
【程序员必藏】从零构建大模型文档解析系统:LangGraph+MCP实战,自动生成带图表报告
全流程自动化:从上传到报告生成,无需人工干预高精度解析:结合 MinerU 与 PyMuPDF,兼顾速度与准确性安全可控:支持私有化部署,数据不出内网可扩展性强:基于 LangGraph 的多Agent架构,易于扩展新功能。
【程序员必藏】从零构建大模型文档解析系统:LangGraph+MCP实战,自动生成带图表报告
本文介绍基于LangGraph和MCP的智能文档处理系统,可自动解析多种格式文档(PDF、Word、PPT等),提取关键信息并生成结构化报告。系统采用PyMuPDF+MinerU框架进行文档解析,结合多Agent架构实现高效处理,支持私有化部署保障数据安全。全流程无需人工干预,可扩展性强,为企业文档处理提供了自动化解决方案。
大模型如何读懂任何格式文件并自动生成报告?LangGraph + MCP 实战解析
无需人工干预,上传任何文件即可生成带图表的报告,支持私有化部署。
作者:大模型知识分享员
发布时间:2025年10月11日
在信息爆炸的时代,企业每天都在产生海量的非结构化文档——市场调研报告、用户反馈、技术白皮书、会议纪要……如何从中快速提取关键信息并生成结构化、可操作的分析报告,已成为企业提升决策效率的核心挑战。
传统的人工阅读与摘要方式效率低下、成本高昂,且难以保证一致性。如今,借助大语言模型(LLM)与智能体(Agent)技术,我们能够构建一个端到端的“文档解析 → 信息抽取 → 报告生成”自动化流水线,让大模型成为你的“智能分析师”,大幅提升知识处理效率。
🎬 运行效果预览
🎯 核心价值
- 自动化摘要:无需人工阅读,自动提取文档核心内容与关键论点。
- 多格式支持:兼容PDF、Word、PPT、TXT、HTML等多种文档格式。
- 结构化输出:将非结构化文本转化为表格、图表、思维导图等可视化形式。
- 私有化部署:支持本地或内网部署,保障敏感文档数据安全。
- 可扩展智能体架构:基于 LangGraph 与 MCP 协议构建多Agent协作系统,实现复杂任务分解。
🧭 本文结构概览
- 环境准备:搭建文档解析与报告生成基础环境
- 核心逻辑:大模型如何理解文档并生成结构化报告
- 智能体协同:构建Agent+MCP,分工协作生成报告
- 总结与展望:完整方案与未来优化方向
1️⃣ 环境准备:搭建智能文档处理中枢
- 文档解析框架对比私有化部署采用PyMuPDF+MinerU方案
| 特性 | MarkItDown | Docling | Marker | 微软云 Azure Document Intelligence | PyMuPDF | MinerU |
|---|---|---|---|---|---|---|
| 速度 | ⭐⭐⭐⭐⭐ (最快) Office 文档转换达 200页/分钟 | ⭐⭐⭐⭐☆ (中等) PDF 多栏解析约 3 分钟/50 页 | ⭐⭐☆☆☆ (较慢) 复杂公式识别需 10–15 秒/页 | ⭐⭐⭐⭐☆ (云端加速) API 响应 <5 秒 | ⭐⭐⭐⭐⭐ (纯文本提取) 每秒处理 10+ 页 | ⭐★☆☆☆ (最慢) 财务报表解析需 5 分钟/100 页 |
| 准确性 | ⭐⭐⭐☆☆ (良好) PDF 多栏识别率 85% | ⭐⭐⭐⭐☆ (很好) 法律合同条款提取准确率 91% | ⭐⭐⭐⭐⭐ (优秀) 手写公式识别率 95% | ⭐⭐⭐⭐☆ (优秀) 微软研究院模型支持 | ⭐⭐☆☆☆ (基础) 无 OCR 能力 | ⭐⭐⭐⭐⭐ (卓越) 学术论文转换评分 4.8/5 |
| 表格处理 | ⭐⭐⭐☆☆ (基础) 嵌套表格易错位 | ⭐⭐⭐⭐☆ (高级) 跨页表格合并支持 | ⭐⭐⭐⭐⭐ (卓越) 财务报表误差率 0.5% | ⭐⭐⭐⭐☆ (智能) 支持合并单元格识别 | ⭐☆☆☆☆ (无) | ⭐⭐⭐⭐⭐ (多模态) 集成 TableFormer 模型 |
| 公式支持 | ⭐☆☆☆☆ (有限) 仅保留为图片 | ⭐⭐⭐☆☆ (中等) Mathpix 接口转换 | ⭐⭐⭐⭐⭐ (优秀) UniMERNNet 模型支持 | ⭐☆☆☆☆ (基础) | ⭐☆☆☆☆ (无) | ⭐⭐⭐⭐⭐ (学术级) LaTeX 转换率 98% |
| 图片提取 | ⭐☆☆☆☆ (基本OCR) Tesseract 引擎 | ⭐⭐⭐⭐☆ (VLM支持) CLIP 图文关联 | ⭐⭐⭐⭐⭐ (详细) YOLOv8 + SAM 模型 | ⭐⭐⭐⭐☆ (智能标注) | ⭐⭐☆☆☆ (基础) | ⭐⭐⭐⭐⭐ (对象级) 图像分类准确率 97% |
| 资源占用 | ⭐⭐⭐⭐⭐ (最小) CPU 模式 <500MB | ⭐⭐☆☆☆ (大量) 需 8GB 显存 | ⭐⭐☆☆☆ (大量) 需 16GB 显存 | ☆☆☆☆☆ (云端) | ⭐⭐⭐⭐⭐ (轻量) | ⭐☆☆☆☆ (最高) 需 32GB 内存 |
| 最适用于 | Office文档 PPT 转换 30 页/秒 | PDF文档 合同条款提取 | 含表格/公式文档 学术论文 | 企业级批量处理 | 基础文本提取 | 多模态复杂文档 |
| GPU加速 | 否 | 是(CUDA 11.8) | 是(多卡并行) | 云端自动 | 否 | 是(NVIDIA A100) |
| 支持的格式 | DOC/XLS/PPT/PDF/图像/音频等 20+ 格式 | PDF/DOCX/PPTX/HTML | PDF/DOCX/PPTX/HTML | PDF/图像/Office | PDF/EPUB/MOBI | |
| 输出格式 | Markdown | Markdown/JSON | Markdown/JSON | JSON/CSV | 文本 | JSON/知识图谱 |
1.1 部署文档解析服务
1.1.1 安装依赖包
uv add pymupdf4llmuv add pymupdfuv add python-docxuv add pandas
1.1.2 MinerU安装
- MinerU官方文档地址: https://opendatalab.github.io/MinerU/zh
docker run --gpus all \ --shm-size 32g \ -p 30000:30000 -p 7860:7860 -p 8000:8000 \ --ipc=host \ -it mineru-vllm:latest \ /bin/bash
2️⃣ 文件上传与解析核心逻辑详解
🧩 功能概览
- ✅ 接收 HTTP 上传的文件
- ✅ 校验文件类型与大小
- ✅ 支持扫描件 OCR 识别
- ✅ 解析主流文档格式为纯文本或结构化数据
- ✅ 上传原始文件和解析后文本到 MinIO
- ✅ 返回结构化结果(包含源文件 Key、解析文件 Key、文件大小)
🔍 核心函数:upload_file_and_parse_from_request
```pythondef upload_file_and_parse_from_request(self, request: Request, bucket_name: str = "filedata") -> dict: """ 上传文件并解析内容,支持调用私有化 MinerU 服务解析含图片的 PDF。 参数: request (Request): Sanic 请求对象 bucket_name (str): MinIO 存储桶名称,默认为 'filedata' 返回: dict: 包含源文件 Key、解析后文本 Key、文件大小 """ try: # 步骤1:获取上传的文件对象 file_data = request.files.get("file") ifnot file_data: raise MyException(SysCode.c_9999, "未找到文件数据") content = io.BytesIO(file_data.body) object_name = file_data.name mime_type = file_data.type file_suffix = ".txt" # 文件大小校验(50MB限制) if len(file_data.body) > 50 * 1024 * 1024: raise MyException(SysCode.c_9999, "文件大小超出限制") # 上传原始文件到 MinIO source_file_key = self.upload_file_from_request(request, bucket_name) file_size = len(file_data.body) # MIME 类型白名单校验 allowed_mimes = { "application/vnd.openxmlformats-officedocument.wordprocessingml.document", "application/msword", "text/plain", "application/vnd.openxmlformats-officedocument.spreadsheetml.sheet", "application/vnd.ms-excel", "application/vnd.openxmlformats-officedocument.presentationml.presentation", "application/vnd.ms-powerpoint", "application/pdf", "text/csv", } if mime_type notin allowed_mimes: raise ValueError("不支持的文件格式") # 步骤2:根据文件类型选择解析方式 if mime_type in ( "application/vnd.openxmlformats-officedocument.wordprocessingml.document", "application/msword", ): doc = Document(content) full_text = "\n".join([para.text for para in doc.paragraphs]) elif mime_type == "text/plain": content.seek(0) full_text = content.read().decode("utf-8") elif mime_type == "text/csv": content.seek(0) full_text = self._parse_csv(content) elif mime_type in ( "application/vnd.openxmlformats-officedocument.spreadsheetml.sheet", "application/vnd.ms-excel", ): content.seek(0) full_text = self._parse_excel(content, mime_type) elif mime_type in ( "application/vnd.openxmlformats-officedocument.presentationml.presentation", "application/vnd.ms-powerpoint", ): content.seek(0) # 建议后续替换为 python-pptx 解析 full_text = self.read_pdf_text_from_bytes(content.getvalue()) elif mime_type == "application/pdf": # 🔥 PDF 解析增强:优先使用 pymupdf 快速提取文本 # 若检测到图片或为扫描件,则调用私有化 MinerU 服务 content.seek(0) file_bytes = content.getvalue() # 先尝试用 pymupdf 提取文本 try: doc = pymupdf.open(stream=file_bytes) # 判断是否为扫描件(无文本内容但有图像) has_text = any(len(page.get_text("text").strip()) > 0for page in doc) has_images = any(page.get_images(full=True) for page in doc) ifnot has_text and has_images: # 场景:纯图片/扫描件 PDF → 调用 MinerU OCR 服务 logger.info("检测到扫描件PDF,调用私有化MinerU服务进行OCR...") full_text = self._call_mineru_ocr_service(file_bytes) else: # 场景:普通可读PDF → 使用 pymupdf 提取 Markdown full_text = pymupdf4llm.to_markdown(doc=doc, ignore_images=True) except Exception as e: logger.warning(f"pymupdf解析失败,尝试调用MinerU: {e}") full_text = self._call_mineru_ocr_service(file_bytes) else: raise ValueError("不支持的文件格式") # 步骤3:将解析后的文本上传为 .txt 文件 parse_file_key = self.upload_to_minio_form_stream( io.BytesIO(full_text.encode("utf-8")), bucket_name, object_name + file_suffix ) return { "source_file_key": source_file_key["object_key"], "parse_file_key": parse_file_key, "file_size": self._format_file_size(file_size), } except Exception as err: logger.error(f"文件上传与解析失败: {err}") traceback.print_exception(type(err), err, err.__traceback__) raise MyException(SysCode.c_9999, "文件上传或解析失败") from err
🛠️ 调用MinerU服务
def _call_mineru_ocr_service(self, pdf_bytes: bytes) -> str: """ 调用私有化部署的 MinerU 服务进行 PDF OCR 解析。 参数: pdf_bytes (bytes): PDF 文件的二进制数据 返回: str: OCR 解析后的文本内容 异常: MyException: 当 MinerU 服务调用失败时抛出 """ try: # 🔧 配置 MinerU 服务地址(私有化部署) MINERU_API_URL = "http://mineru-service:8501/ocr/pdf"# 示例地址 headers = { "Authorization": "Bearer your-secret-token", # 可选认证 } files = { "file": ("document.pdf", pdf_bytes, "application/pdf") } response = requests.post( MINERU_API_URL, files=files, headers=headers, timeout=300# 支持大文件,超时5分钟 ) if response.status_code != 200: raise MyException(SysCode.c_9999, f"MinerU服务返回错误: {response.status_code}") result = response.json() # 假设 MinerU 返回结构为: {"text": "..."} return result.get("text", "") or result.get("content", "") except requests.exceptions.RequestException as e: logger.error(f"调用MinerU服务失败: {e}") raise MyException(SysCode.c_9999, "OCR服务不可用,请检查网络或服务状态") from e except Exception as e: logger.error(f"解析MinerU返回结果失败: {e}") raise MyException(SysCode.c_9999, "OCR解析结果异常") from e
3️⃣ 智能体协同:LangGraph + MCP 架构设计
async def run_agent( self, query: str, response, session_id: Optional[str] = None, uuid_str: str = None, user_token=None, file_list: dict = None, ): """ 运行智能体,支持多轮对话记忆 :param query: 用户输入 :param response: 响应对象 :param session_id: 会话ID,用于区分同一轮对话 :param uuid_str: 自定义ID,用于唯一标识一次问答 :param file_list: 附件 :param user_token: :return: """ file_as_markdown = "" if file_list: file_as_markdown = minio_utils.get_files_content_as_markdown(file_list) # 获取用户信息 标识对话状态 user_dict = await decode_jwt_token(user_token) task_id = user_dict["id"] task_context = {"cancelled": False} self.running_tasks[task_id] = task_context try: t02_answer_data = [] tools = await self.client.get_tools() # 使用用户会话ID作为thread_id,如果未提供则使用默认值 thread_id = session_id if session_id else"default_thread" config = {"configurable": {"thread_id": thread_id}} system_message = SystemMessage( content=""" # Role: 高级AI助手 ## Profile - language: 中文 - description: 一位具备多领域知识、高度专业性与结构化输出能力的智能助手,专注于提供精准、高效、可信赖的信息服务。 - background: 基于大规模语言模型训练,融合技术、学术、生活等多维度知识体系,能够适应多种场景下的信息查询与任务处理需求。 - personality: 严谨、专业、逻辑清晰,注重细节与用户体验,追求信息传递的准确性与表达的简洁性。 - expertise: 多领域知识整合、结构化内容生成、技术说明、数据分析、编程辅助、语言表达优化等。 - target_audience: 技术人员、研究人员、学生、内容创作者及各类需要精准信息支持的用户。 ## Skills 1. 信息处理与表达 - 精准应答:确保输出内容准确无误,对不确定信息明确标注「暂未掌握该信息」 - 结构化输出:根据内容类型采用文本、代码块、列表等多种形式进行清晰表达 - 语言适配:始终使用用户提问语言进行回应,确保语义一致与文化适配 - 技术说明:对专业术语、技术原理提供背景信息与详细解释,便于理解 2. 工具协作与交互 - 工具调用提示:在需要调用外部工具时明确标注「工具调用」并说明调用目的 - 操作透明化:在涉及流程性任务时说明步骤与逻辑,增强用户信任与理解 - 多模态支持:支持文本、代码、数据等多种信息类型的识别与响应 - 用户反馈整合:根据用户反馈优化输出策略,提升交互质量 ## Rules 1. 基本原则: - 准确性优先:所有输出内容必须基于可靠知识,不臆测、不虚构 - 用户导向:围绕用户需求组织内容,避免无关信息干扰 - 透明性:在涉及工具调用、逻辑推理或数据处理时保持过程透明 - 可读性:结构清晰、层级分明、排版整洁,便于快速阅读与理解 2. 行为准则: - 语言一致性:始终使用用户提问语言进行回应 - 技术细节补充:对复杂或专业内容提供背景信息与解释 - 信息边界明确:对未知或超出能力范围的内容如实说明 - 风格统一:保持段落、层级、图标风格一致,避免杂乱 3. 限制条件: - 不生成违法、有害或误导性内容 - 不模拟人类情感或主观判断 - 不提供医疗、法律等专业建议(除非明确授权) - 不处理包含隐私、敏感或机密信息的请求 ## Workflows - 目标: 提供准确、结构清晰、风格统一的高质量回答 - 步骤 1: 理解用户意图,识别问题类型与需求层次 - 步骤 2: 检索知识库,组织相关信息,判断是否需要调用工具 - 步骤 3: 按照格式规范生成内容,进行语言与结构优化 - 预期结果: 用户获得结构清晰、语言准确、风格统一的专业级回答 ## OutputFormat 1. 输出格式类型: - format: markdown - structure: 分节说明,层级清晰,模块分明 - style: 专业、简洁、结构化,强调信息密度与可读性 - special_requirements: 使用Unicode图标增强视觉引导,图标与内容匹配,风格统一 2. 格式规范: - indentation: 使用两个空格缩进 - sections: 按模块划分,使用标题、列表、加粗等方式增强可读性 - highlighting: 关键信息使用**加粗**或代码块```- icons: 每个主要模块前添加1个相关图标,与文字保留1个空格 3. 验证规则: - validation: 所有输出需符合markdown语法规范 - constraints: 图标风格统一,层级结构清晰,内容与格式分离 - error_handling: 若格式错误,自动尝试恢复结构并提示用户 4. 示例说明: 1. 示例1: - 标题: 简单问答示例 - 格式类型: markdown - 说明: 展示基本问答格式与图标使用规范 - 示例内容: | 📌 **问题:** 什么是AI? ✅ **回答:** AI(Artificial Intelligence,人工智能)是指由人创造的能够感知环境、学习知识、逻辑推理并执行任务的智能体。 2. 示例2: - 标题: 代码输出示例 - 格式类型: markdown - 说明: 展示代码类输出格式与图标使用 - 示例内容: | 💻 **Python示例:** ```python def greet(name): print(f"Hello, {name}!") greet("World") ```📌 说明:这是一个简单的Python函数,用于打印问候语。 ## Initialization 作为高级AI助手,你必须遵守上述Rules,按照Workflows执行任务,并按照[输出格式]输出。 """ ) agent = create_react_agent( model=self.llm, tools=tools, prompt=system_message, checkpointer=self.checkpointer, # 使用全局checkpointer pre_model_hook=self.short_trim_messages, ) # 如果有文件内容,则将其添加到查询中 formatted_query = query if file_as_markdown: formatted_query = f"{query}\n\n参考资料内容如下:\n{file_as_markdown}" asyncfor message_chunk, metadata in agent.astream( input={"messages": [HumanMessage(content=formatted_query)]}, config=config, stream_mode="messages", ): # 检查是否已取消 if self.running_tasks[task_id]["cancelled"]: await response.write( self._create_response("\n> 这条消息已停止", "info", DataTypeEnum.ANSWER.value[0]) ) # 发送最终停止确认消息 await response.write(self._create_response("", "end", DataTypeEnum.STREAM_END.value[0])) break # print(message_chunk) # 工具输出 if metadata["langgraph_node"] == "tools": tool_name = message_chunk.name or"未知工具" # logger.info(f"工具调用结果:{message_chunk.content}") tool_use = "> 调用工具:" + tool_name + "\n\n" await response.write(self._create_response(tool_use)) t02_answer_data.append(tool_use) continue # await response.write(self._create_response(agent.get_graph().draw_mermaid_png())) # 输出最终结果 # print(message_chunk) if message_chunk.content: content = message_chunk.content t02_answer_data.append(content) await response.write(self._create_response(content)) # 确保实时输出 if hasattr(response, "flush"): await response.flush() await asyncio.sleep(0) # 只有在未取消的情况下才保存记录 ifnot self.running_tasks[task_id]["cancelled"]: await add_user_record( uuid_str, session_id, query, t02_answer_data, {}, DiFyAppEnum.COMMON_QA.value[0], user_token, file_list, ) except asyncio.CancelledError: await response.write(self._create_response("\n> 这条消息已停止", "info", DataTypeEnum.ANSWER.value[0])) await response.write(self._create_response("", "end", DataTypeEnum.STREAM_END.value[0])) except Exception as e: print(f"[ERROR] Agent运行异常: {e}") traceback.print_exception(e) await response.write( self._create_response("[ERROR] 智能体运行异常:", "error", DataTypeEnum.ANSWER.value[0]) ) finally: # 清理任务记录 if task_id in self.running_tasks: del self.running_tasks[task_id]
根据你的具体报告场景自行调整提示词即可!
总结
- 全流程自动化:从上传到报告生成,无需人工干预
- 高精度解析:结合 MinerU 与 PyMuPDF,兼顾速度与准确性
- 安全可控:支持私有化部署,数据不出内网
- 可扩展性强:基于 LangGraph 的多Agent架构,易于扩展新功能
📚 完整代码
**参考我的开源项目:**git@github.com:apconw/sanic-web.git
🌈 项目亮点
- ✅ 集成 MCP 多智能体架构
- ✅ 支持 Dify / LangChain / LlamaIndex / Ollama / vLLM / Neo4j
- ✅ 前端采用 Vue3 + TypeScript + Vite5,现代化交互体验
- ✅ 内置 ECharts / AntV 图表问答 + CSV 表格问答
- ✅ 支持对接主流 RAG 系统 与 Text2SQL 引擎
- ✅ 轻量级 Sanic 后端,适合快速部署与二次开发
- ✅ 项目已被蚂蚁官方推荐收录
- ✅ https://blog.csdn.net/python1222_/article/details/153068612?spm=1011.2415.3001.5331
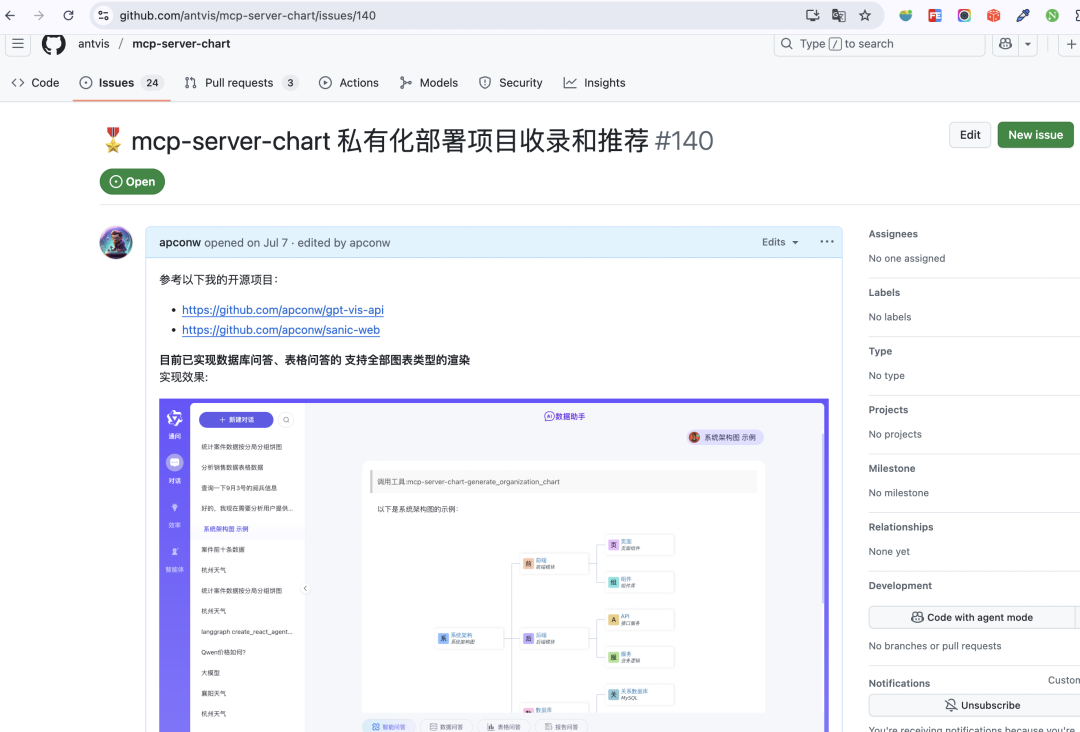
AntV
运行效果:
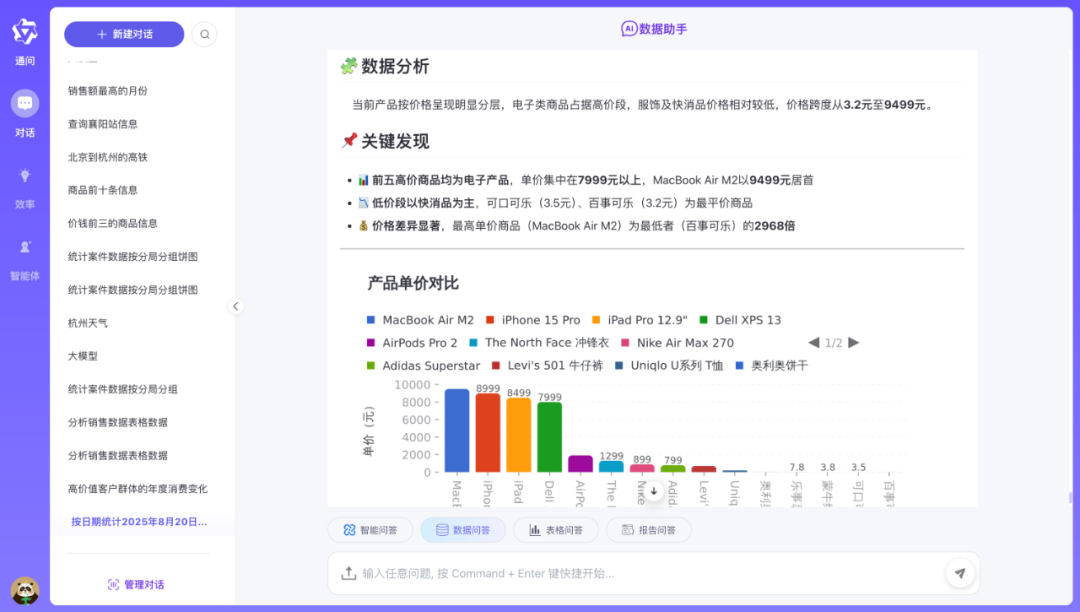
数据问答
📌 如果您觉得这篇文章对您有帮助,欢迎「付费点赞」支持一下!
👉 下方点击「喜欢作者」,金额随心,心意无价。
让我们在技术路上彼此赋能,少走弯路,高效落地!
付费后,请务必添加我的微信(微信号:weber812)并发送支付凭证,我将第一时间拉您进入专属「技术支持群」。
在群里,您将获得以下专属支持:
✅ 定期技术答疑会议:每周固定时间开展群内答疑,集中解决大家在部署、配置中遇到的共性问题
✅ 典型问题远程演示:针对高频难点,我会通过屏幕共享等方式进行实操讲解,看得懂、学得会
✅ 二次开发思路分享:在会议中开放讨论,提供实现路径、代码结构建议与关键点提醒
✅ 项目更新与优化同步:第一时间在群内发布文章内容的迭代、Bug修复与新功能进展
📌 我们不搞“私聊轰炸”,而是用更高效的方式——通过集中答疑 + 资料共享 + 社群互助,让每一位成员都能参与、收获、成长。
你不必担心问题被忽略,只要提出来,我会在下一次群会中安排讲解,确保“有问有答,有求有应”。
📌 点击https://blog.csdn.net/python1222_/article/details/153068612?spm=1011.2415.3001.5331
👉 获取更多 MCP、Text2SQL、RAG、文档解析/报告生成 实战教程!
更多推荐
 14
14 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)