- @weixin_44087406
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
创建测试用户和数据库、安装dblink扩展、建立跨库连接、执行远程查询和关闭连接。使用dblink时需注意密码安全、网络延迟和权限管理等问题,确保跨库查询的安全性和稳定性。

本文介绍了一个Python网络爬虫项目,用于自动抓取某图书网站排行榜数据并保存为CSV文件。项目采用requests库发送请求,BeautifulSoup解析HTML内容,提取书名、作者、出版社、价格等关键信息,并整合到pandas DataFrame中。为规避反爬机制,设置了User-Agent和控制请求频率。项目还实现了Tkinter可视化界面,包含爬取选项、日志显示和进度条功能。核心功能包括
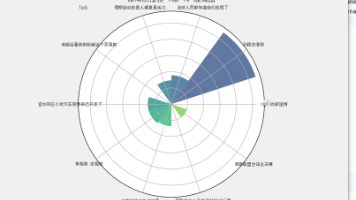
微博热搜数据爬取与可视化分析项目摘要 本项目基于Python技术栈开发了一套微博热搜数据采集与可视化系统,包含数据爬取、存储和可视化三大功能模块。通过requests库调用微博API获取JSON格式热搜数据,使用pandas进行数据处理后存储为CSV文件,并利用matplotlib生成科技感玫瑰图展示热搜热度分布。系统实现了热搜标题、链接地址等关键信息的自动化采集,以及前10名热搜词条的热度对比可
摘要:GaussDB中numeric字段末尾0丢失问题(如100.10显示为100.1)主要与behavior_compat_options参数相关。排查重点包括:1)确认字段为numeric类型;2)检查参数是否包含truncate_numeric_tail_zero或hide_tailing_zero配置。解决方案建议移除这两个参数配置,确保数值精度完整显示。对于JPA框架应用,调整参数后需重