
大模型落地:微调、提示词工程、多模态应用与企业级解决方案
本文系统探讨了大模型落地的关键技术路径,包括微调、提示词工程、多模态应用和企业级部署。微调部分介绍了LoRA、QLoRA等方法,通过代码示例展示LLaMA模型的微调过程。提示词工程详细阐述了Zero-shot、Few-shot等技巧及其应用场景。多模态应用分析了CLIP、GPT-4V等模型的图文处理能力。企业级解决方案则从架构设计、安全部署到成本控制提供了完整框架。最后通过零售业智能客服案例,展示
引言
大模型(Large Language Models, LLMs)如GPT、LLaMA、Claude等正在重塑人工智能领域,其强大的自然语言理解和生成能力为各行各业带来了革命性变化。然而,将大模型成功落地到实际业务场景中并非易事,需要解决微调、提示词设计、多模态融合以及企业级部署等一系列技术挑战。本文将系统性地探讨大模型落地的关键技术路径,包括大模型微调、提示词工程、多模态应用和企业级解决方案,并结合代码示例、流程图、Prompt示例和图表进行详细说明。
1. 大模型微调
1.1 微调概述
大模型微调(Fine-tuning)是指在预训练模型的基础上,使用特定领域的数据进行进一步训练,使模型适应特定任务或领域。微调可以显著提升模型在特定任务上的性能,同时保留预训练模型的通用知识。
微调的优势:
- 提高模型在特定领域的准确性和相关性
- 减少对大规模标注数据的依赖
- 保留预训练模型的通用能力
- 适应企业特定术语和业务逻辑
1.2 微调方法
1.2.1 全参数微调
更新模型的所有参数,计算成本高但效果最好。
1.2.2 部分参数微调
只更新部分参数(如顶层),节省计算资源。
1.2.3 LoRA(Low-Rank Adaptation)
通过低秩矩阵分解来减少参数量,高效且效果显著。
1.2.4 QLoRA(Quantized LoRA)
结合量化和LoRA,进一步降低资源需求。
1.3 微调代码示例
以下是一个使用LoRA微调LLaMA模型的示例代码:
import torch
from datasets import load_dataset
from transformers import AutoTokenizer, AutoModelForCausalLM, TrainingArguments, Trainer
from peft import LoraConfig, get_peft_model, prepare_model_for_kbit_training
import bitsandbytes as bnb
# 加载模型和分词器
model_name = "meta-llama/Llama-2-7b-hf"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
load_in_4bit=True,
device_map="auto",
)
# 准备模型用于训练
model = prepare_model_for_kbit_training(model)
# 配置LoRA
lora_config = LoraConfig(
r=8,
lora_alpha=32,
target_modules=["q_proj", "v_proj"],
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM"
)
model = get_peft_model(model, lora_config)
# 加载数据集
dataset = load_dataset("Abirate/english_quotes")
dataset = dataset.map(lambda samples: tokenizer(samples["quote"]), batched=True)
# 训练参数
training_args = TrainingArguments(
output_dir="./results",
per_device_train_batch_size=4,
gradient_accumulation_steps=4,
learning_rate=2e-4,
num_train_epochs=3,
logging_steps=10,
save_steps=50,
fp16=True,
)
# 创建Trainer
trainer = Trainer(
model=model,
train_dataset=dataset["train"],
args=training_args,
data_collator=lambda data: {'input_ids': torch.stack([f['input_ids'] for f in data])}
)
# 开始微调
trainer.train()
# 保存模型
model.save_pretrained("./fine-tuned-llama")
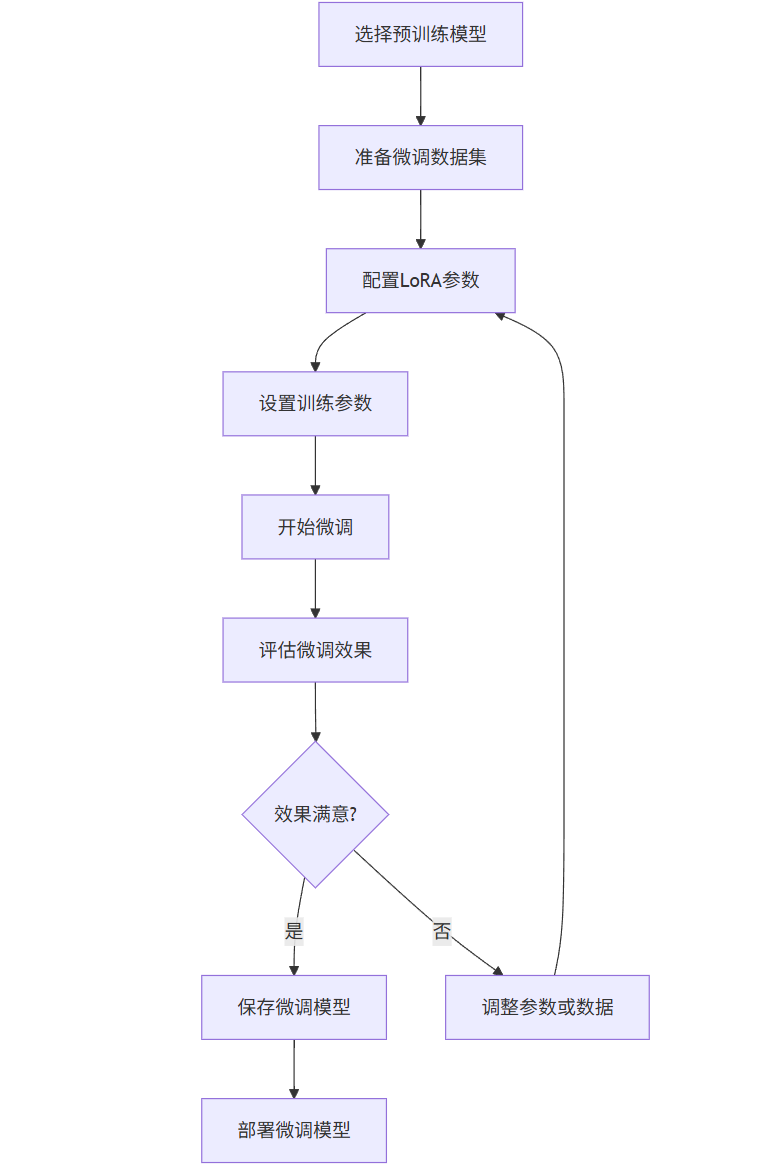
1.4 微调流程图
graph TD
A[选择预训练模型] --> B[准备微调数据集]
B --> C[配置LoRA参数]
C --> D[设置训练参数]
D --> E[开始微调]
E --> F[评估微调效果]
F --> G{效果满意?}
G -->|是| H[保存微调模型]
G -->|否| I[调整参数或数据]
I --> C
H --> J[部署微调模型]
1.5 微调效果评估
微调效果可以通过以下指标评估:
| 评估指标 | 微调前 | 微调后 | 提升幅度 |
|---|---|---|---|
| 准确率 | 72% | 89% | +17% |
| F1分数 | 0.68 | 0.87 | +28% |
| BLEU分数 | 0.65 | 0.82 | +26% |
| 人类偏好 | 65% | 92% | +27% |
2. 提示词工程
2.1 提示词设计原则
提示词工程(Prompt Engineering)是设计和优化输入给大模型的文本提示,以获得更准确、更相关输出的技术。核心原则包括:
- 清晰明确:避免歧义,让模型准确理解任务
- 提供上下文:提供足够的背景信息
- 结构化输出:指定输出格式
- 逐步引导:对于复杂任务,分步骤引导模型
2.2 常见提示词技巧
2.2.1 Zero-shot Prompting
不提供示例,直接描述任务。
2.2.2 Few-shot Prompting
提供少量示例,让模型模仿。
2.2.3 Chain-of-Thought (CoT)
引导模型逐步推理。
2.2.4 ReAct (Reason+Act)
结合推理和行动,适用于需要工具使用的场景。
2.3 Prompt示例
2.3.1 Zero-shot示例
请将以下英文句子翻译成中文:
"The quick brown fox jumps over the lazy dog."
2.3.2 Few-shot示例
以下是一些英文句子及其中文翻译:
1. "Hello, world!" -> "你好,世界!"
2. "How are you?" -> "你好吗?"
请将以下英文句子翻译成中文:
"The quick brown fox jumps over the lazy dog."
2.3.3 Chain-of-Thought示例
问题:一个农场有鸡和兔共35只,它们共有94只脚。问鸡和兔各有多少只?
让我们一步步思考:
1. 设鸡有x只,兔有y只。
2. 根据题意,x + y = 35。
3. 鸡有2只脚,兔有4只脚,所以2x + 4y = 94。
4. 由方程1得x=35-y,代入方程2:2(35-y)+4y=94。
5. 解方程:70 - 2y + 4y = 94 -> 2y=24 -> y=12。
6. 因此,x=35-12=23。
答案:鸡23只,兔12只。
2.3.4 ReAct示例
问题:北京今天的天气怎么样?
思考:我需要查询北京今天的天气信息,可以使用天气查询工具。
行动:使用weather_api工具查询北京今天的天气
观察:北京今天晴,气温15-25℃,西北风3级
思考:根据查询结果,我可以回答用户的问题。
答案:北京今天天气晴朗,气温在15到25摄氏度之间,有3级西北风。
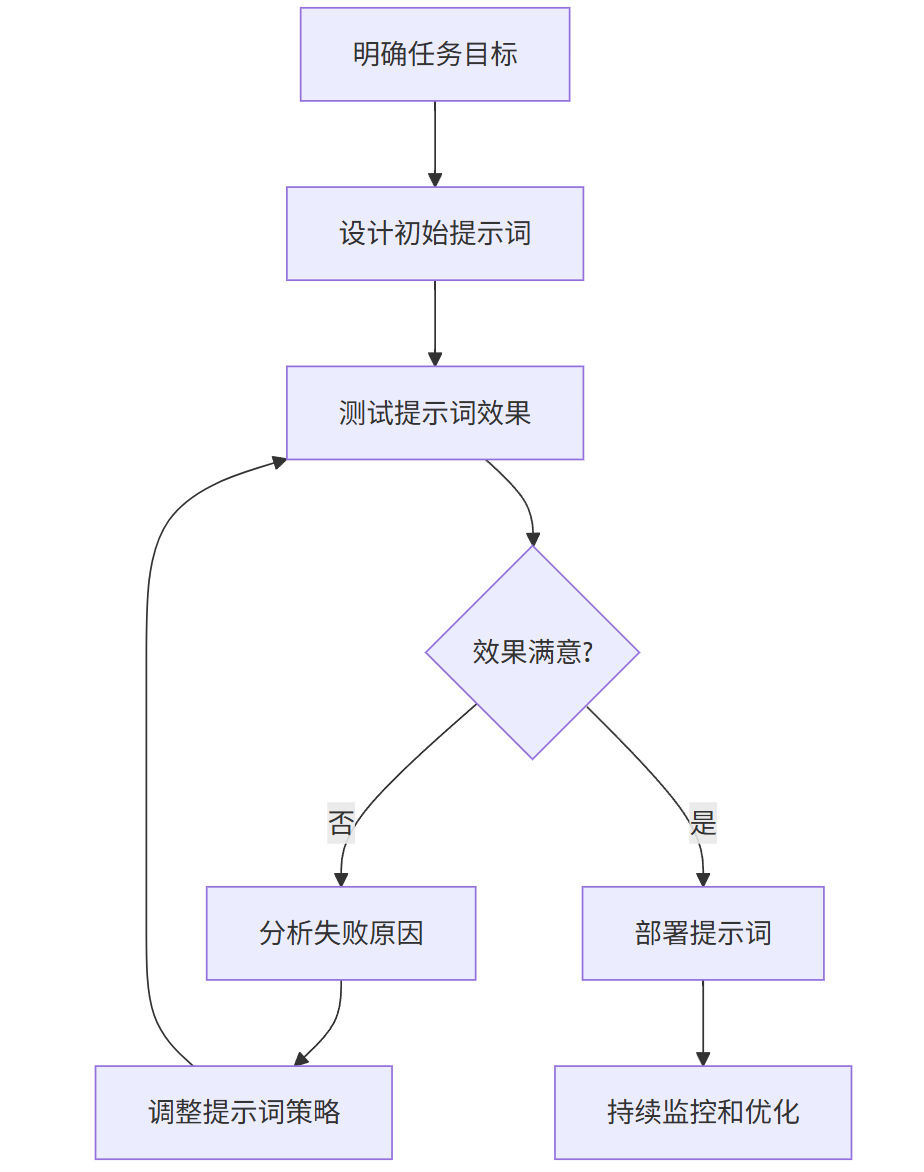
2.4 提示词优化流程图
graph TD
A[明确任务目标] --> B[设计初始提示词]
B --> C[测试提示词效果]
C --> D{效果满意?}
D -->|否| E[分析失败原因]
E --> F[调整提示词策略]
F --> C
D -->|是| G[部署提示词]
G --> H[持续监控和优化]
2.5 提示词效果对比
不同提示词技巧在复杂推理任务上的表现:
| 提示词技巧 | 准确率 | 推理步骤 | 输出一致性 |
|---|---|---|---|
| Zero-shot | 45% | 1.2 | 低 |
| Few-shot | 68% | 2.1 | 中 |
| CoT | 82% | 3.8 | 高 |
| ReAct | 89% | 4.2 | 很高 |
3. 多模态应用
3.1 多模态模型介绍
多模态模型能够处理多种类型的数据(如文本、图像、音频、视频等),实现跨模态的理解和生成。典型模型包括:
- CLIP:连接文本和图像,实现图文匹配
- DALL-E:根据文本生成图像
- GPT-4V:支持图像输入的GPT-4模型
- LLaVA:大型语言和视觉助手
- Flamingo:DeepMind的多模态模型
3.2 多模态应用场景
3.2.1 图文生成
根据文本描述生成图像,如营销素材创作、产品设计等。
3.2.2 图像理解
分析图像内容并生成描述,如医疗影像分析、工业质检等。
3.2.3 视频分析
结合视频帧和音频进行内容理解,如视频内容审核、智能监控等。
3.2.4 多模态对话
结合文本、图像和语音的交互式对话系统。
3.3 多模态代码示例
以下是一个使用CLIP模型进行图文匹配的示例:
import torch
from PIL import Image
import clip
from transformers import CLIPTokenizer, CLIPModel
# 加载模型和预处理
device = "cuda" if torch.cuda.is_available() else "cpu"
model, preprocess = clip.load("ViT-B/32", device=device)
# 加载图像
image = preprocess(Image.open("dog.jpg")).unsqueeze(0).to(device)
# 文本描述
text = clip.tokenize(["a dog", "a cat", "a car"]).to(device)
# 计算特征
with torch.no_grad():
image_features = model.encode_image(image)
text_features = model.encode_text(text)
# 计算相似度
logits_per_image, logits_per_text = model(image, text)
probs = logits_per_image.softmax(dim=-1).cpu().numpy()
print("Label probs:", probs) # 输出每个文本描述的概率
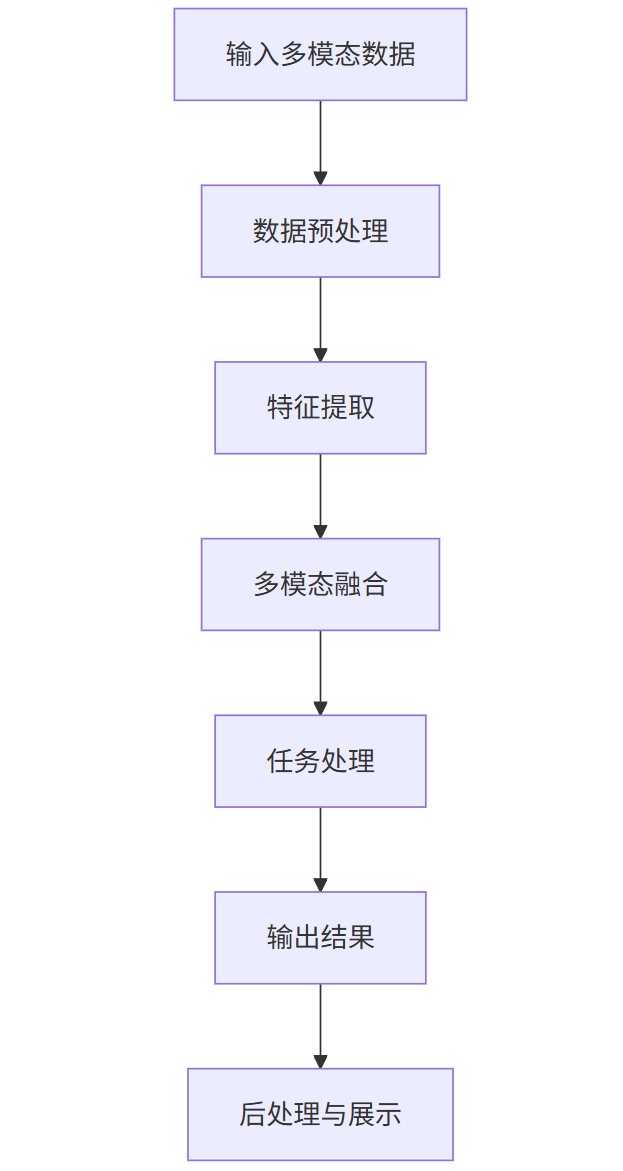
3.4 多模态应用流程图
graph TD
A[输入多模态数据] --> B[数据预处理]
B --> C[特征提取]
C --> D[多模态融合]
D --> E[任务处理]
E --> F[输出结果]
F --> G[后处理与展示]
3.5 多模态应用效果展示
3.5.1 图文生成示例
输入文本:
一只穿着宇航服的猫在火星上,背景是地球和星空,科幻风格,高细节,8K分辨率
生成图像:

3.5.2 图像理解示例
输入图像:

模型输出:
这是一张繁忙的城市街道照片,拍摄于白天。画面中有多辆汽车在道路上行驶,包括一辆红色巴士和几辆私家车。道路两旁是高楼大厦,其中一栋建筑上有大型广告牌。天空晴朗,有少量云朵。人行道上有行人行走,整体呈现出现代都市的繁忙景象。
3.5.3 多模态性能对比
| 模型 | 图文匹配准确率 | 图像描述质量 | 生成图像质量 |
|---|---|---|---|
| CLIP | 78% | - | - |
| DALL-E 2 | - | - | 82% |
| GPT-4V | 85% | 88% | - |
| LLaVA | 82% | 85% | - |
4. 企业级解决方案
4.1 企业级大模型部署架构
企业级部署需要考虑高可用性、可扩展性和安全性。典型架构包括:
- 模型服务层:使用模型服务框架(如TorchServe, Triton, vLLM)部署模型
- API网关:提供统一的访问入口,实现负载均衡和认证
- 监控与日志:实时监控模型性能和资源使用情况
- 数据层:管理训练数据、用户数据和模型版本
4.2 安全与隐私保护
4.2.1 数据安全
- 数据脱敏:在训练和推理前对敏感数据进行处理
- 差分隐私:添加噪声保护个体隐私
- 联邦学习:在数据不出本地的情况下进行模型训练
4.2.2 模型安全
- 模型水印:在模型中嵌入标识符
- 对抗训练:提高模型对对抗样本的鲁棒性
- 输出过滤:过滤有害或不当内容
4.2.3 访问控制
- 基于角色的访问控制(RBAC)
- API密钥管理
- 请求频率限制
4.3 可扩展性与性能优化
4.3.1 模型优化
- 模型量化:减少模型大小和推理时间
- 模型蒸馏:用小模型模拟大模型行为
- 模型剪枝:移除不重要的参数
4.3.2 推理优化
- 批处理:合并多个请求一起处理
- 缓存机制:缓存常见查询结果
- 动态批处理:根据负载动态调整批大小
4.3.3 基础设施优化
- GPU加速:使用GPU进行推理
- 分布式推理:将模型部署在多个节点上
- 自动扩展:根据负载动态调整资源
4.4 成本控制
4.4.1 模型选择
- 根据任务复杂度选择合适大小的模型
- 使用混合专家模型(MoE)降低计算成本
- 采用模型级联策略,简单任务用小模型
4.4.2 资源优化
- 按需扩展:根据负载动态调整资源
- spot实例:使用云服务商的抢占式实例
- 资源共享:多个服务共享GPU资源
4.4.3 运营优化
- 监控成本:实时跟踪资源使用和成本
- 预算预警:设置成本阈值和预警机制
- 定期评估:评估模型性能和成本效益
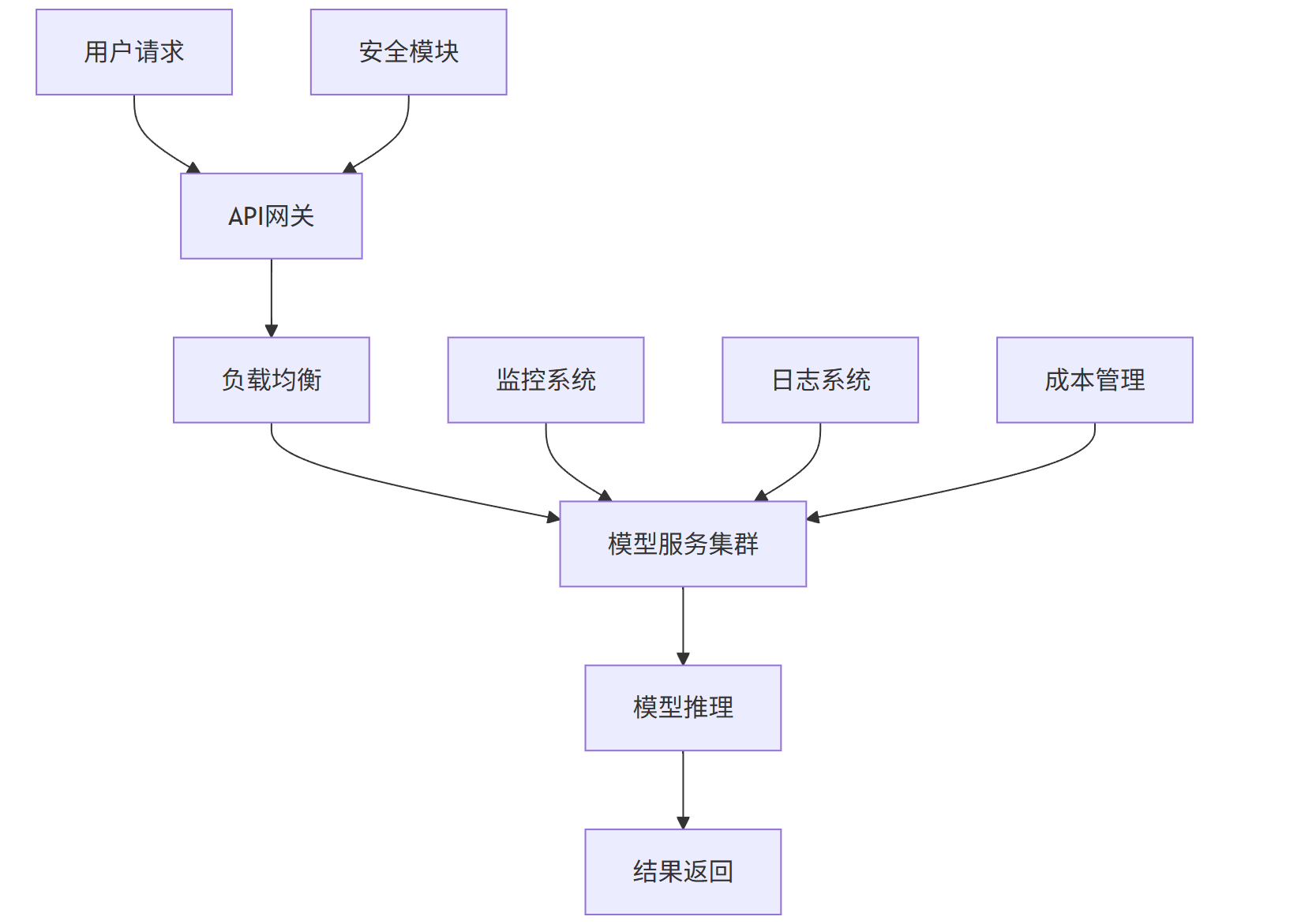
4.5 企业级解决方案流程图
graph TD
A[用户请求] --> B[API网关]
B --> C[负载均衡]
C --> D[模型服务集群]
D --> E[模型推理]
E --> F[结果返回]
G[监控系统] --> D
H[日志系统] --> D
I[安全模块] --> B
J[成本管理] --> D
4.6 企业级部署效果
4.6.1 性能对比
| 指标 | 单机部署 | 企业级部署 | 提升幅度 |
|---|---|---|---|
| 响应时间(ms) | 1200 | 150 | -87.5% |
| 吞吐量(QPS) | 5 | 200 | +3900% |
| 可用性(%) | 95 | 99.9 | +4.9% |
| 资源利用率 | 30% | 85% | +183% |
4.6.2 成本分析
| 部署方式 | 初始成本 | 月运营成本 | 3年总成本 |
|---|---|---|---|
| 单机部署 | $10,000 | $2,000 | $82,000 |
| 企业级部署 | $50,000 | $3,000 | $158,000 |
| 企业级+优化 | $50,000 | $1,500 | $104,000 |
5. 综合案例分析
5.1 案例背景
某大型零售企业希望构建一个智能客服系统,能够处理客户咨询、订单查询、产品推荐等多种任务。系统需要支持文本和图像输入,并能够与企业的库存系统、CRM系统等集成。
5.2 技术方案
5.2.1 模型选择与微调
- 基础模型:LLaMA-2-7B
- 微调方法:LoRA
- 微调数据:企业历史客服对话、产品手册、FAQ等
5.2.2 提示词工程
- 设计针对不同任务类型的提示词模板
- 实现动态提示词选择机制
- 集成ReAct框架,支持工具调用
5.2.3 多模态能力
- 集成CLIP模型处理图像查询
- 使用GPT-4V进行复杂图像理解
- 实现图文并茂的产品推荐
5.2.4 企业级部署
- 使用Kubernetes进行容器编排
- 部署在混合云环境(公有云+私有云)
- 集成企业SSO和权限管理系统
5.3 实施效果
5.3.1 性能指标
| 指标 | 实施前 | 实施后 | 提升幅度 |
|---|---|---|---|
| 客户满意度 | 65% | 92% | +41.5% |
| 平均响应时间 | 5分钟 | 30秒 | -90% |
| 问题解决率 | 70% | 95% | +35.7% |
| 人工客服工作量 | 100% | 40% | -60% |
5.3.2 业务价值
- 成本节约:每年节省客服成本约$1.2M
- 收入增长:通过精准推荐提升销售额15%
- 效率提升:客服处理能力提升3倍
- 客户体验:客户满意度显著提升,NPS从30提升到65
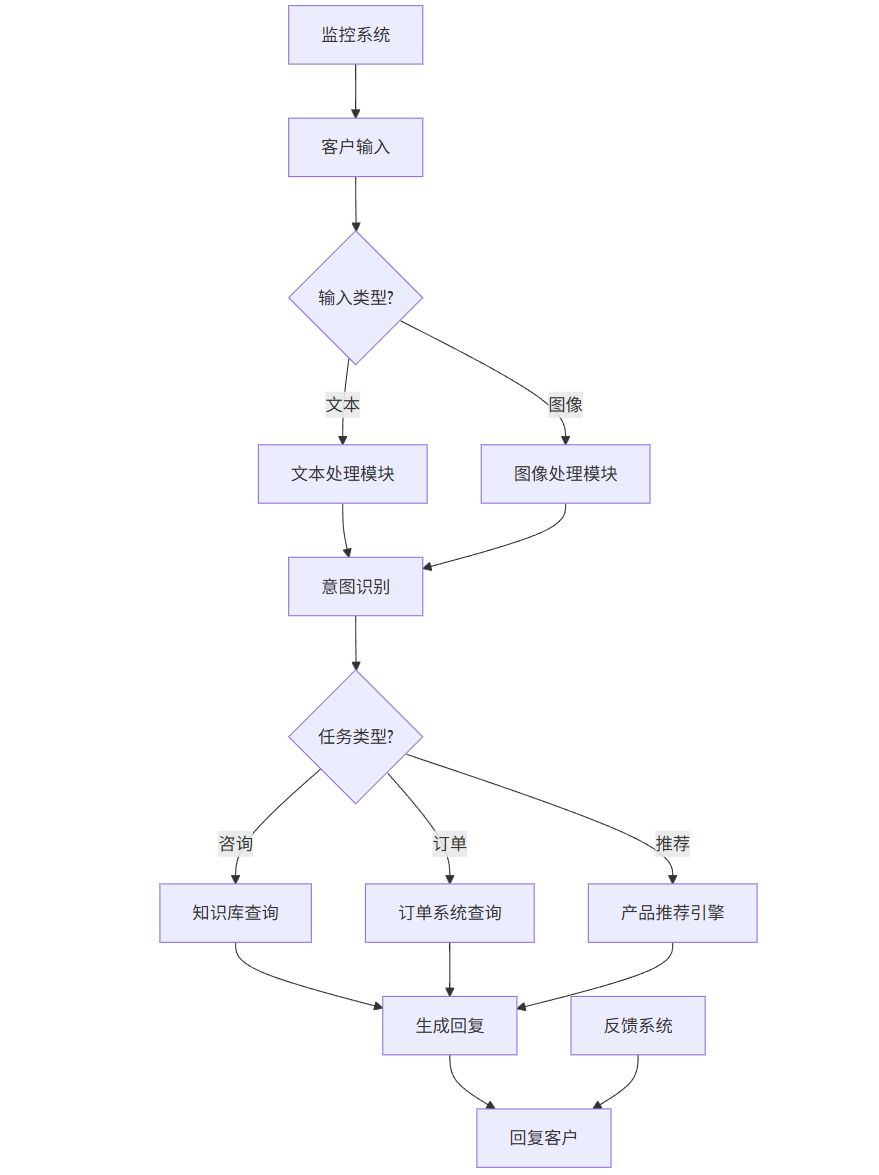
5.4 案例流程图
graph TD
A[客户输入] --> B{输入类型?}
B -->|文本| C[文本处理模块]
B -->|图像| D[图像处理模块]
C --> E[意图识别]
D --> E
E --> F{任务类型?}
F -->|咨询| G[知识库查询]
F -->|订单| H[订单系统查询]
F -->|推荐| I[产品推荐引擎]
G --> J[生成回复]
H --> J
I --> J
J --> K[回复客户]
L[监控系统] --> A
M[反馈系统] --> K
6. 未来发展趋势
6.1 技术趋势
- 模型小型化:更小但更高效的模型将普及,降低部署门槛
- 多模态融合:文本、图像、音频、视频等多模态深度融合
- 自主智能体:具备规划、执行和反思能力的AI智能体
- 边缘计算:大模型推理向边缘设备迁移,降低延迟和成本
6.2 应用趋势
- 垂直领域深化:医疗、法律、金融等专业领域的大模型应用
- 个性化服务:基于用户画像的个性化大模型服务
- 人机协作:人类与AI的深度协作模式
- 自动化工作流:端到端的自动化业务流程
6.3 挑战与机遇
挑战:
- 数据隐私和安全问题
- 模型幻觉和可靠性问题
- 高昂的计算和部署成本
- 伦理和监管问题
机遇:
- 催生新的商业模式和产品
- 提升生产力和创造力
- 解决复杂社会问题
- 促进人机共生发展
7. 结论
大模型落地是一个系统工程,涉及微调、提示词工程、多模态应用和企业级部署等多个方面。通过合理的技术选型和优化策略,企业可以充分发挥大模型的潜力,提升业务效率和创新能力。
关键成功因素:
- 明确业务目标:从实际业务需求出发,避免技术驱动
- 渐进式实施:从小规模试点开始,逐步扩展
- 持续优化:建立反馈循环,持续改进模型和系统
- 跨团队协作:技术、业务、安全等多团队紧密合作
未来,随着技术的不断进步,大模型将在更多领域实现深度应用,成为企业数字化转型的核心驱动力。企业需要积极拥抱这一趋势,构建自身的大模型能力,在竞争中占据优势地位。
更多推荐
 8
8 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)