
Python实战:网络爬虫项目详解获取图书网站排行榜数据,可视化界面(含源码)
本文介绍了一个Python网络爬虫项目,用于自动抓取某图书网站排行榜数据并保存为CSV文件。项目采用requests库发送请求,BeautifulSoup解析HTML内容,提取书名、作者、出版社、价格等关键信息,并整合到pandas DataFrame中。为规避反爬机制,设置了User-Agent和控制请求频率。项目还实现了Tkinter可视化界面,包含爬取选项、日志显示和进度条功能。核心功能包括
网络爬虫项目详解:获取图书网站排行榜数据(可视化工具)
写在开头
本项目中中所有内容仅供学习交流使用,不用于其他任何目的,严禁用于商业用途和非法用途,否则由此产生的一切后果均与作者无关!
最经典的项目来了(手动狗头),本文将详细介绍如何使用Python爬取某个图书网站的排行榜数据,并将数据保存为CSV文件。
一、项目背景
许多内容平台都有排行榜功能,代表了用户群体对内容的评价。然而,手动复制这些信息不仅耗时耗力,而且效率低下。因此,我们希望通过编程的方式自动化地获取这些数据,便于后续的分析和使用。
该项目旨在通过网络爬虫技术,自动抓取某网站排行榜中的关键信息,包括标题、作者、出版社、出版时间、价格、评分以及详情链接,并将其整理成结构化的CSV文件,方便进一步的数据分析和处理。
二、技术栈
本项目主要采用了以下技术和工具:
- requests:用于发送HTTP请求,获取网页内容。
- BeautifulSoup:强大的HTML/XML解析库,用于从网页中提取所需数据。
- pandas:数据分析和处理库,用于将数据整理成结构化的表格形式并导出为CSV文件。
- time:用于控制请求频率,避免触发目标网站的反爬机制。
- tkinter:Python内置的GUI库,用于创建图形用户界面。
主要的依赖框架即 BeautifulSoup
三、项目实现
关键爬取逻辑
项目的爬取逻辑主要分为以下几个步骤:
-
构造请求URL:目标网站排行榜分为10页展示,每页25条内容,通过改变URL参数
start的值(0, 25, 50…225)来访问不同页面。 -
发送HTTP请求:使用requests库向目标URL发送GET请求,并设置User-Agent模拟浏览器行为。
-
解析HTML内容:利用BeautifulSoup解析返回的HTML内容,通过CSS选择器定位到包含书籍信息的元素。
-
提取数据字段:从HTML元素中提取以下信息:
- 书名:通过查找包含书籍标题的元素
- 作者、出版社、出版时间、价格:从同一段落中提取并分割
- 评分:查找评分相关的元素
- 链接:获取书籍详情页的URL

F12可以清晰的看到书名、链接、作者、以及价格所在的元素属性
-
数据存储:将提取的数据存入pandas DataFrame,并导出为CSV文件。
反爬逻辑
为了防止被目标网站识别为爬虫并封锁IP,在项目中实现了以下反爬措施:
- 设置User-Agent:在HTTP请求头中添加User-Agent字段,模拟真实浏览器访问。
HEADERS = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}
- 控制请求频率:在每次请求之间添加1秒的延时,避免因请求过于频繁而被封禁。
# 间隔等待1秒,防止被反爬
time.sleep(1)
当然也可以适当增加
核心代码示例
以下是项目的核心实现代码:
# 导入爬虫功能
try:
from dbds import fetch_douban_book_data, save_to_csv, analyze_data
SPIDER_AVAILABLE = True
except ImportError as e:
SPIDER_AVAILABLE = False
print(f"导入爬虫模块失败: {e}")
#可视化界面实现
def create_widgets(self):
# 主框架
main_frame = ttk.Frame(self.root, padding="10")
main_frame.grid(row=0, column=0, sticky=(tk.W, tk.E, tk.N, tk.S))
# 配置网格权重
self.root.columnconfigure(0, weight=1)
self.root.rowconfigure(0, weight=1)
main_frame.columnconfigure(1, weight=1)
main_frame.rowconfigure(2, weight=1)
# 标题
title_label = ttk.Label(main_frame, text="XX读书Top250榜单爬取工具",
font=("Arial", 16, "bold"))
title_label.grid(row=0, column=0, columnspan=3, pady=(0, 20))
# 选项框架
options_frame = ttk.LabelFrame(main_frame, text="爬取选项", padding="10")
options_frame.grid(row=1, column=0, columnspan=3, sticky=(tk.W, tk.E), pady=(0, 10))
# 代理选项
self.use_proxy_var = tk.BooleanVar()
proxy_check = ttk.Checkbutton(options_frame, text="使用代理IP",
variable=self.use_proxy_var)
proxy_check.grid(row=0, column=0, sticky=tk.W, padx=(0, 20))
# 数据分析选项
self.analyze_var = tk.BooleanVar()
analyze_check = ttk.Checkbutton(options_frame, text="进行数据分析",
variable=self.analyze_var)
analyze_check.grid(row=0, column=1, sticky=tk.W)
# 按钮框架
button_frame = ttk.Frame(main_frame)
button_frame.grid(row=2, column=0, columnspan=3, pady=(0, 10))
# 开始爬取按钮
self.start_button = ttk.Button(button_frame, text="开始爬取",
command=self.start_crawling)
self.start_button.pack(side=tk.LEFT, padx=(0, 10))
# 停止按钮
self.stop_button = ttk.Button(button_frame, text="停止",
command=self.stop_crawling, state=tk.DISABLED)
self.stop_button.pack(side=tk.LEFT, padx=(0, 10))
# 打开文件夹按钮
self.open_folder_button = ttk.Button(button_frame, text="打开保存目录",
command=self.open_folder)
self.open_folder_button.pack(side=tk.LEFT)
# 日志显示区域
log_frame = ttk.LabelFrame(main_frame, text="运行日志", padding="10")
log_frame.grid(row=3, column=0, columnspan=3, sticky=(tk.W, tk.E, tk.N, tk.S), pady=(0, 10))
log_frame.columnconfigure(0, weight=1)
log_frame.rowconfigure(0, weight=1)
# 滚动文本框
self.log_text = scrolledtext.ScrolledText(log_frame, height=20, state=tk.DISABLED)
self.log_text.grid(row=0, column=0, sticky=(tk.W, tk.E, tk.N, tk.S))
# 进度条
self.progress = ttk.Progressbar(main_frame, mode='indeterminate')
self.progress.grid(row=4, column=0, columnspan=3, sticky=(tk.W, tk.E), pady=(0, 10))
# 状态栏
self.status_var = tk.StringVar()
self.status_var.set("就绪")
status_bar = ttk.Label(main_frame, textvariable=self.status_var, relief=tk.SUNKEN, anchor=tk.W)
status_bar.grid(row=5, column=0, columnspan=3, sticky=(tk.W, tk.E))
def log_message(self, message):
"""在日志区域显示消息"""
self.log_text.config(state=tk.NORMAL)
self.log_text.insert(tk.END, message + "\n")
self.log_text.see(tk.END)
self.log_text.config(state=tk.DISABLED)
self.root.update_idletasks()
# 发送HTTP请求并解析HTML
response = requests.get(url, headers=HEADERS, timeout=10)
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
# 查找所有内容项
content_items = soup.find_all('tr', class_='item')
# 提取信息
for item in content_items:
# 标题和链接
title_tag = item.find('div', class_='pl2').find('a')
title = title_tag.get('title').strip() if title_tag else '未知'
link = title_tag.get('href').strip() if title_tag else ''
# 作者、出版社、出版时间、价格信息
info_tag = item.find('p', class_='pl')
info_text = info_tag.get_text().strip() if info_tag else ''
# 解析详细信息
info_parts = info_text.split('/')
author = info_parts[0].strip() if len(info_parts) > 0 else '未知'
publisher = info_parts[-3].strip() if len(info_parts) > 2 else '未知'
publish_date = info_parts[-2].strip() if len(info_parts) > 1 else '未知'
price = info_parts[-1].strip() if len(info_parts) > 0 else '未知'
# 评分
rating_tag = item.find('span', class_='rating_nums')
rating = rating_tag.get_text().strip() if rating_tag else '暂无评分'
也可以把短评等其他内容增加进爬取内容里
爬取结果展示:
安装模块包&运行脚本:
.\venv\Scripts\pip.exe install requests beautifulsoup4 pandas
.\venv\Scripts\python.exe .\dbds.py
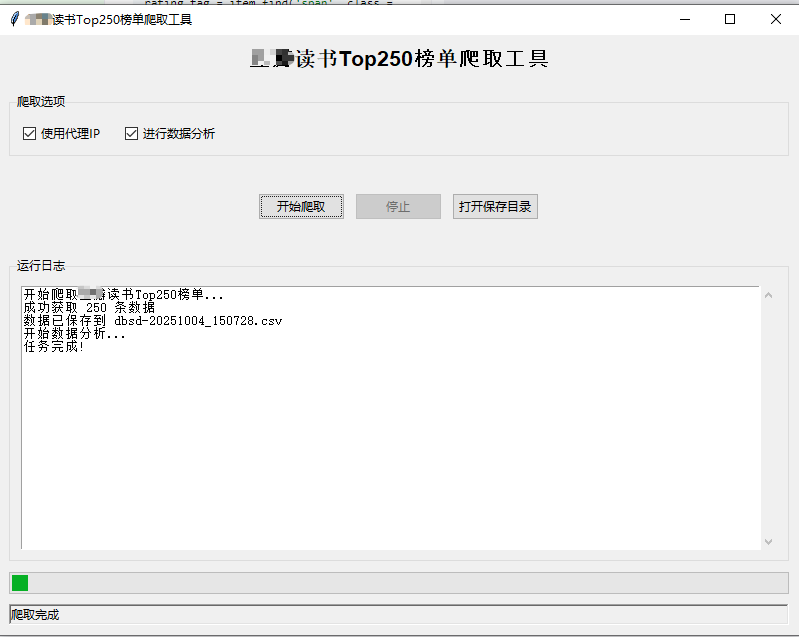


四、总结
为了提高实用性和稳定性,实现了以下扩展功能:
1. 异常处理机制
添加异常处理机制,程序可以更好地应对网络异常、解析错误等问题,提高程序的稳定性。
2. 代理IP支持
支持代理IP池功能,可以进一步降低被目标网站封禁的风险。
3. 图形化界面
使用tkinter创建了图形用户界面,可以通过简单的点击操作来执行爬取任务,提升了用户体验。
4. 数据分析功能
对爬取的数据进行简单的统计分析,如评分分布、出版社排名、作者排名等。
更多推荐
 16
16 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)