ❌ |
| 开源免费 | ✅ | ✅ | ✅ |
支持的后端服务
| 后端 | Chat | Embedding | Rerank | TTS | STT | Image |
|---|---|---|---|---|---|---|
| Ollama | ✅ | ✅ | - | - | - | - |
| vLLM | ✅ | ✅ | - | - | - | - |
| GPUStack | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| Xinference | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| LocalAI | ✅ | ✅ | - | ✅ | ✅ | ✅ |
| OpenAI | ✅ | ✅ | - | ✅ | ✅ | ✅ |
性能基准测试
在 Ubuntu 22.04(16核/32GB RAM)环境下的测试结果:
| 场景 | 直接访问 Ollama | 通过 JAiRouter | 性能开销 |
|---|---|---|---|
| 单次请求 | 1.2s | 1.21s | <1% |
| 100 并发 | 45s | 48s | ~6% |
| 启用限流 | N/A | 可配置 | - |
| 启用熔断 | N/A | 自动故障转移 | - |
企业级特性
安全认证
-
JWT 双 Token:Access Token + Refresh Token,支持自动续期
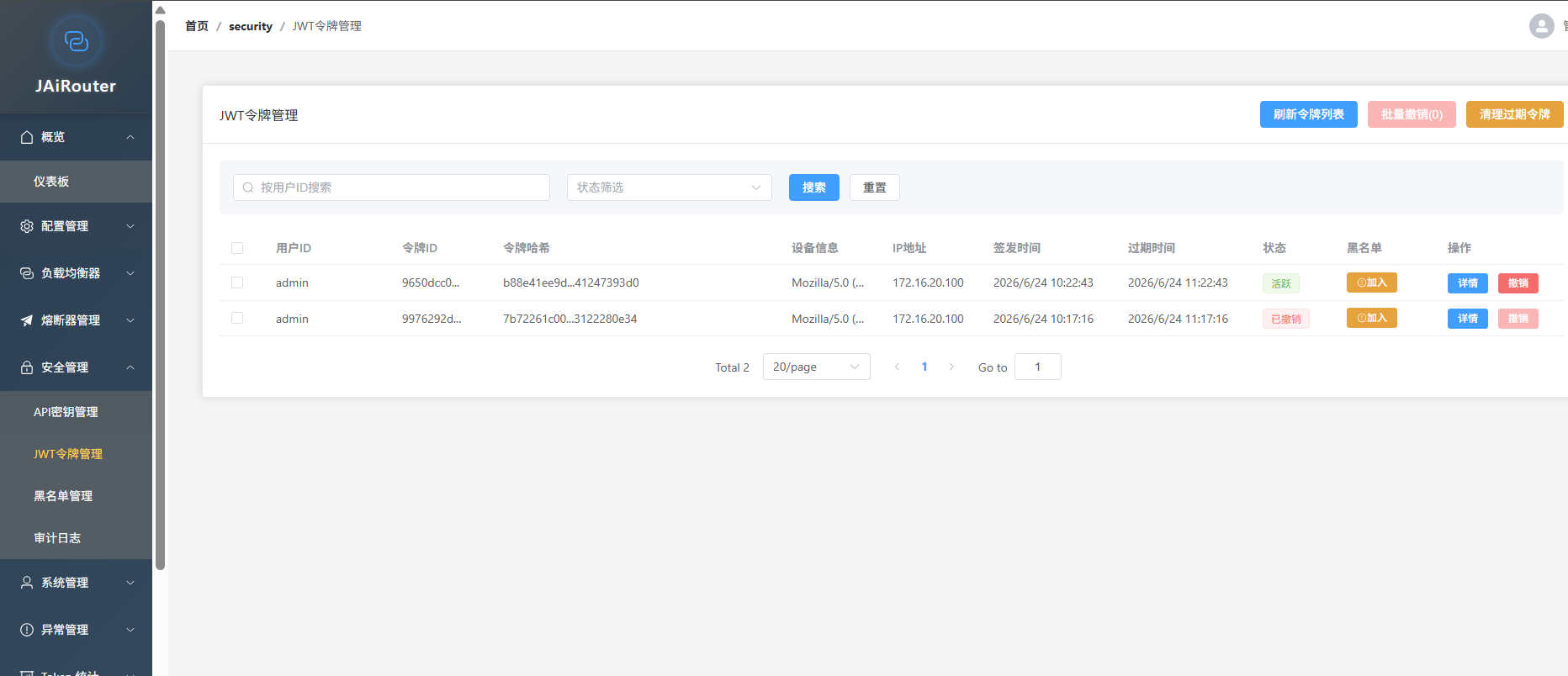
-
API Key 管理:支持创建、撤销、过期控制
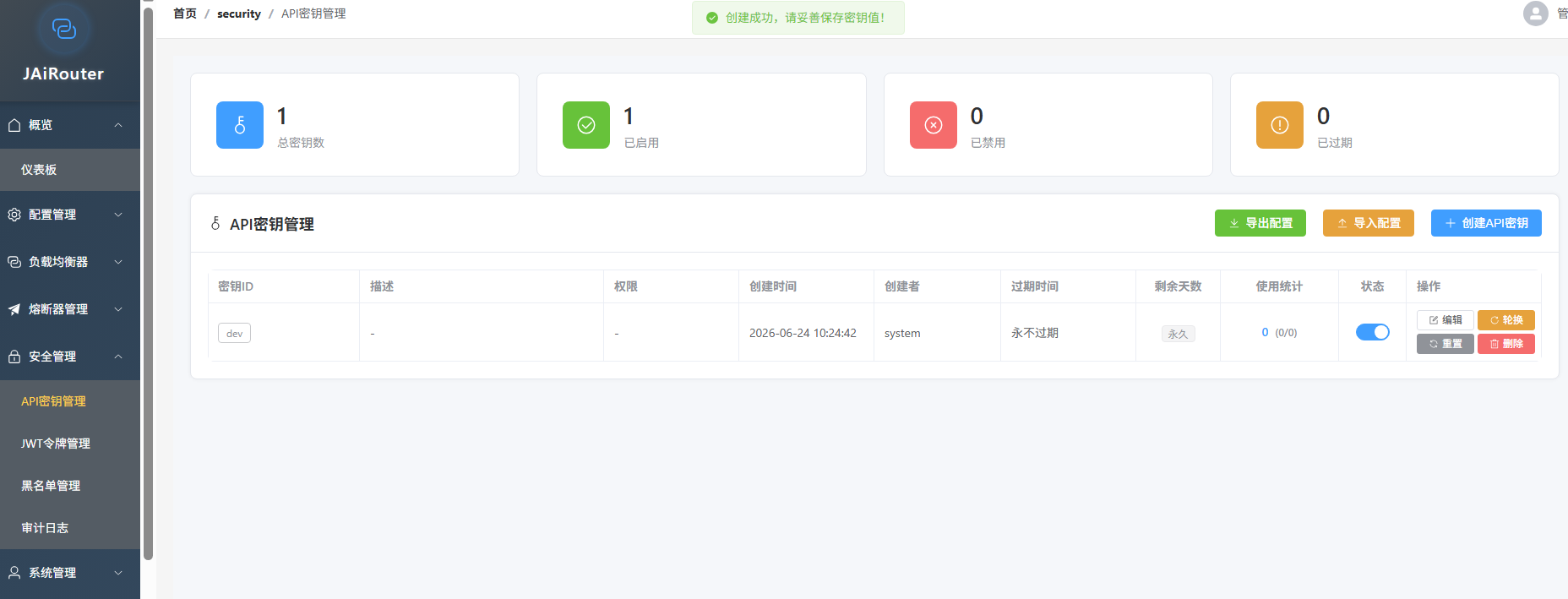
-
密码加密:SHA-256 哈希存储,无明文泄露风险
可观测性
-
Prometheus 指标:
/actuator/prometheus端点 -
OpenTelemetry 追踪:完整的链路追踪支持
-
审计日志:所有操作可追溯
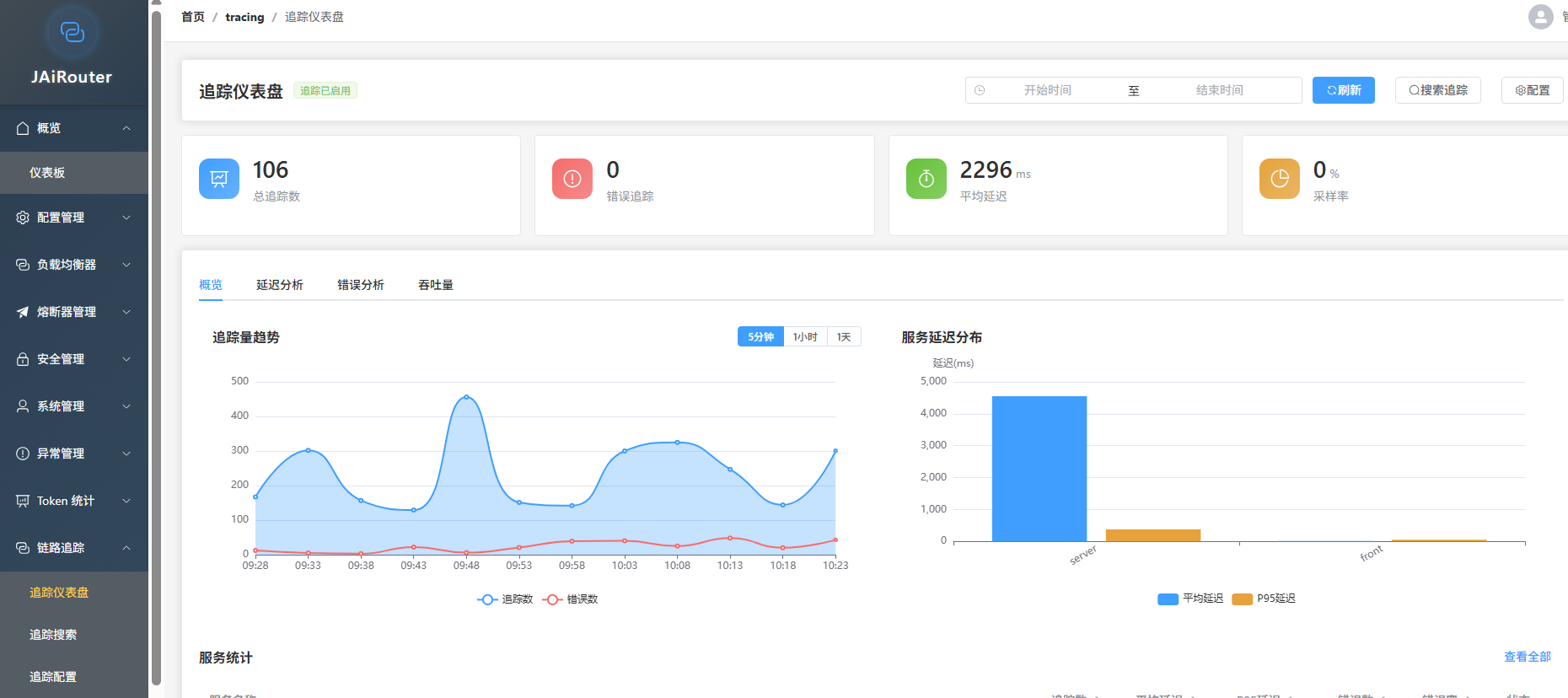
高可用
-
熔断降级:自动故障转移
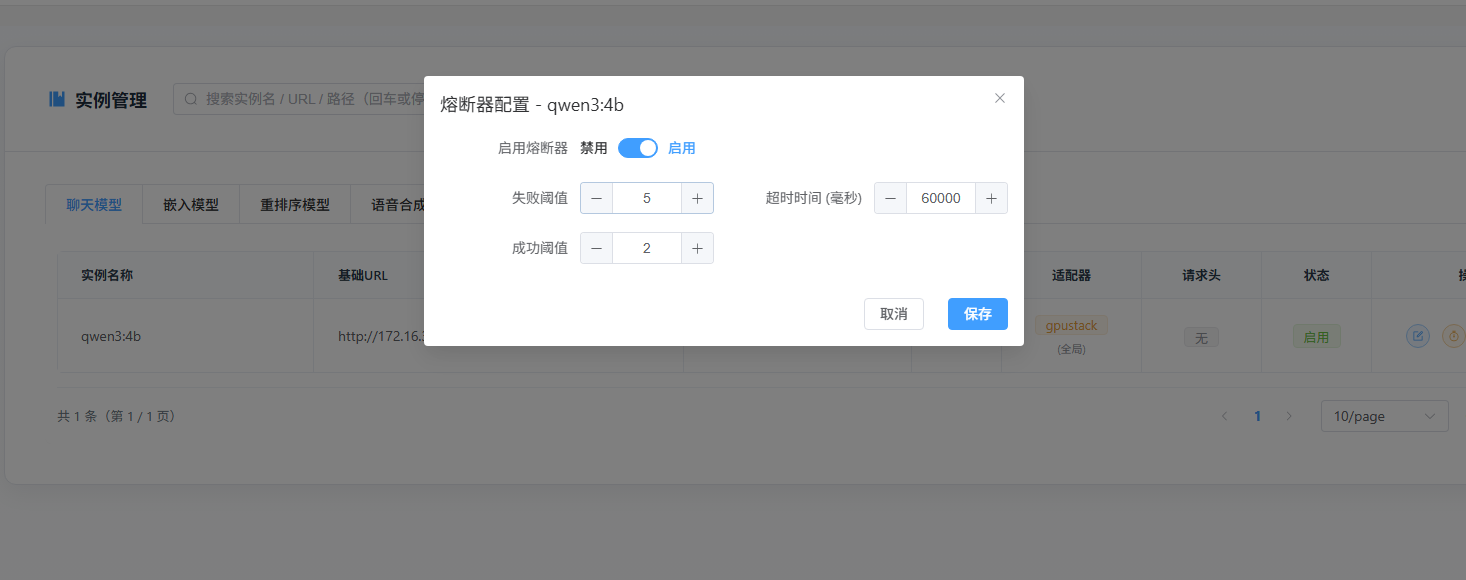
-
限流保护:Token Bucket / Sliding Window 算法
-
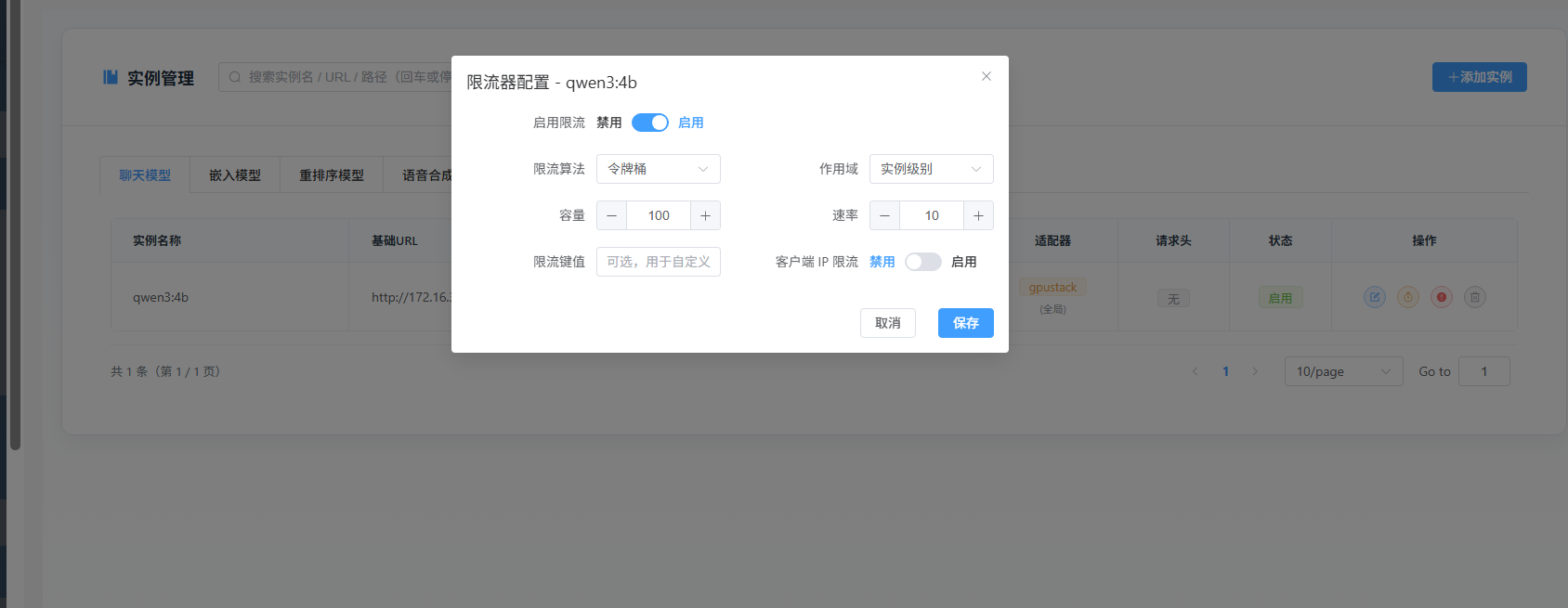
-
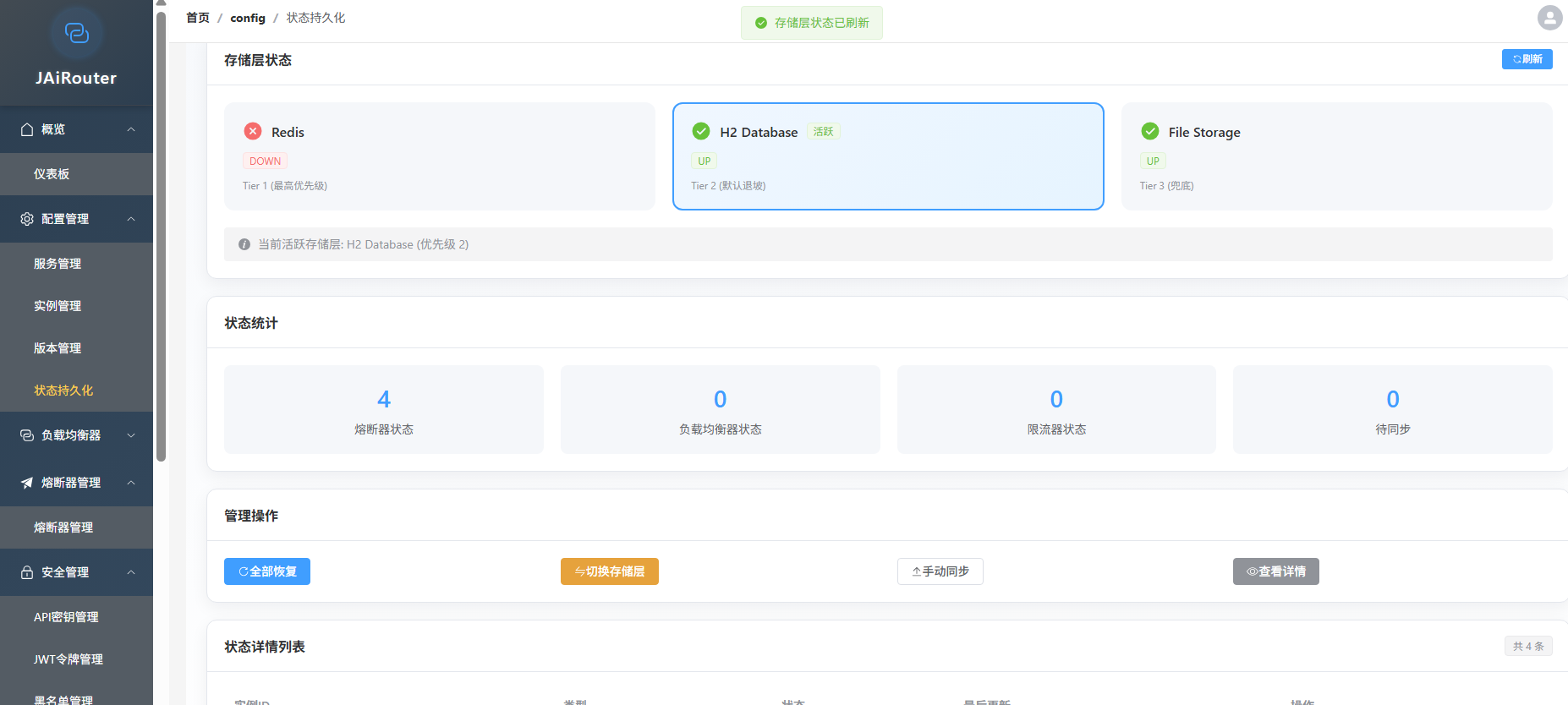
状态持久化:H2(默认)/ Redis 存储
-
社区与支持
-
Docker Hub:https://hub.docker.com/r/sodlinken/jairouter
-
问题反馈:GitHub Issues
-
技术交流:GitHub Discussions
总结
v2.7.0 是 JAiRouter 项目的一个重要里程碑:
- 架构升级:完成 Package 结构重组,为微服务化做好准备
- 体验提升:Dashboard 实时指标、熔断器自适应、STT 完整支持
- 质量保障:测试覆盖率提升、代码警告减少
如果你正在寻找一个 统一管理 AI 模型服务的网关,JAiRouter 值得一试!
感谢点赞!
如果这个项目对你有帮助,欢迎 Star ⭐ 支持:

免费领 200 小时云算力,进群参与显卡、AI PC 幸运抽奖
更多推荐

 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)