[ICLR 2020]Decoupling Representation and Classifier for Long-Tailed Recognition
计算机-人工智能-图像分类长尾问题ResNet骨干上对于不同采样和权重的测试

论文网址:Decoupling Representation and Classifier for Long-Tailed Recognition | OpenReview
论文代码:https://github.com/facebookresearch/classifier-balancing
目录
2.4. Learning Representations for Long-tailed Recognition
2.5. Classification for Long-tailed Recognition
2.6.2. Sampling Strategies and Decoupled Learning
2.6.3. How to Balance your Classifier?
2.6.4. Comparison with the State-of-the-art on Long-tailed Datasets
1. 心得
(1)在这个AI横行的时代博主精读似乎也没什么大用
(2)当年的多阶段还是引出了不少别致的思考
(3)更适合新手宝宝看,对于已经很熟悉的人这个就有点基础了
(4)有一点偏测试论文了...为什么网上能给到如此高的评价?虽然说20年是很早,但这个也没有配数学证明之类的
2. 论文逐段精读
2.1. Abstract
①现有对于长尾问题的解决方法:损失重加权,数据重采样,迁移学习(不过这个现有都是2020了,随缘参考吧
2.2. Introduction
①作者在尝试解耦(decoupling)学习,emm还不知道是什么继续读一下
2.3. Related Work
①使用数据重采样,把多的欠采集一点,把少的过采集一点
②为每个类别样本设计不同的权重
③把在头部类的学习的迁移到尾部类
2.4. Learning Representations for Long-tailed Recognition
(1)Notation
①训练集:,其中
是一个数据点,
是对应的标签
②表示类别
的样本数量,因此用
加总也可以得到所有样本数
③假设越前面的类别样本数量越多(就是那个最典的长尾图),因此满足,
④模型特征提取:,其中
可能是个CNN,
是它的参数
⑤预测:,其中
分类器可以是线性层
(2)Sampling strategies
①在第类中采样数据的概率
为:
其中,
是训练总类别。在不同的采样策略下
可能会等于
:
| Instance-balanced sampling | 每一个样本都有相同的概率被采样到(这是不是没p用采集完了和原始分布一样....只是降低样本数量了 | |
| Class-balanced sampling | 给每个类别同样的采样率 | |
| Square-root sampling | 平方根采样率哈哈哈 |
这些就稍微定死一点,现有工作和作者都采用了混合的办法,作者加工了一下使得混合方法更为柔和,他们令:
其中是epoch,
是总共的epoch,相当于这个是在较前面的epoch更多使用契合原始分布的采样而到后期更多使用类均匀采样
interpolate vt. 篡改;插入新语句 vi. 插入;篡改
2.5. Classification for Long-tailed Recognition
①Classifier Re-training (cRT):应该是两阶段的训练,第一阶段训练表征,第二阶段固定表征然后使用类平衡采样随机重新初始化和优化分类器权重和偏置
②Nearest Class Mean classifier (NCM):有点像聚类
③-normalized classifier (τ -normalized):缩放分类权重
至
:
其中是温度超参数,
是L2正则。最终分类变为
然后舍弃了偏置项
④Learnable weight scaling (LWS):将缩放因子变成可学习的,权重为
2.6. Experiments
2.6.1. Experimental Setup
①数据集:Places-LT(365类,5~4980样本/类),ImageNet-LT(1000类,5~1280样本/类)和iNaturalist 2018(8142类)
②实验:多镜头(超过100张图像)、中镜头(20张至100张图像)和少镜头(少于20张图像)
③骨干网络:ResNet-152
④优化器:SGD,动量为0.9,学习率从0.2衰减到0
⑤输入图像大小:224×224
⑥Epoch:骨干网络训练90个,分类器重新训练10个
2.6.2. Sampling Strategies and Decoupled Learning
①使用ResNeXt-50在ImageNet-LT上进行不同样本量任务时不同分类器和不同采样方法下的性能:
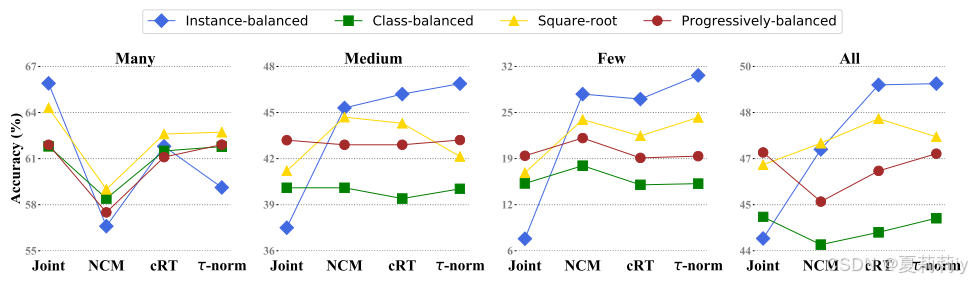
作者认为调节权重缩放因子更重要,而不是通过采样来学习
2.6.3. How to Balance your Classifier?
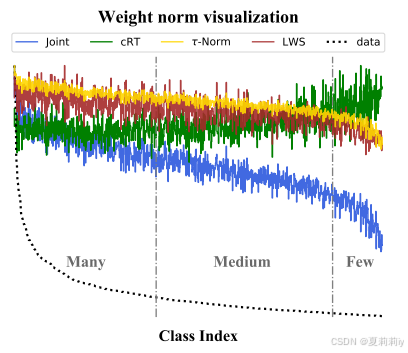
①真实数据分布以及不同分类器对不同类别给到的权重:
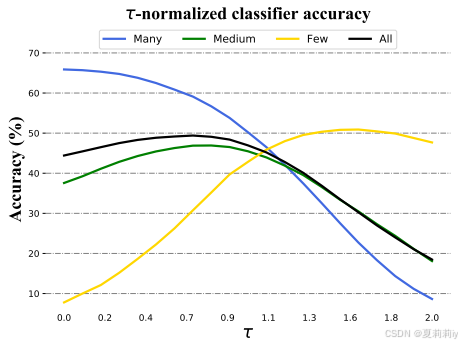
②的选择实验:
2.6.4. Comparison with the State-of-the-art on Long-tailed Datasets
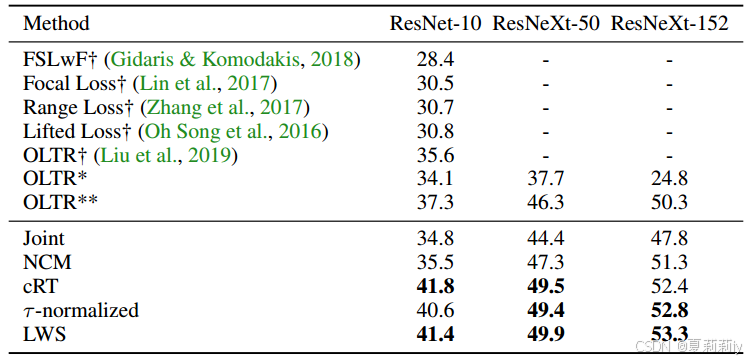
①在ImageNet-LT上的对比实验:
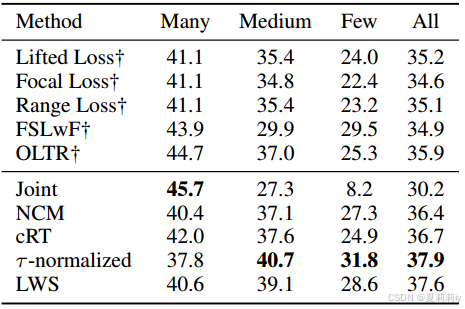
②iNaturalist 2018数据集上的对比实验:
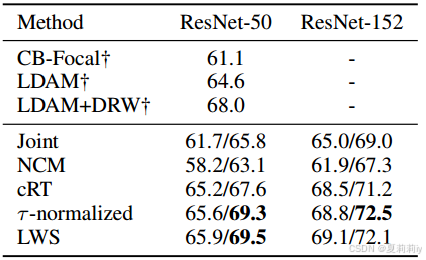
③Places-LT数据集上的对比实验:
2.7. Conclusion
~

分享最新、最前沿的AI大模型技术,吸纳国内前几批AI大模型开发者
更多推荐
 15
15 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)