
2025大模型开发面试全攻略:LangChain+LlamaIndex从入门到精通
LangChain和LlamaIndex是构建大语言模型应用的核心框架。本文详细介绍了LangChain的六大核心概念(Models、Prompts、Indexes、Memory、Chains、Agents)和LCEL构建链的优势,深入解析了RAG检索增强生成的实现流程,以及Agent的ReAct执行框架。同时对比了LlamaIndex作为数据层专家与LangChain作为通用框架的区别,并提供了
简介
LangChain和LlamaIndex是构建大语言模型应用的核心框架。本文详细介绍了LangChain的六大核心概念(Models、Prompts、Indexes、Memory、Chains、Agents)和LCEL构建链的优势,深入解析了RAG检索增强生成的实现流程,以及Agent的ReAct执行框架。同时对比了LlamaIndex作为数据层专家与LangChain作为通用框架的区别,并提供了文档切分策略、RAG评估优化等实用技术,帮助开发者构建高效、准确的大模型应用。
面试资料较长,建议点赞收藏,以免遗失。如果对你有所帮助,记得点亮小红心告诉身边有需要的朋友。

1. 什么是LangChain?它的核心设计理念是什么?
答案:
LangChain是一个用于开发由大语言模型驱动的应用程序的框架。它的核心设计理念是通过“可组合性”将多个模块链接在一起,构建复杂而强大的应用。
核心价值:它简化了与大模型交互的流程,并提供了与外部数据源、工具(API、函数)和内存集成的标准化接口。
类比:就像React用于构建用户界面一样,LangChain是用于构建大模型应用界面的工具链。
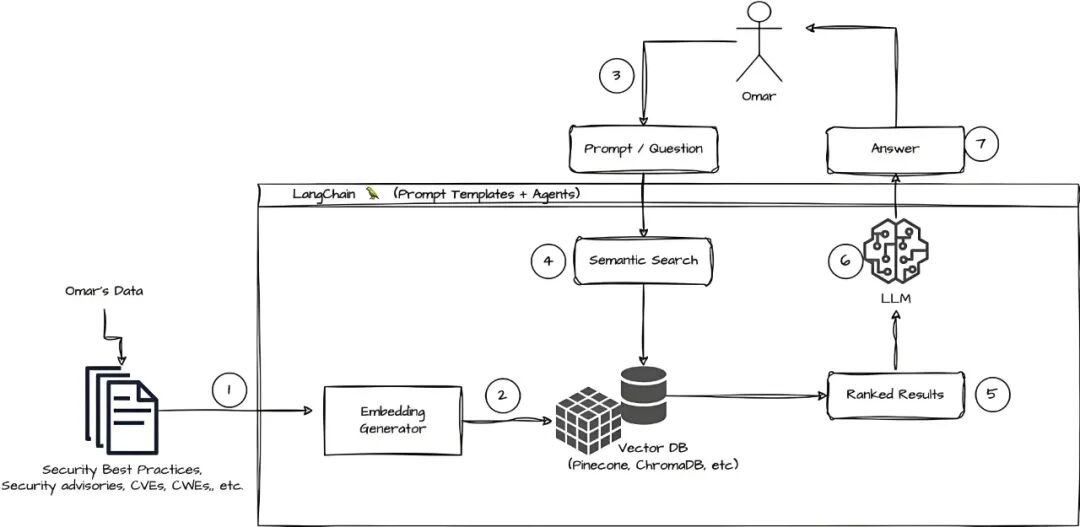
▲LangChain如何作为连接LLM与外部世界(数据、工具)的桥梁和协调中心
2. 请解释LangChain中的6个核心概念:Models, Prompts, Indexes, Memory, Chains, Agents。
答案:
-
Models (模型): 与各种大语言模型交互的抽象层,如ChatGPT、LLaMA等。提供了
LLM(文本进-文本出)和ChatModels(消息进-消息出)两种接口。 -
Prompts (提示): 管理、优化和模板化提示词的模块。包括
PromptTemplate、FewShotPromptTemplate等,允许动态注入上下文和用户输入。 -
Indexes (索引): 用于处理外部数据的工具,主要用于文档的检索。常与
Retrieval模块结合,构成RAG应用的核心。 -
Memory (记忆): 在链或代理的多次调用之间持久化状态(如对话历史)。有
ConversationBufferMemory、ConversationSummaryMemory等多种形式。 -
Chains (链): 核心思想。将多个组件(或多个LLM调用)按预定顺序链接起来,完成一个特定任务。
LCEL (LangChain Expression Language)是构建链的声明式方式。 -
Agents (代理): 更高级的“链”。由LLM作为大脑,动态决定执行一系列
Tools(工具)的步骤和顺序,以完成用户复杂的请求(如“今天天气如何?然后用英文总结一下”)。
3. 什么是LCEL?它有什么优势?请写一个简单的例子。
答案:
LCEL(LangChain Expression Language)是一种声明式的、可组合的语法,用于轻松地构建和部署链。
-
优势:
统一接口: 所有LCEL对象都实现了
Runnable接口,具有统一的invoke,batch,stream,astream方法。自动流输出: 无需额外代码即可实现 token 的流式传输。
强大的并行: 使用
batch可以并行处理多个输入。可靠性: 内置故障重试、回退机制。
示例:
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
from langchain_core.output_parsers import StrOutputParser
# 使用 LCEL 声明一个链:Prompt -> Model -> OutputParser
chain = (
ChatPromptTemplate.from_messages([("system", "你是一个助手"), ("user", "{input}")])
| ChatOpenAI(model="gpt-3.5-turbo")
| StrOutputParser()
)
# 调用链
result = chain.invoke({"input": "你好吗?"})
print(result)
更多的大模型 AI 学习和面试资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
4. 请详细解释Agent的执行流程(使用ReAct框架举例)。
答案:
Agent的执行是一个循环过程,其核心是 “思考 -> 行动 -> 观察”(ReAct框架)。
用户输入: 用户提出一个复杂问题,例如“What was the high temperature in SF yesterday in Fahrenheit?”。
Agent初始化: 将问题、可用工具列表和ReAct指令模板组合成初始提示,发送给LLM。
循环开始:
Step 1: Think - LLM根据当前信息思考下一步该做什么。它会输出一个Thought:,例如“I need to find the weather for yesterday in SF.”
Step 2: Act - LLM决定使用哪个工具(Action)以及输入是什么(Action Input)。例如Action: weather_search, Action Input: San Francisco, yesterday。
工具执行: LangChain调用指定的weather_search工具,并获取结果(Observation:),例如“High: 65°F, Low: 52°F”。
信息整合: 将Thought, Action, Observation加入到新的提示上下文中,再次发送给LLM。
循环判断: LLM根据现有信息判断是否已经得到最终答案。如果已经得到,则输出Final Answer: 65°F;如果还需要更多信息,则回到Step 1继续循环。
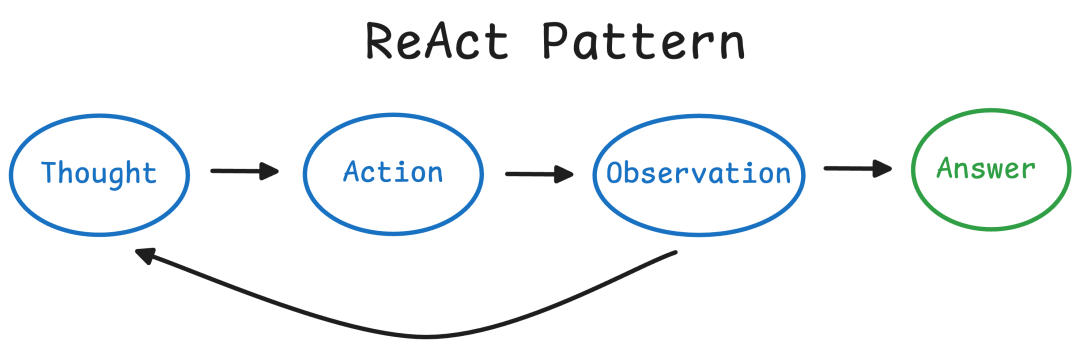
▲ReAct工作流程
5. 什么是RAG?如何在LangChain中实现一个基本的RAG流程?
答案:
****RAG (Retrieval-Augmented Generation): 检索增强生成。通过在生成答案前先从外部知识库中检索相关信息,并将其作为上下文提供给LLM,从而让LLM生成更准确、更符合事实的答案,并减少幻觉。
-
在LangChain中的实现步骤:
加载文档 (Document Loading): 使用
TextLoader,WebBaseLoader等加载源文档。文档切分 (Splitting): 使用
RecursiveCharacterTextSplitter将长文档切分为小的、有重叠的块(Chunks)。向量化嵌入 (Embedding): 使用
OpenAIEmbeddings等模型将文本块转换为向量(Vector Embeddings)。存储索引 (Indexing): 将向量存储在向量数据库(VectorStore)中,如Chroma, Pinecone,并创建索引。
检索 (Retrieval): 用户提问时,将问题也向量化,并从向量库中检索出最相关的
k个文本块。生成 (Generation): 将检索到的文本块作为上下文,与原始问题组合成一个增强的提示(Prompt),发送给LLM生成最终答案。
代码示例:
from langchain_community.document_loaders import WebBaseLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_openai import OpenAIEmbeddings, ChatOpenAI
from langchain_chroma import Chroma
from langchain_core.prompts import ChatPromptTemplate
from langchain.chains import create_retrieval_chain
# 1. 加载 & 2. 切分
loader = WebBaseLoader("https://example.com/article")
docs = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
splits = text_splitter.split_documents(docs)
# 3. 嵌入 & 4. 存储
embeddings = OpenAIEmbeddings()
vectorstore = Chroma.from_documents(documents=splits, embedding=embeddings)
retriever = vectorstore.as_retriever()
# 5. & 6. 组成RAG链
llm = ChatOpenAI(model="gpt-3.5-turbo")
prompt = ChatPromptTemplate.from_template(
"""请根据以下上下文回答問題:
{context}
问题:{input}"""
)
rag_chain = create_retrieval_chain(retriever, llm, prompt)
result = rag_chain.invoke({"input": "文章的主要观点是什么?"})
6. LlamaIndex的核心价值是什么?它与LangChain的主要区别在哪?
答案:
核心价值: LlamaIndex是专门为LLM应用的数据层而设计的框架。它擅长高效地将私有或领域的特定数据与LLM连接起来,是构建RAG应用的专家和利器。它的口号是“为你的数据提供LLM接口”。
主要区别:
| 特性 | LlamaIndex | LangChain |
|---|---|---|
| 焦点 | 数据连接与检索 (RAG专家) | 应用编排与代理 (通用型框架) |
| 核心功能 | 数据索引、高级查询、结构化数据提取 | 链、代理、工具、内存管理 |
| 设计哲学 | 提供强大、开箱即用的数据管道 | 提供高度灵活、可组合的底层组件 |
| 关系 | 可以作为LangChain的一个组件(LlamaIndexRetriever) |
包含并集成多种数据检索方式 |
简单说:如果你想快速、深度地构建一个以数据检索为核心的RAG应用,LlamaIndex更强大。如果你需要构建一个包含多种步骤(如调用API、逻辑判断、记忆)的复杂代理,LangChain更合适。 两者经常结合使用。
7. 解释LlamaIndex中的核心组件:Nodes, Indexes, Engines。
答案:
Nodes: 是Document对象的基本构建块。一个Node包含一段文本及其元数据。文档在被索引前会被解析和切分为多个Nodes。
Indexes: 是核心数据结构,用于组织Nodes以便LLM高效查询。最常见的索引是向量存储索引 (Vector Store Index)。
Engines: 为查询索引提供接口。不同类型的索引有不同的引擎。例如:
Query Engine: 是查询索引的高级抽象,接受自然语言查询并返回响应。
Chat Engine: 支持多轮、有状态的对话,内置了聊天历史管理。
8. LlamaIndex有哪些高级查询/检索模式?
答案:
除了简单的“问-答”检索,LlamaIndex提供了多种强大模式:
子查询 (Sub-Queries): 将一个复杂问题分解为多个子问题,逐一查询后再综合答案。
多步查询 (Multi-Step Queries): 类似于子查询,但步骤间可以传递和迭代信息。
假设查询 (Hypothetical Queries): 给定一个查询,让LLM生成假设性的文档/答案,然后用这些假设文档去优化真正的检索。(HyDE)
基于时间的查询: 对具有时间戳的文档进行检索,优先返回最新的信息。
结构化数据提取: 从非结构化文本中提取出结构化的信息(如JSON格式)。
9. 在RAG中,文档切分(Chunking)为什么重要?有哪些策略?
答案:
重要性:
LLM有上下文窗口限制,必须将长文档切块。
切分的大小和质量直接影响检索精度。块太大,会包含无关信息;块太小,可能会丢失关键上下文。
合理的重叠(Overlap)可以避免句子或段落被割裂,保持语义完整性。
-
策略:
固定大小分块: 最简单,但可能割裂语义。
递归分块: 按字符递归地尝试不同分隔符(如
\n\n,\n, ),直到达到理想块大小。这是最常用的策略。语义分块: 使用嵌入模型计算句子相似度,在语义变化处进行切分。(更高级但更复杂)
专用分块: 对于代码(按函数/类)、Markdown(按标题)等特定格式有专用分块器。
10. 如何评估和提升RAG应用的效果?
答案:
评估指标:
检索精度: 检索到的上下文是否与问题相关?(Hit Rate, MRR@k, NDCG@k)
生成质量: 答案是否准确、相关、流畅?(可以通过LLM-as-a-judge或人工评估)
真实性: 答案是否减少了幻觉?
提升策略:
优化检索:
调整分块大小和重叠。
尝试不同的嵌入模型(如text-embedding-3-large)。
使用重排序(Re-Ranker)模型对检索结果进行精排,提升Top结果的准确性。
使用混合搜索(Hybrid Search),结合关键词(稀疏向量)和语义(稠密向量)检索。
优化生成:
优化提示工程,改进上下文的使用方式。
让模型在无法从上下文中找到答案时回答“我不知道”。
优化索引:
确保源数据质量高、干净。
为文档添加高质量的元数据(如标题、日期),便于元数据过滤查询。
11. 什么是ReAct框架?如何在LangChain中实现一个自定义Tool?
答案:
ReAct框架: Reason+ Act。它指导LLM在解决问题时进行推理(生成思考轨迹)并行动(调用工具)。详见第4题。
实现自定义Tool:
需要定义一个继承BaseTool的类,并实现_run同步方法和/或_arun异步方法。
from langchain.tools import BaseTool
from typing import Optional
class CustomCalculatorTool(BaseTool):
name = "calculator"
description = "Useful for when you need to calculate a math problem"
def _run(self, query: str) -> str:
"""同步执行工具的方法"""
try:
# 这里应该是安全的计算逻辑,例如使用eval不安全,此处仅为示例
return str(eval(query))
except:
return"计算错误"
async def _arun(self, query: str) -> str:
"""异步执行工具的方法(可选)"""
raise NotImplementedError("此工具不支持异步调用")
# 在Agent中初始化并使用
tools = [CustomCalculatorTool()]
agent = initialize_agent(tools, llm, agent="react-docstore", verbose=True)
agent.run("What is 15 raised to the power of 2?")
更多的大模型 AI 学习和面试资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
AI大模型学习和面试资源
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓
更多推荐

 14
14 0
0- 0



 已为社区贡献89条内容
已为社区贡献89条内容

所有评论(0)