
零代码到商用落地!DeepSeek-V3+Dify实战:30分钟搭企业级AI Agent,成本低至0.03元/千tokens
摘要 本文介绍了基于DeepSeek-V3大模型和Dify框架快速搭建企业级AI Agent的完整方案。文章从技术选型、模型集成、框架部署、商用场景开发到运维监控,提供了全流程指导。该方案具有低代码开发(开发门槛降低60%)、高性价比(成本低至0.03元/千tokens)和商用合规等特点,适用于智能客服、数据分析和内容创作等场景。通过流式响应、上下文管理等高级功能优化,以及缓存策略、异步处理等性能
注:此文章内容均节选自充电了么创始人,CEO兼CTO陈敬雷老师的新书《GPT多模态大模型与AI Agent智能体》(跟我一起学人工智能)【陈敬雷编著】【清华大学出版社】
清华《GPT多模态大模型与AI Agent智能体》书籍配套视频课程【陈敬雷】
文章目录
GPT多模态大模型与AI Agent智能体系列二百一十四
零代码到商用落地!DeepSeek-V3+Dify实战:30分钟搭企业级AI Agent,成本低至0.03元/千tokens
在AI大模型商用化加速的背景下,企业搭建专属AI Agent的需求日益迫切。本文围绕“DeepSeek-V3大模型+Dify框架”这一主流技术组合,从技术选型、部署实战到商用优化,提供全流程落地指南,帮助开发者快速实现企业级AI Agent的搭建与上线,同时兼顾安全合规、成本控制与运维保障,为不同行业的商用场景提供可复用的解决方案。
一、技术选型与前期准备:筑牢商用基础
搭建商用AI Agent的核心是选对技术栈与做好前置准备,这一步直接决定后续开发效率与商用稳定性。
1.1 核心组件:选对“引擎”与“工具台”
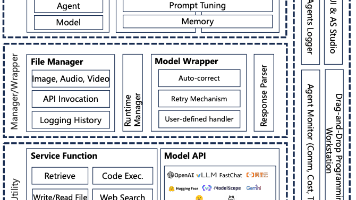
DeepSeek-V3作为百亿参数级主流大模型,核心优势在于强逻辑推理与多轮对话能力,其API支持流式输出(适配实时交互场景)与动态上下文管理,能满足企业级复杂需求;而Dify框架则是低代码开发“利器”,集成工具调用、知识库管理、可视化工作流设计等功能,可将开发门槛降低60%以上,二者结合实现“强大模型能力+高效开发效率”的双重优势。
1.2 硬软配置:明确最低与推荐标准
商用部署对环境要求高于个人开发,需满足稳定性与性能双重需求:
- 硬件配置:最低4核16G内存,推荐搭载NVIDIA A10/T4 GPU(加速模型推理,降低响应延迟);
- 软件环境:操作系统选择Ubuntu 22.04 LTS(兼容性强、长期支持),搭配Python 3.10(避免依赖版本冲突)与Docker 24.0(实现环境隔离与快速部署);
- 依赖管理:用conda创建独立虚拟环境,核心库需固定版本,如transformers4.35.0(确保模型调用兼容性)、fastapi0.104.0(保障API服务稳定)。
1.3 商用许可:合规是前提
企业需通过DeepSeek官方渠道申请API密钥,提交材料包括企业营业执照与具体使用场景说明(如智能客服、数据分析等)。商用版提供99.9% SLA保障(满足企业级可用性需求),支持QPS 50+并发请求,计费方式为按实际调用量付费,约0.03元/千tokens,成本可控性强。
二、DeepSeek-V3模型集成:从基础调用到高级优化
模型集成是AI Agent的“核心大脑”搭建环节,需实现基础调用、功能增强与安全保障的三层目标。
2.1 基础API调用:3步实现对话功能
通过简单代码即可实现DeepSeek-V3的对话能力,核心是配置请求参数与解析响应结果:
import requests
def call_deepseek(prompt, api_key):
# 1. 配置API地址与请求头(携带密钥鉴权)
url = "https://api.deepseek.com/v1/chat/completions"
headers = {"Authorization": f"Bearer {api_key}", "Content-Type": "application/json"}
# 2. 定义请求参数(模型选择、对话内容、生成策略)
data = {
"model": "deepseek-v3",
"messages": [{"role": "user", "content": prompt}], # 对话历史格式
"temperature": 0.7, # 0.7为平衡创造性与准确性的常用值
"max_tokens": 2048 # 控制单次生成内容长度
}
# 3. 发送请求并返回结果
response = requests.post(url, headers=headers, json=data)
return response.json()["choices"][0]["message"]["content"]
2.2 高级功能:适配商用场景需求
基础调用无法满足企业级需求,需开发三大高级功能:
- 流式响应:在请求参数中添加
stream=True,实现逐字输出,解决实时交互场景(如客服对话)的“等待空白”问题; - 上下文管理:维护对话历史列表,每次请求携带前5轮对话(平衡上下文完整性与调用成本),避免“失忆”;
- 安全过滤:集成内容安全API,对生成结果进行涉政、暴力、色情等风险检测,杜绝违规内容输出,满足商用合规要求。
三、Dify框架部署:低代码实现Agent全功能
Dify框架是AI Agent的“操作平台”,通过可视化配置即可实现工具集成、工作流设计与性能优化,无需大量编码。
3.1 基础部署:1行命令启动Dify
借助Docker可快速部署Dify环境,避免复杂的依赖配置:
docker run -d --name dify \
-p 8080:80 \ # 映射端口,通过8080访问控制台
-e API_KEY=your_deepseek_key \ # 关联DeepSeek密钥
-v /data/dify:/data \ # 挂载数据卷,持久化存储
difyai/dify:latest # 使用最新稳定版镜像
部署完成后,访问http://服务器IP:8080即可进入Dify控制台,开始Agent开发。
3.2 Agent开发流程:4步搭建完整能力
Dify采用可视化流程,开发者无需代码即可完成Agent功能搭建:
- 工具配置:在控制台创建HTTP工具,定义API端点、请求参数(如header、body格式),实现与外部系统(如工单系统、数据库)的对接;
- 知识库集成:上传PDF/Word等文档,Dify自动将内容转化为向量嵌入,存储于Milvus向量数据库,支持后续“问答式检索”;
- 工作流设计:用拖拽式编辑器构建“意图识别→工具调用→结果润色”的流程,例如“用户咨询订单→调用订单API查询→整理结果为自然语言”;
- 多轮对话:配置对话状态机,定义话题切换规则(如用户提到“退款”时自动切换到退款流程),实现上下文记忆。
3.3 性能优化:提升响应速度与稳定性
商用场景对性能要求高,需从三个维度优化:
- 缓存策略:用Redis缓存高频查询结果(如“常见问题解答”),命中率可提升40%,减少重复模型调用;
- 异步处理:将长耗时操作(如大文档解析、复杂数据分析)通过Celery异步队列执行,避免阻塞主流程;
- 模型蒸馏:用DeepSeek-V3生成高质量合成数据,微调7B参数小模型(如DeepSeek-7B),应对简单查询(如基础咨询),降低大模型调用成本。
四、商用场景功能开发:从技术到业务落地
技术最终需服务于业务,针对三大典型商用场景,需开发专属功能与合规方案。
4.1 典型应用案例:3大场景落地实践
- 智能客服:集成企业工单系统API,实现“用户问题→意图识别→自动分类工单→推荐解决方案”全流程自动化,降低人工客服压力;
- 数据分析:连接SQL数据库,支持用户用自然语言提问(如“查询9月销售额Top3产品”),Agent自动生成SQL语句执行并生成可视化报表;
- 内容创作:配置Markdown生成工具,辅助撰写技术文档(如API手册)、营销文案(如产品介绍),支持自定义格式模板。
4.2 安全合规:满足企业级风险管控
商用场景必须重视数据安全与合规,需落实三大措施:
- 数据脱敏:对用户输入的手机号、身份证号等敏感信息实时掩码处理(如138****1234),避免数据泄露;
- 审计日志:记录所有对话内容、模型调用参数、用户操作行为,满足等保2.0要求,便于事后追溯;
- 访问控制:基于JWT实现多级权限管理,区分普通用户(仅使用功能)、管理员(配置工具/工作流)、超级管理员(修改权限/删除数据),避免越权操作。
五、监控与运维:保障商用稳定运行
AI Agent上线后,需建立完善的监控与运维体系,及时发现并解决故障。
5.1 监控指标:聚焦3类核心指标
通过监控关键指标,提前预警潜在问题,具体指标与告警阈值如下:
| 指标类别 | 监控项 | 告警阈值 | 预警意义 |
|---|---|---|---|
| 性能指标 | API响应时间 | >2s持续5分钟 | 响应延迟过高,影响用户体验 |
| 可用性指标 | 模型调用成功率 | <95% | 模型服务不稳定,需排查API问题 |
| 资源指标 | GPU内存使用率 | >90%持续10分钟 | 资源不足,需扩容或优化任务 |
5.2 故障排查:3类常见问题解决方案
- 502错误:多为网关配置问题,需检查Nginx负载均衡配置,确认后端Dify服务与模型API是否正常运行;
- 模型超时:可能是
max_tokens设置过大(单次生成内容过长),或API套餐QPS不足,需调整参数或升级商用套餐; - 工具调用失败:需验证HTTP工具的请求模板(如参数名、数据格式)与外部API文档是否一致,排查鉴权信息是否过期。
六、成本优化:降本增效的5大策略
商用部署需平衡效果与成本,通过精细化管理实现“低成本高产出”。
6.1 资源分配:分阶段优化成本
- 开发阶段:使用DeepSeek-V3免费额度(每月100万tokens),无需付费即可完成功能测试;
- 生产环境:采用“基础版+按需扩容”模式,闲时(如夜间)将模型降配为7B参数版,高峰时(如白天客服时段)切换回DeepSeek-V3;
- 混合部署:将知识库检索、文档解析等计算密集型任务迁移至CPU节点,GPU仅用于模型推理,减少GPU资源消耗。
6.2 效果评估:用数据指导优化
- AB测试:对比不同
temperature参数(如0.5 vs 0.9)下的用户满意度评分,选择最优生成策略; - ROI分析:计算AI Agent替代人工的比例(如智能客服替代60%人工咨询),对比系统维护成本与人工成本,明确投入产出比;
- 迭代优化:每月分析TOP 10高频问题,补充知识库内容、优化工具调用逻辑,提升Agent解决问题的能力。
七、进阶功能与落地建议:从能用 to 好用
为提升Agent竞争力,可探索多模态扩展与自主进化能力,同时遵循渐进式落地策略。
7.1 进阶功能:拓展Agent能力边界
- 多模态交互:集成Whisper实现语音转文字(ASR),搭配HuggingFace TTS实现文字转语音,支持“语音提问→语音回答”;接入BLIP-2图像理解模型,支持用户上传图片(如产品故障图),Agent自动分析并给出解决方案;
- 自主进化:基于用户反馈数据训练奖励模型,通过强化学习优化回答策略(如用户点赞的回答权重更高);定期用新数据(如企业新政策、产品更新)更新知识库向量索引,保持信息时效性。
7.2 落地建议:降低商用风险
- 渐进式上线:先在内部测试环境验证功能,再开放给少量核心用户试用,收集反馈后迭代优化,最后全量上线;
- 行业适配:金融、医疗等高监管行业,需额外实施数据加密(如传输加密、存储加密)、操作留痕(如每步操作记录IP与时间)等增强措施,满足行业合规要求;
- 持续迭代:AI Agent不是“一劳永逸”的产品,需建立月度迭代机制,根据业务变化(如新增产品、调整政策)更新工具、知识库与工作流,确保长期适配业务需求。
综上,通过“DeepSeek-V3+Dify”组合,企业可快速搭建兼具“强能力、低门槛、高安全、低成本”的商用AI Agent。从前期准备到落地运维,需围绕“业务需求”核心,平衡技术实现与商用价值,才能让AI Agent真正成为企业降本增效的“利器”。
更多技术内容
更多技术内容可参见
清华《GPT多模态大模型与AI Agent智能体》书籍配套视频【陈敬雷】。
更多的技术交流和探讨也欢迎加我个人微信chenjinglei66。
总结
此文章有对应的配套新书教材和视频:
【配套新书教材】
《GPT多模态大模型与AI Agent智能体》(跟我一起学人工智能)【陈敬雷编著】【清华大学出版社】
新书特色:《GPT多模态大模型与AI Agent智能体》(跟我一起学人工智能)是一本2025年清华大学出版社出版的图书,作者是陈敬雷,本书深入探讨了GPT多模态大模型与AI Agent智能体的技术原理及其在企业中的应用落地。
全书共8章,从大模型技术原理切入,逐步深入大模型训练及微调,还介绍了众多国内外主流大模型。LangChain技术、RAG检索增强生成、多模态大模型等均有深入讲解。对AI Agent智能体,从定义、原理到主流框架也都进行了深入讲解。在企业应用落地方面,本书提供了丰富的案例分析,如基于大模型的对话式推荐系统、多模态搜索、NL2SQL数据即席查询、智能客服对话机器人、多模态数字人,以及多模态具身智能等。这些案例不仅展示了大模型技术的实际应用,也为读者提供了宝贵的实践经验。
本书适合对大模型、多模态技术及AI Agent感兴趣的读者阅读,也特别适合作为高等院校本科生和研究生的教材或参考书。书中内容丰富、系统,既有理论知识的深入讲解,也有大量的实践案例和代码示例,能够帮助学生在掌握理论知识的同时,培养实际操作能力和解决问题的能力。通过阅读本书,读者将能够更好地理解大模型技术的前沿发展,并将其应用于实际工作中,推动人工智能技术的进步和创新。
【配套视频】
清华《GPT多模态大模型与AI Agent智能体》书籍配套视频【陈敬雷】
视频特色: 前沿技术深度解析,把握行业脉搏
实战驱动,掌握大模型开发全流程
智能涌现与 AGI 前瞻,抢占技术高地
上一篇:《GPT多模态大模型与AI Agent智能体》系列一》大模型技术原理 - 大模型技术的起源、思想
下一篇:DeepSeek大模型技术系列五》DeepSeek大模型基础设施全解析:支撑万亿参数模型的幕后英雄
更多推荐


 21
21 0
0- 0



 已为社区贡献46条内容
已为社区贡献46条内容

所有评论(0)