
vLLM本地大模型部署实战:环境搭建、模型测试与API服务构建
本文详细介绍了如何使用vLLM在本地搭建高性能大语言模型服务。vLLM凭借PagedAttention和持续批处理技术,可实现最高23倍的吞吐量提升,支持多种量化格式和并行计算。文章对比了vLLM与Ollama、LM Studio的优劣,提供了完整的环境配置、模型下载、代码实现和API服务搭建指南,适合需要高并发、高性能推理的生产环境部署,是程序员学习大模型本地部署的实用指南。
见字如面,与大家分享实践中的经验与思考。
今天来介绍一下如何使用 vLLM 在本地搭建大语言模型。
vLLM 简介
vLLM 是一个快速且易于使用的大语言模型推理和部署库,最初由加州大学伯克利分校的 Sky Computing Lab 开发,现已发展为一个由学术界和工业界共同贡献的社区驱动项目。
核心优势:
- PagedAttention + 持续批处理:内存效率提升,吞吐量最高 23 倍提升
- 量化支持:GPTQ、AWQ、INT4/8、FP8 等多种格式
- 并行计算:张量/流水线/数据/专家并行,支持多 GPU 扩展
- 生态兼容:HuggingFace 集成,OpenAI API 兼容,多 LoRA 支持
- 硬件支持:NVIDIA GPU(主要)、AMD、Intel、TPU、AWS 加速器
数据来源:https://docs.vllm.ai/en/latest/index.html [1]
相较于 Ollama 和 LM Studio,vLLM 在不同场景下各有优势:
| 工具 | 定位 | 适用场景 | 核心优势 | 主要限制 |
|---|---|---|---|---|
| vLLM | 高性能推理引擎 | 生产环境部署、高并发 API 服务 | PagedAttention 内存优化、持续批处理、2.7x 吞吐量提升 | 仅支持 NVIDIA GPU、部署复杂、显存需求大 |
| Ollama | 轻量级本地工具 | 个人开发、快速原型验证、离线环境 | 一键安装、跨平台支持、Docker 风格命令、支持 Apple Silicon | 单用户设计、性能相对较低、功能相对简单 |
| LM Studio | 可视化桌面应用 | 非技术用户、模型探索、教育场景 | 图形界面友好、内置模型市场、支持多模态、零代码体验 | 闭源软件、资源占用较高、定制化程度有限 |
环境准备
硬件: NVIDIA GPU(20GB+ 显存)、16GB+ 内存、50GB+ SSD 存储
软件: Linux/macOS/Windows、Python 3.8-3.12、CUDA 11.8+、uv/pip
测试环境: macOS 15.6、Python 3.12、UV 0.7.3 、PyTorch 2.0+、ModelScope(国内用户推荐)或 Hugging Face
项目准备
使用 uv 搭建 PyTorch 环境,可以参考官方文档:https://docs.astral.sh/uv/guides/integration/pytorch/。 [2]
01 项目初始化
## 新建项目
mkdir vllm-rag
cd vllm-rag
uv init --python 3.12
source .venv/bin/activate
## 添加核心依赖
uv add torch modelscope vllm
依赖说明:
torch: PyTorch 深度学习框架vllm: 高性能大模型推理引擎modelscope: 阿里云模型下载工具
初始化之后:
02 验证 PyTorch 环境
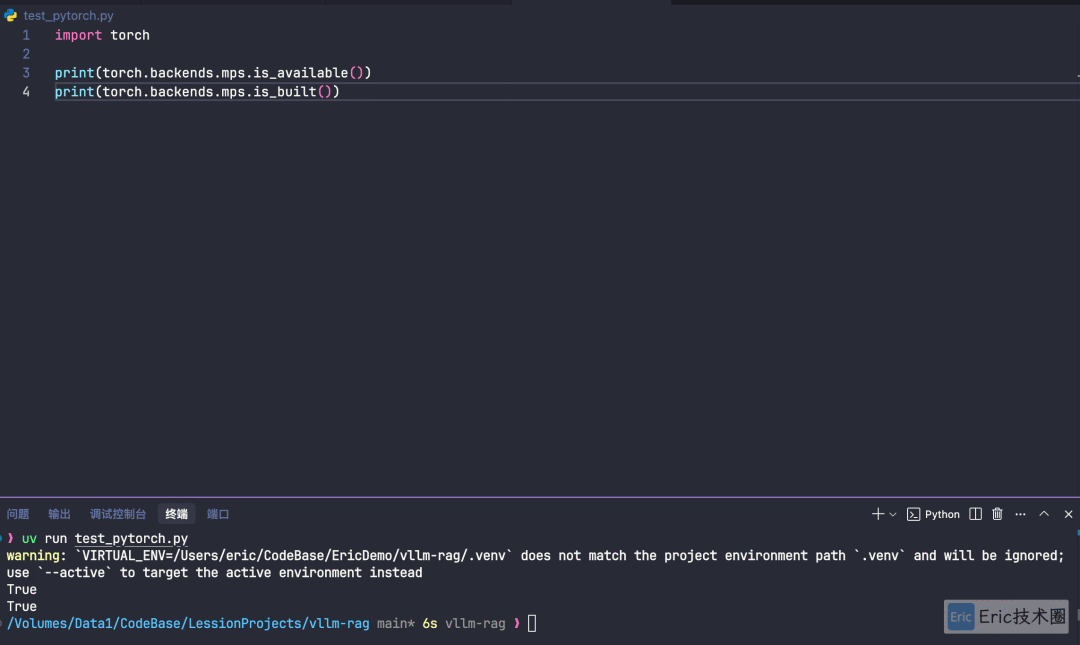
验证本地是否支持 PyTorch ,并且安装成功。
uv run test_pytorch.py
测试结果:
03 模型下载与管理
vLLM 默认从 Hugging Face 下载模型,但建议提前下载以避免运行时等待,同时便于模型版本管理。
使用 ModelScope(推荐,国内网络友好)
# model_download.py
from modelscope import snapshot_download
model_dir = snapshot_download('Qwen/Qwen3-8B', cache_dir='/Volumes/Data1/LLMs/vllm/models', revision='master')
注意:将 cache_dir 改成你的本地目录。
uv run model_download.py
等待模型下载:
vLLM 实测
使用 Qwen/Qwen3-8B 模型进行测试,预计占用 16-20GB 显存。
01 Python 代码编写
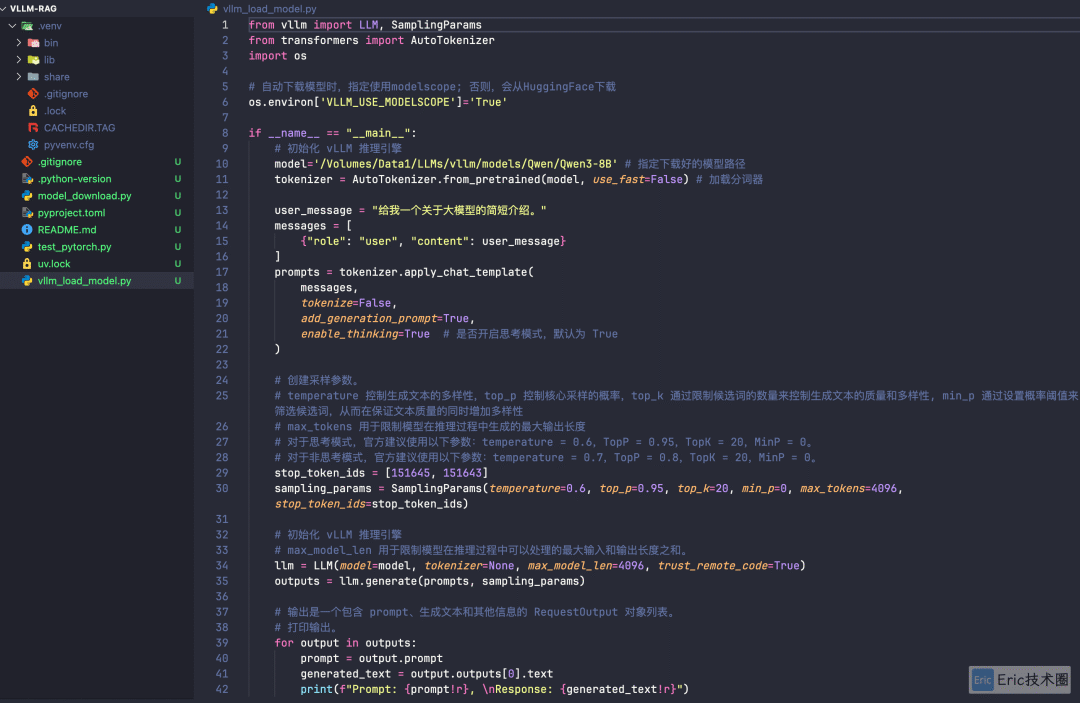
02 测试结果
思考模式结果:

输出内容如下:
Prompt: '<|im_start|>user\n给我一个关于大模型的简短介绍。<|im_end|>\n<|im_start|>assistant\n',
Response: '<think>\n好的,用户让我提供一个关于大模型的简短介绍。首先,我需要确定用户的需求是什么。他们可能是一个学生,或者对AI领域感兴趣的人,想要快速了解大模型的基本概念。也有可能是在做研究,需要简要的概述。\n\n接下来,我得考虑大模型的定义。大模型通常指的是参数量巨大的深度学习模型,比如Transformer架构,这些模型在自然语言处理、计算机视觉等领域有广泛应用。需要提到它们的规模,比如参数数量,以及训练数据量,因为这些都是关键点。\n\n然后,用户可能想知道大模型的特点。比如,它们的强大学习能力,能够处理多种任务,还有预训练和微调的概念。这些都是大模型的核心优势,应该涵盖进去。\n\n还要注意用户可能的深层需求。他们可能想了解大模型的实际应用,比如聊天机器人、文本生成、图像识别等。所以需要举几个例子,让介绍更具体。\n\n另外,用户可能对大模型的挑战感兴趣,比如计算资源需求高、训练成本大,以及可能的伦理问题。不过因为要求是简短介绍,这部分可能需要简要提及,避免过于深入。\n\n需要确保语言简洁明了,避免技术术语过多,让不同背景的读者都能理解。同时,保持结构清晰,分点或分段介绍,但用户要求的是简短,所以可能需要整合成一段流畅的文字。\n\n最后,检查是否有遗漏的重要信息,比如大模型的发展趋势,比如多模态模型、自监督学习等,但可能因为篇幅限制,只能简要带过。确保整体内容准确,没有错误信息,比如参数量的范围,训练数据量等,需要准确的数据支持。\n</think>\n\n大模型(Large Language Models, LLMs)是基于深度学习的参数量巨大的人工智能模型,通常包含数十亿甚至数万亿个参数。它们通过海量文本数据训练,具备强大的语言理解、生成和推理能力,可完成文本生成、问答、代码编写、多语言翻译等复杂任务。典型代表如GPT、BERT、PaLM等。大模型的核心优势在于其泛化能力,能通过预训练和微调适应多种应用场景,但同时也面临算力消耗高、训练成本大等挑战。'
非思考模式结果:
将 enable_thinking=False 并调整推理参数,再次验证。

输出内容如下:
Prompt: '<|im_start|>user\n给我一个关于大模型的简短介绍。<|im_end|>\n<|im_start|>assistant\n<think>\n\n</think>\n\n',
Response: '大模型(Large Model)是指参数量巨大、具有强大语言理解和生成能力的深度学习模型,通常基于Transformer架构。它们能够处理复杂的自然语言任务,如文本生成、翻译、问答、代码编写等。大模型通过海量数据训练,具备强大的泛化能力和上下文理解能力,广泛应用于人工智能的多个领域,如智能客服、内容创作、数据分析等。代表模型包括GPT、BERT、Ernie Bot等。'
vLLM 搭建类 OpenAI 服务
使用如下命令进行启动:
VLLM_USE_MODELSCOPE=true vllm serve \
/Volumes/Data1/LLMs/vllm/models/Qwen/Qwen3-8B \
--served-model-name Qwen3-8B \
--max_model_len 2048 \
--reasoning-parser deepseek_r1
启动结果:
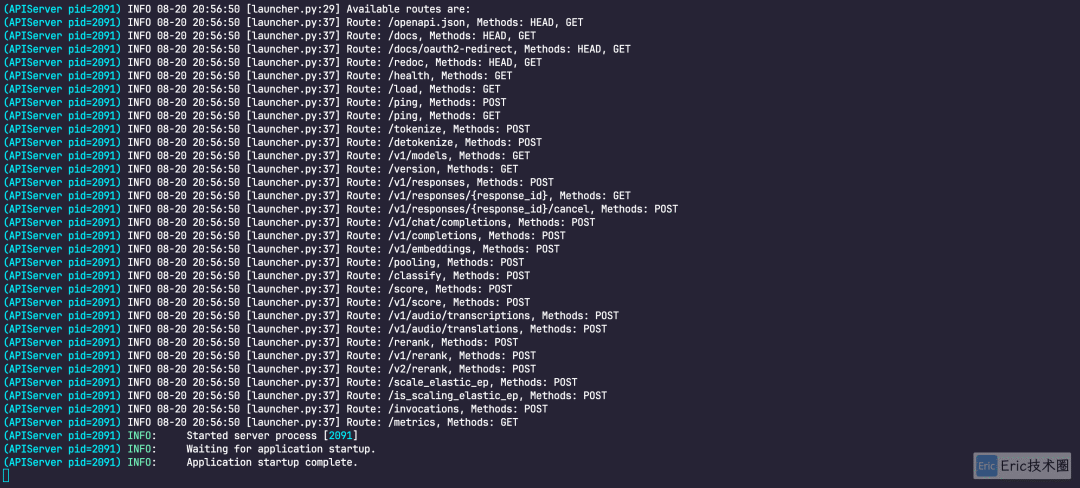
模型信息:
curl http://localhost:8000/v1/models
{
"object":"list",
"data":[
{
"id":"Qwen3-8B",
"object":"model",
"created":1755695146,
"owned_by":"vllm",
"root":"/Volumes/Data1/LLMs/vllm/models/Qwen/Qwen3-8B",
"parent":null,
"max_model_len":2048,
"permission":[
{
"id":"modelperm-3194bd05ecd64efeb188c172ae14804b",
"object":"model_permission",
"created":1755695146,
"allow_create_engine":false,
"allow_sampling":true,
"allow_logprobs":true,
"allow_search_indices":false,
"allow_view":true,
"allow_fine_tuning":false,
"organization":"*",
"group":null,
"is_blocking":false
}
]
}
]
}
简单问题测试:
curl --location 'http://localhost:8000/v1/completions' \
--header 'Content-Type: application/json' \
--data '{
"model": "Qwen3-8B",
"prompt": "/no_think 3的阶乘是多少?",
"max_tokens": 2000,
"temperature": 0
}'
输出结果:
{
"id":"cmpl-fb6ecf0c554d4ad984cabc9e8a7fc53a",
"object":"text_completion",
"created":1757429422,
"model":"Qwen3-8B",
"choices":[
{
"index":0,
"text":" 3的阶乘是3×2×1=6。所以,3的阶乘是6。",
"logprobs":null,
"finish_reason":"stop",
"stop_reason":null,
"prompt_logprobs":null
}
],
"service_tier":null,
"system_fingerprint":null,
"usage":{
"prompt_tokens":10,
"total_tokens":34,
"completion_tokens":24,
"prompt_tokens_details":null
},
"kv_transfer_params":null
}
总结
vLLM 作为高性能的大语言模型推理框架,在生产环境和高并发场景下表现出色。通过 PagedAttention 等创新技术,它能够显著提升推理吞吐量和内存利用效率。
选择建议:
- 个人学习和快速验证:推荐使用 Ollama,简单易用
- 非技术用户和模型探索:推荐使用 LM Studio,界面友好
- 生产部署和高性能需求:推荐使用 vLLM,性能卓越
随着本地大模型技术的不断发展,这些工具都在各自的定位上持续优化,为不同需求的用户提供了丰富的选择。
引用链接
[1]: https://docs.vllm.ai/en/latest/index.html
能够显著提升推理吞吐量和内存利用效率。
选择建议:
- 个人学习和快速验证:推荐使用 Ollama,简单易用
- 非技术用户和模型探索:推荐使用 LM Studio,界面友好
- 生产部署和高性能需求:推荐使用 vLLM,性能卓越
随着本地大模型技术的不断发展,这些工具都在各自的定位上持续优化,为不同需求的用户提供了丰富的选择。
零基础如何高效学习大模型?
你是否懂 AI,是否具备利用大模型去开发应用能力,是否能够对大模型进行调优,将会是决定自己职业前景的重要参数。
为了帮助大家打破壁垒,快速了解大模型核心技术原理,学习相关大模型技术。从原理出发真正入局大模型。在这里我和鲁为民博士系统梳理大模型学习脉络,这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码免费领取🆓**⬇️⬇️⬇️

【大模型全套视频教程】
教程从当下的市场现状和趋势出发,分析各个岗位人才需求,带你充分了解自身情况,get 到适合自己的 AI 大模型入门学习路线。
从基础的 prompt 工程入手,逐步深入到 Agents,其中更是详细介绍了 LLM 最重要的编程框架 LangChain。最后把微调与预训练进行了对比介绍与分析。
同时课程详细介绍了AI大模型技能图谱知识树,规划属于你自己的大模型学习路线,并且专门提前收集了大家对大模型常见的疑问,集中解答所有疑惑!

深耕 AI 领域技术专家带你快速入门大模型
跟着行业技术专家免费学习的机会非常难得,相信跟着学习下来能够对大模型有更加深刻的认知和理解,也能真正利用起大模型,从而“弯道超车”,实现职业跃迁!
【精选AI大模型权威PDF书籍/教程】
精心筛选的经典与前沿并重的电子书和教程合集,包含《深度学习》等一百多本书籍和讲义精要等材料。绝对是深入理解理论、夯实基础的不二之选。

【AI 大模型面试题 】
除了 AI 入门课程,我还给大家准备了非常全面的**「AI 大模型面试题」,**包括字节、腾讯等一线大厂的 AI 岗面经分享、LLMs、Transformer、RAG 面试真题等,帮你在面试大模型工作中更快一步。
【大厂 AI 岗位面经分享(92份)】

【AI 大模型面试真题(102 道)】

【LLMs 面试真题(97 道)】

【640套 AI 大模型行业研究报告】

【AI大模型完整版学习路线图(2025版)】
明确学习方向,2025年 AI 要学什么,这一张图就够了!

👇👇点击下方卡片链接免费领取全部内容👇👇
抓住AI浪潮,重塑职业未来!
科技行业正处于深刻变革之中。英特尔等巨头近期进行结构性调整,缩减部分传统岗位,同时AI相关技术岗位(尤其是大模型方向)需求激增,已成为不争的事实。具备相关技能的人才在就业市场上正变得炙手可热。
行业趋势洞察:
- 转型加速: 传统IT岗位面临转型压力,拥抱AI技术成为关键。
- 人才争夺战: 拥有3-5年经验、扎实AI技术功底和真实项目经验的工程师,在头部大厂及明星AI企业中的薪资竞争力显著提升(部分核心岗位可达较高水平)。
- 门槛提高: “具备AI项目实操经验”正迅速成为简历筛选的重要标准,预计未来1-2年将成为普遍门槛。
与其观望,不如行动!
面对变革,主动学习、提升技能才是应对之道。掌握AI大模型核心原理、主流应用技术与项目实战经验,是抓住时代机遇、实现职业跃迁的关键一步。

01 为什么分享这份学习资料?
当前,我国在AI大模型领域的高质量人才供给仍显不足,行业亟需更多有志于此的专业力量加入。
因此,我们决定将这份精心整理的AI大模型学习资料,无偿分享给每一位真心渴望进入这个领域、愿意投入学习的伙伴!
我们希望能为你的学习之路提供一份助力。如果在学习过程中遇到技术问题,也欢迎交流探讨,我们乐于分享所知。
*02 这份资料的价值在哪里?*
专业背书,系统构建:
-
本资料由我与鲁为民博士共同整理。鲁博士拥有清华大学学士和美国加州理工学院博士学位,在人工智能领域造诣深厚:
-
- 在IEEE Transactions等顶级学术期刊及国际会议发表论文超过50篇。
- 拥有多项中美发明专利。
- 荣获吴文俊人工智能科学技术奖(中国人工智能领域重要奖项)。
-
目前,我有幸与鲁博士共同进行人工智能相关研究。

内容实用,循序渐进:
-
资料体系化覆盖了从基础概念入门到核心技术进阶的知识点。
-
包含丰富的视频教程与实战项目案例,强调动手实践能力。
-
无论你是初探AI领域的新手,还是已有一定技术基础希望深入大模型的学习者,这份资料都能为你提供系统性的学习路径和宝贵的实践参考,助力你提升技术能力,向大模型相关岗位转型发展。



抓住机遇,开启你的AI学习之旅!

免费领 200 小时云算力,进群参与显卡、AI PC 幸运抽奖
更多推荐

 39
39 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)