
【人工智能通识专栏】第三十二讲:本地化部署模型
Ollama是一个开源的本地大模型运行工具,可以在本地环境中快速、灵活地部署和管理大语言模型,并提供灵活的定制化选项。上节使用Ollama安装Deepseek模型,在本地命令行窗口就可以使用本地模型,但这种交互体验很差,仿佛回到了DOS年代。在前几章的应用中,我们都依赖于云端服务的DeepSeek模型,不可避免地受到网络带宽、服务器负载的限制,同时也会带来数据隐私与安全的隐忧。这说明我们已经完成d
欢迎关注【人工智能通识】专栏
在前几章的应用中,我们都依赖于云端服务的DeepSeek模型,不可避免地受到网络带宽、服务器负载的限制,同时也会带来数据隐私与安全的隐忧。对于需要高安全性或个性化定制的用户而言,探索本地部署与私有知识库就显得尤为重要。
本章(第11章)围绕构建模型本地化部署与本地知识库构建两大核心技术,介绍Deepseek的本地应用,搭建安全高效的大语言模型系统。
目录
DeepSeek作为开源免费模型,支持下载并部署到本地服务器或计算机,实现离线运行。DeepSeek本地部署在保障数据安全、提高响应速度、加强自主运维和灵活定制扩展方面具有显著优势。
11.1.1 使用Ollama部署本地模型
软硬件需求
DeepSeek提供多种规模模型,计算资源需求呈梯度分布,覆盖从消费级设备到数据中心的部署场景。DeepSeek R1模型本地化部署的硬件需求详见表11-1,在高性能个人计算机上也可以安装和运行小型模型。
|
模型规模 |
小型模型 (7B~14B) |
中型模型 (35B~70B) |
大型模型 (671B) |
|
适用场景 |
个人开发、轻量级问答 |
企业级应用、数据分析 |
超大规模推理计算 |
|
CPU |
Intel i5 |
Xeon 32核 |
服务器集群(HPC) |
|
内存(RAM) |
16GB(最低) 32GB(推荐) |
64GB(最低) 128GB(推荐) |
256GB(单节点) 512GB(分布式) |
|
GPU(推理) |
RTX 3060(12GB) |
RTX 3090(24GB) |
多卡 A100/H100 |
|
GPU(训练) |
可选(需16GB显存) |
A100 40GB(单卡) |
多卡 H100 |
|
存储 |
20GB |
100GB+ |
2TB+(分布式存储) |
|
典型框架 |
Ollama |
vLLM |
vLLM |
DeepSeek本地部署的软件依赖根据部署方式有所差异,基础依赖包括操作系统、Python编程语言、PyTorch深度学习框架、CUDA GPU加速工具。个人用户可以使用Ollama拉取模型,适合快速体验;企业级部署可以使用Docker + OpenWeb UI提供Web服务。
安装Ollama
Ollama是一个开源的本地大模型运行工具,可以在本地环境中快速、灵活地部署和管理大语言模型,并提供灵活的定制化选项。Ollama支持Windows、macOS、Linux多种操作系统以及通过Docker容器运行。本文以Windows系统为例介绍。
1. 访问Ollama官网(https://ollama.com/),选择与操作系统对应的Ollama安装包下载。
2. 以管理员身份运行下载的安装包OllamaSetup.exe,按提示完成安装。
3. 按下`Win+R`打开运行窗口,输入`cmd`打开命令行窗口,输入`ollama -v`测试。如图11-1所示,显示Ollama版本号则说明安装成功。
Ollama没有用户界面,运行后在本地启动了一个内置的Web服务,默认通过通信端口localhost:11434提供本地API服务,用于接收HTTP请求并返回模型响应。如图11-2所示,从浏览器访问`http://localhost:11434/`,将显示“Ollama is running”。
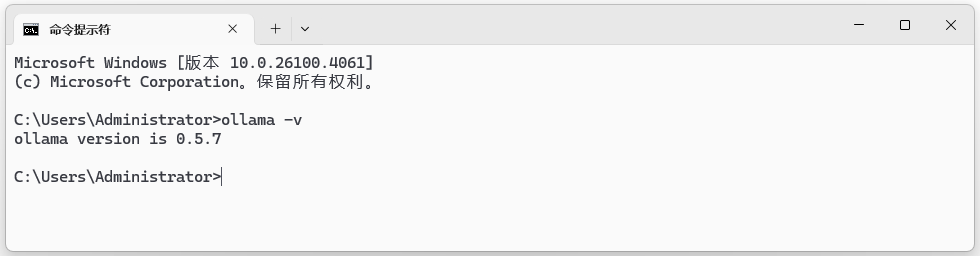
图11-1:检测Ollama安装版本
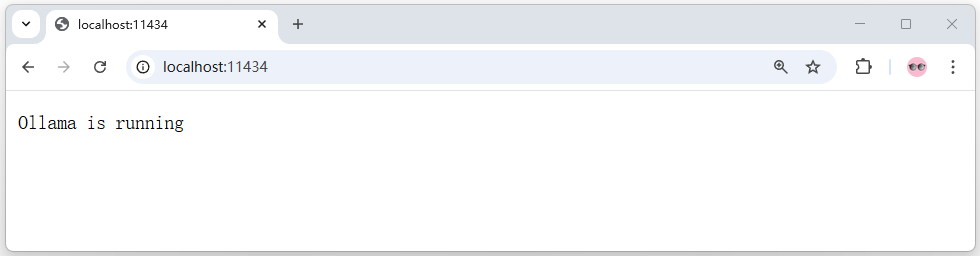
图11-2:测试Ollama通信端口
通过Ollama安装Deepseek模型
1. 访问Ollama官网(https://ollama.com/search),如图11-3所示查找deepseek模型。
2. deepseek-r1提供了不同规模的多个模型。
参数量越大,模型性能就越强,但也需要更多的存储和计算资源。不同版本的deepseek-r1模型的大小和下载命令如表11-2所示。
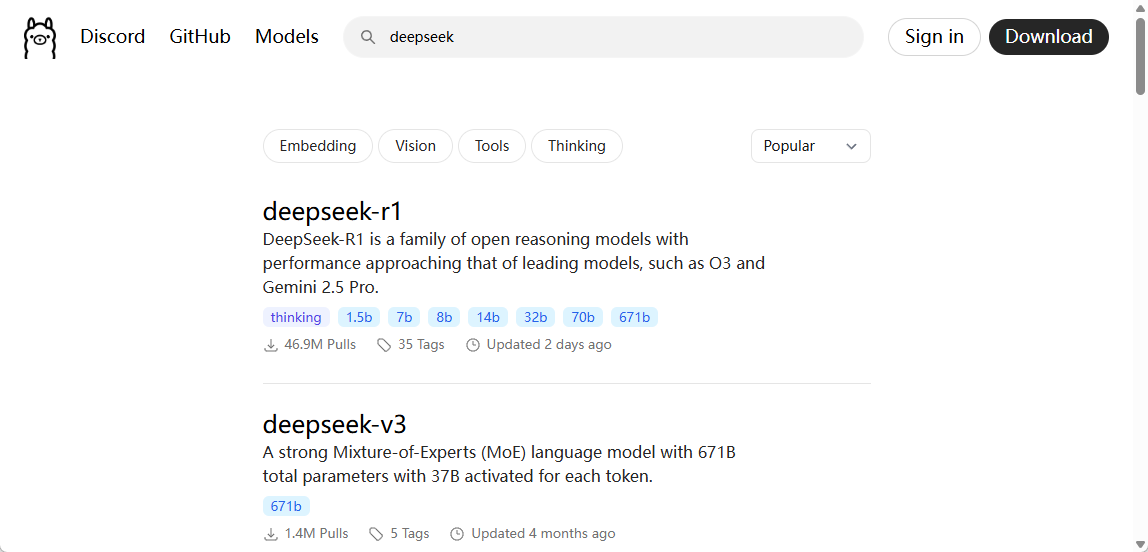
图11-3:在Ollama官网查找deepseek-r1模型
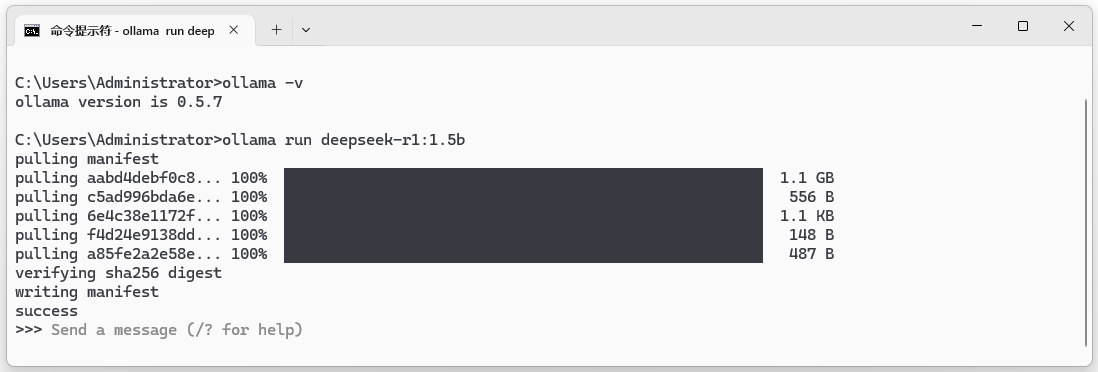
图11-4:从Ollama安装deepseek-r1:1.5模型
|
模型 |
大小 |
下载命令 |
|
deepseek-r1:1.5b |
1.1 GB |
ollama run deepseek-r1:1.5b |
|
deepseek-r1:7b |
4.7 GB |
ollama run deepseek-r1:7b |
|
deepseek-r1:14b |
9.0 GB |
ollama run deepseek-r1:14b |
|
deepseek-r1:32b |
20 GB |
ollama run deepseek-r1:32b |
|
deepseek-r1:671b |
404 GB |
ollama run deepseek-r1:671b |
3. 推荐先用最小规模的1.5b模型跑通deepseek-r1的本地部署过程,再根据自己的硬件配置和需求安装适当的版本。
Ollama运行模型使用`ollama run`命令。在命令行窗口输入`ollama run deepseek-r1:1.5b`,如果本地没有该模型Ollama就会自动下载和安装deepseek-r1:1.5b模型。如图11-4所示,安装完成后显示“success”,说明安装成功。
注意默认安装路径为`C:\Users\%username%\.ollama\models`。如果修改模型的保存路径,可以新建文件夹如“C:\Model”,然后添加系统变量【变量名:OLLAMA_MODELS,变量值:C:\Model】。
使用本地Deepseek模型
1. 在命令行窗口使用`ollama run deepseek-r1:1.5b`命令运行本地deepseek-r1:1.5b模型。如图11-5所示,模型加载后显示`>>>`提示符,就可以输入内容与deepseek-r1模型进行对话。
2. 在提示符后输入`/?`,可以查看快捷键帮助信息。
3. 在提示符后输入问题,模型就能进行回复。这说明我们已经完成deepseek-r1模型的本地安装,正在使用本地部署的deepseek-r1模型了。
4. 在提示符后输入`/bye`,退出模型运行,回到命令行模式。
5. Ollama支持多轮对话,模型可以记住上下文。
通过Ollama可以拉取、运行和管理不同的大语言模型,或大语言模型的不同的版本,更多使用方法请参见Ollama用户手册。
本例部署的deepseek-r1本地模型规模较小,因而推理性能也较差。如果使用高性能服务器部署deepseek-r1:671b“满血版”模型,就能获得与官网相当的性能。
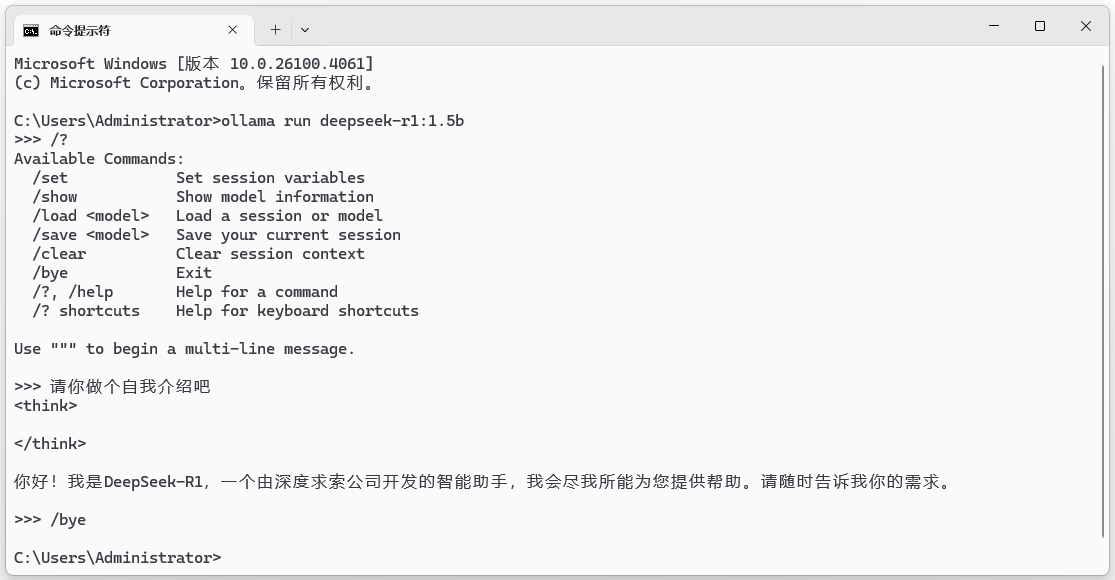
图11-5:从Ollama运行deepseek-r1:1.5模型
11.1.2 基于WebUI搭建本地Web服务
上节使用Ollama安装Deepseek模型,在本地命令行窗口就可以使用本地模型,但这种交互体验很差,仿佛回到了DOS年代。使用Docker + Open WebUI可以实现模型快速部署、环境隔离和跨平台运行,更适合搭建简单的本地Web服务。
安装Docker
Docker是一种虚拟化容器技术,它将应用程序及其所有依赖环境(如 Python 版本、CUDA 驱动等)封装在一个容器中,无需手动配置复杂环境就能保障系统稳定高效地运行。
1. 以Windows11系统为例,检查系统安装环境。
(1)打开任务管理器,选择“性能→CPU→虚拟化”,确认已启用虚拟化。
(2)如果未开启虚拟化,则要开机重启并进入BIOS设置。在BIOS 选择:“Advanced→CPU Configuration→Secure Virtual Machine”,设置为“Enabled”(启用)。
(3)启用Hyper-V虚拟机。如图11-6所示,在“控制面板”中选择“程序”,点击“启用或关闭Windows 功能”,勾选“Hyper-V管理工具”和“Hyper-V 平台”。
(4)如果使用Windows 10或更高版本,建议启用WSL 2后端以提高性能。
在命令行输入`wsl --set-default-version 2`,设置默认的WSL版本为WSL 2。在命令行输入`wsl --update --web-download`,更新安装 wsl。
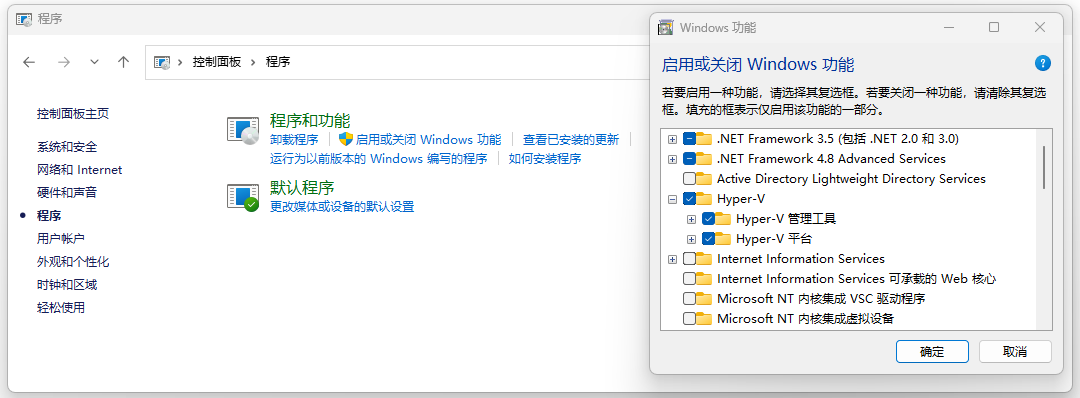
图11-6:启用虚拟机管理程序
2. 安装 Docker Desktop应用程序。
Docker Desktop是Docker官方提供的桌面应用程序,提供了一个方便的工具集,使用户能够快速部署容器化应用程序。
(1)访问Docker官网(https://www.docker.com//),下载Docker Desktop安装程序。
(2)以管理员身份运行下载的安装程序,按照提示完成安装。
(3)安装完成后Docker 会自动启动,通知栏显示图标表示Docker正在运行。
(4)输入`cmd`打开命令行窗口,输入`docker -v`测试,显示docker的版本号则说明安装成功。
3. 配置国内镜像源。
执行命令`docker run hello-world`,可能出现报错如下:“docker: Error response from daemon. (Client. Timeout exceeded while awaiting headers).”。这是Docker守护进程在尝试连接到Docker Hub(registry-1.docker.io)时连接超时,即访问国外镜像源失败。
使用国内的镜像源来解决这个问题。登录Docker官网,选择“Settings→Docker Engine”,将镜像源替换如下。
{
"builder": {
"gc": {
"defaultKeepStorage": "20GB",
"enabled": true
}
},
"experimental": false,
"features": {
"buildkit": true
},
"registry-mirrors": [
"https://docker.m.daocloud.io",
"https://docker.1panel.live",
"https://registry.docker-cn.com",
"https://cr.console.aliyun.com",
"https://mirror.ccs.tencentyun.com"
]
}
安装Open Web UI
Open WebUI是一个功能丰富、用户友好的LLM交互界面,支持多种LLM,支持Web方式访问Ollama API,支持本地检索增强生成(RAG)。
访问Open-WebUI项目的Github仓库,从README文件找到用于Ollama的安装命令。如果仅使用CPU运行Open WebUI,在命令行执行如下docker命令安装。
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
如果使用Nvidia GPU支持运行Open WebUI,则执行如下docker命令安装Open WebUI。
docker run -d -p 3000:8080 --gpus all --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:cuda
使用Open Web UI
1. Open WebUI默认使用3000端口。访问 `http://localhost:3000` 或`http://127.0.0.1:3000`,进入Open-WebUI首页。
2. 注册用户账号。如图11-7所示,Open WebUI上创建的第一个账户具有管理员权限,可以控制用户管理和系统设置。后续的注册用户需要管理员批准才能访问。
3. 登录后进入Open WebUI界面。
如图11-8所示,Open WebUI的用户界面与Deepseek网页版相似,左侧边栏中显示历史对话列表和常用功能,右侧工作区显示当前对话内容和对话输入框。
如图11-9所示,在对话输入框输入问题,就可以与本地部署的Deepseek模型对话了。
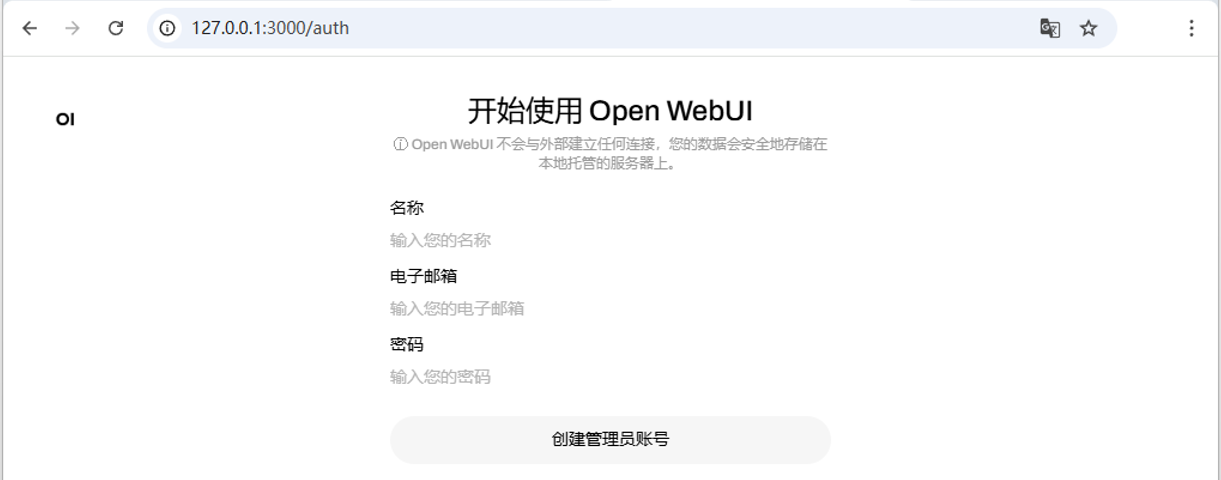
图11-7: Open WebUI创建管理员账号
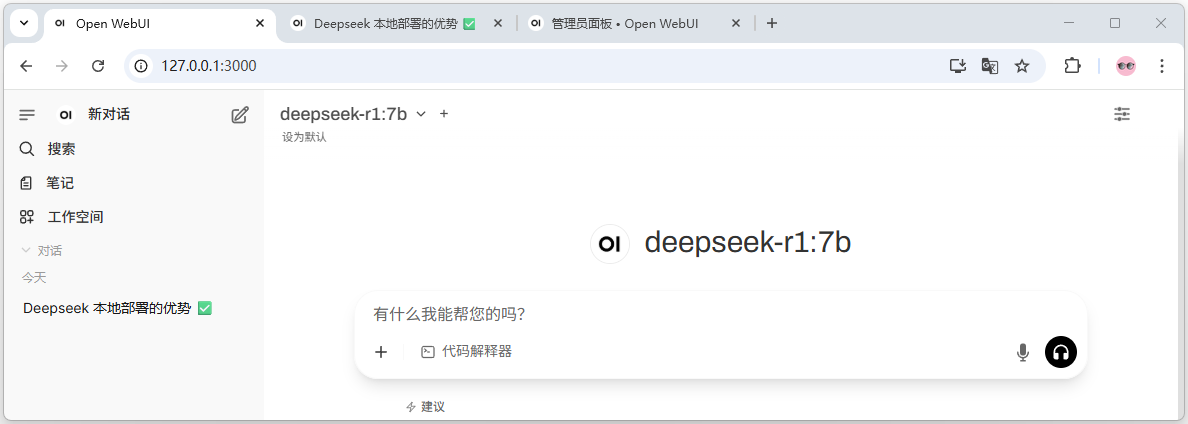
图11-8: Open WebUI的使用界面
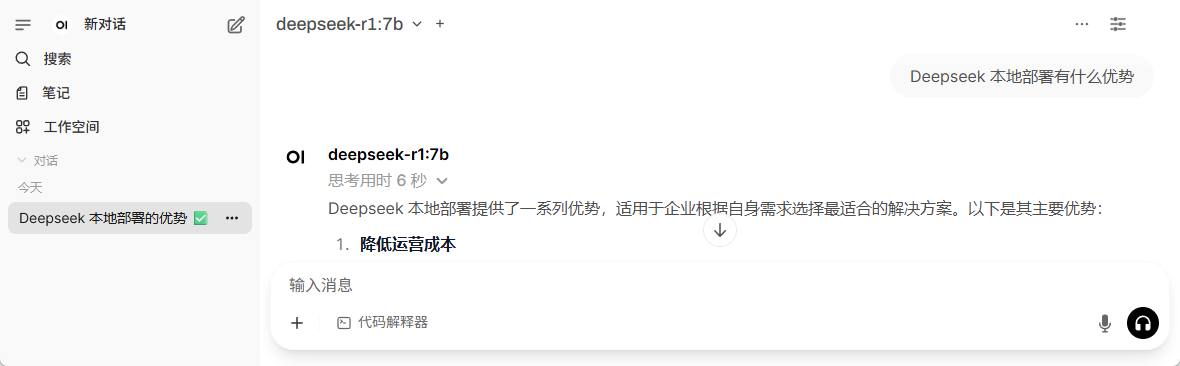
图11-9: Open WebUI使用本地模型对话
11.1.3 通过Python SDK集成本地模型
Ollama Python SDK库提供了丰富的SDK接口,可以帮助开发者更便捷地调用和管理模型,轻松地将本地模型集成到Python应用中。
环境准备
在开始使用Python与Ollama API交互之前,请确保您的开发环境满足以下条件。
1. 安装了Python 3.8或更高版本。
2. 安装了必要的Python库:requests、ollama。
在使用Python SDK之前,要确保Ollama本地服务已经启动。启动本地服务后,Python SDK会与本地服务进行通信,执行模型推理等任务。
模型对话
通过Ollama Python SDK可以向指定的模型发送请求,生成文本或对话。参考例程如下。运行本程序,模型根据输入返回的答案如图11-10所示。
from ollama import chat
from ollama import ChatResponse
response: ChatResponse = chat(
model='deepseek-r1:7b',
messages=[
{
'role': 'user',
'content': '请介绍你是谁',
},
])
print(response['message']['content']) # 打印响应内容
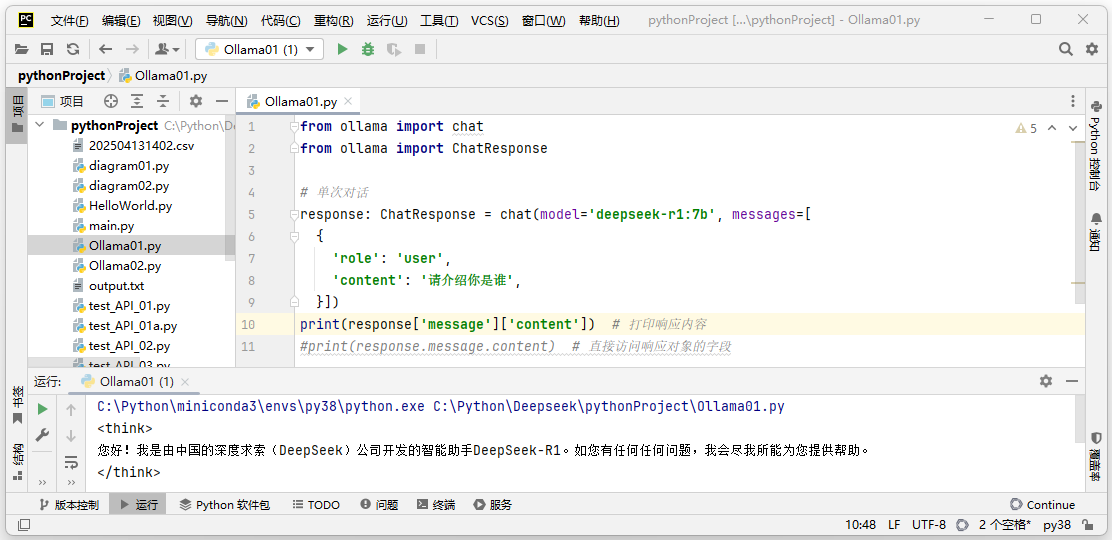
图11-10:Python SDK集成本地Deepseek模型
流式输出
Ollama SDK支持流式响应。在发送请求时设置`stream=True`可以启用流式输出,使函数调用返回一个Python生成器,其中每个部分都是流中的一个对象。参考例程如下。
from ollama import chat
# 流式输出
stream = chat(
model='deepseek-r1:7b',
messages=[{'role': 'user', 'content': '什么是大语言模型?'}],
stream=True, # 流式输出
)
for chunk in stream: # 逐块打印响应内容
print(chunk['message']['content'], end='', flush=True)
自定义客户端
通过创建自定义客户端可以控制请求的设置,如自定义headers或指定本地服务的URL。参考例程如下。
from ollama import Client
client = Client(
host='http://localhost:11434',
headers={'x-some-header': 'some-value'}
)
response = client.chat(
model='deepseek-r1:7b',
messages=[{'role': 'user', 'content': 'Deepseek V3与R1的区别'}])
print(response['message']['content'])
异步客户端
使用AsyncClient类可以异步执行请求,适用于需要并发的场景。
设置`stream=True`可以设置为异步生成器,实现异步处理流式响应。响应将逐部分地异步返回,每部分都可以即时处理。参考例程如下。
import asyncio
from ollama import AsyncClient
# 异步流式响应
async def chat():
message = {'role': 'user', 'content': '请介绍西安电子科技大学'}
async for part in await AsyncClient().chat(model='deepseek-r1:7b', messages =[message], stream=True):
print(part['message']['content'], end='', flush=True)
asyncio.run(chat())
结构化输出
普通输出直接生成自然语言文本,适合阅读但不便于自动化处理。结构化输出可以精确控制模型输出,便于存储、查询和分析。参考例程如下。
from ollama import chat
import json
response = chat(
model='deepseek-r1:7b',
messages=[{
'role': 'user',
'content': '请介绍德国的首都、人口、面积,并以 JSON 格式返回。'
}],
format="json",
options={'temperature': 0})
response_content = response["message"]["content"]
if not response_content:
raise ValueError("Ollama 返回的 JSON 为空")
print(json.loads(response_content))
本程序的输出为JSON格式:{'City': 'Berlin', 'Population': 13.8, 'Area': 875}。
集成到应用框架
本程序基于Ollama创建一个本地运行的智能问答助手。要求实现多轮对话,保存对话历史记录。
import ollama
import textwrap
class DeepSeekAssistant:
def __init__(self, model_name='deepseek-r1:7b'):
self.model = model_name
self.history = []
def ask(self, question, max_width=80):
# 1. 将当前问题添加到历史记录
self.history.append({'role': 'user', 'content': question})
# 2. 调用 Ollama API 生成回答
try: # 错误处理机制
response = ollama.chat(
model=self.model,
messages=self.history,
options={'temperature': 0.306}
)
except Exception as e:
return f"⚠️ 请求失败: {str(e)}"
# 3. 将回答添加到历史记录
answer = response['message']['content']
self.history.append({'role': 'assistant', 'content': answer})
# 4. 格式化输出
wrapped = textwrap.fill(answer, width=max_width)
return f"\nDeepseek-R1:\n{wrapped}\n"
def clear_history(self):
self.history = []
# 使用示例
assistant = DeepSeekAssistant()
print(assistant.ask("你是一名人工智能专家"))
print(assistant.ask("请简单回顾典型的深度学习架构"))
往期回顾:
【人工智能通识专栏】第二十九讲:Deepseek助力文献检索
版权声明:
本文版权属于 AI小书房(aixiaoshufang@163.com),转载必须标注原文链接:
https://blog.csdn.net/AI_zhiyu/article/details/152376806
Copyright@AI小书房 2025
更多推荐

 21
21 0
0- 0



 已为社区贡献23条内容
已为社区贡献23条内容

所有评论(0)