
Agent升级必看!从ReAct到Plan-Driven演进全解析,核心逻辑拆解,收藏这篇就够了!
在构建智能运维(AIOps)Agent的初期,ReAct(Reasoning and Acting)框架提供了一个优秀的起点,它通过“思考-行动-观察”的循环,让Agent具备了基础的问题分解和工具调用能力。然而,面对复杂的、多因果关联的生产环境故障,纯粹的响应式(Reactive)方法会暴露其局限性。
「1. 引言」
在构建智能运维(AIOps)Agent的初期,ReAct(Reasoning and Acting)框架提供了一个优秀的起点,它通过“思考-行动-观察”的循环,让Agent具备了基础的问题分解和工具调用能力。然而,面对复杂的、多因果关联的生产环境故障,纯粹的响应式(Reactive)方法会暴露其局限性。
本文旨在深入探讨从ReAct模式演进到更高级的Plan-Driven(规划驱动)模式的具体实现路径,并结合学术界的前沿研究,为构建更强大、更鲁棒的AIOps Agent提供理论和实践指导。
「2. ReAct模式的回顾与局限性」
「2.1 ReAct工作流」
ReAct的核心思想是让大语言模型(LLM)交替生成“思考”(Thought)和“行动”(Action)。
- 「Thought:」 LLM对当前状态进行分析,推理下一步应该做什么。
- 「Action:」 LLM选择一个工具并提供参数。
- 「Observation:」 系统执行工具后,将结果返回给LLM。
这个循环不断重复,直到问题解决。
「2.2 ReAct的局限性」
对于复杂的AIOps场景,例如“服务A延迟上升,排查是上游服务B变更引起的,还是底层数据库C慢查询导致的”,ReAct模式会遇到挑战:
- 「短视性(Short-sightedness):」 Agent一次只思考一步,缺乏对问题全局的、长远的规划。可能会导致在排查路径上反复横跳,或者陷入局部最优解而错过了根本原因。
- 「缺乏宏观策略(Lack of High-level Strategy):」 难以处理包含复杂条件和依赖关系的诊断流程。例如,“如果指标A正常,则检查日志;否则,立即查询Trace B”,这种带有条件分支的宏观策略在ReAct的单步循环中难以优雅地表达和执行。
- 「错误恢复能力弱(Poor Error Recovery):」 当某一步的工具调用失败或返回了非预期的结果时,Agent很容易“迷失方向”。因为它没有一个更高层级的计划作为锚点,不知道如何调整策略以绕过当前的障碍。
「3. 实现Plan-Driven架构的工程路径」
演进的核心思想是:「先规划,后执行,并根据执行结果动态调整规划。」
「步骤1: 规划的生成 (Plan Generation)」
这是从ReAct到Plan-Driven的第一步,即让LLM在开始行动前,先输出一个完整的、高层次的计划。
- 「技术核心: Plan-of-Thought (PoT)」
- 通过精心设计的Prompt,引导LLM首先生成一个结构化的计划草稿。这个计划是解决问题的宏观蓝图。
- 「Prompt示例调整:」
System: 你是一个资深的SRE专家... 你的任务是为用户的问题生成一个详细的、分步骤的诊断计划,然后去执行它。请首先输出一个名为 "Plan" 的JSON对象,其中包含所有步骤。
User: 我的订单服务最近非常慢,请帮忙排查下原因。
Assistant:
{
"Plan": [
{
"step": 1,
"description": "检查订单服务的关键性能指标,确认延迟增高的具体时间和幅度。",
"tool_name": "get_service_metrics",
"parameters": {"service": "order-service", "metric_name": ["p95_latency", "error_rate"], "time_range": "past_6h"}
},
{
"step": 2,
"description": "如果错误率显著上升,查询同时间段的错误日志,寻找异常堆栈。",
"tool_name": "query_logs",
"parameters": {"service": "order-service", "keyword": "ERROR", "time_range": "dynamic"},
"condition": "step_1_result.error_rate > 0.05"
},
{
"step": 3,
"description": "如果延迟增高但错误率正常,随机捞取几条慢请求的Trace,分析其耗时瓶颈。",
"tool_name": "sample_slow_traces",
"parameters": {"service": "order-service", "time_range": "dynamic"},
"condition": "step_1_result.p95_latency > 500"
}
]
}
- 「优化手段: Few-shot Learning」
- 在Prompt中提供1-3个高质量的“问题-计划”范例(从Plan Database中精选),可以显著提升LLM生成计划的逻辑性和专业性。
步骤2:规划的表示与解析 (Plan Representation & Parsing) — 从“意图蓝图”到“可执行规程”
此阶段的核心使命,是将 LLM 生成的、高度概括的“作战意图”,转化为一份机器可以精确理解、调度和执行的、无歧义的“作战规程”。
「1. 规划的形态进化:从“清单”到“流程图 (DAG)”」
简单的线性列表无法表达复杂的运维逻辑。一个生产级的规划必须是有向无环图(DAG),因为它能内在地表达并行、分支和依赖。
「图1:规划表示法的演进」
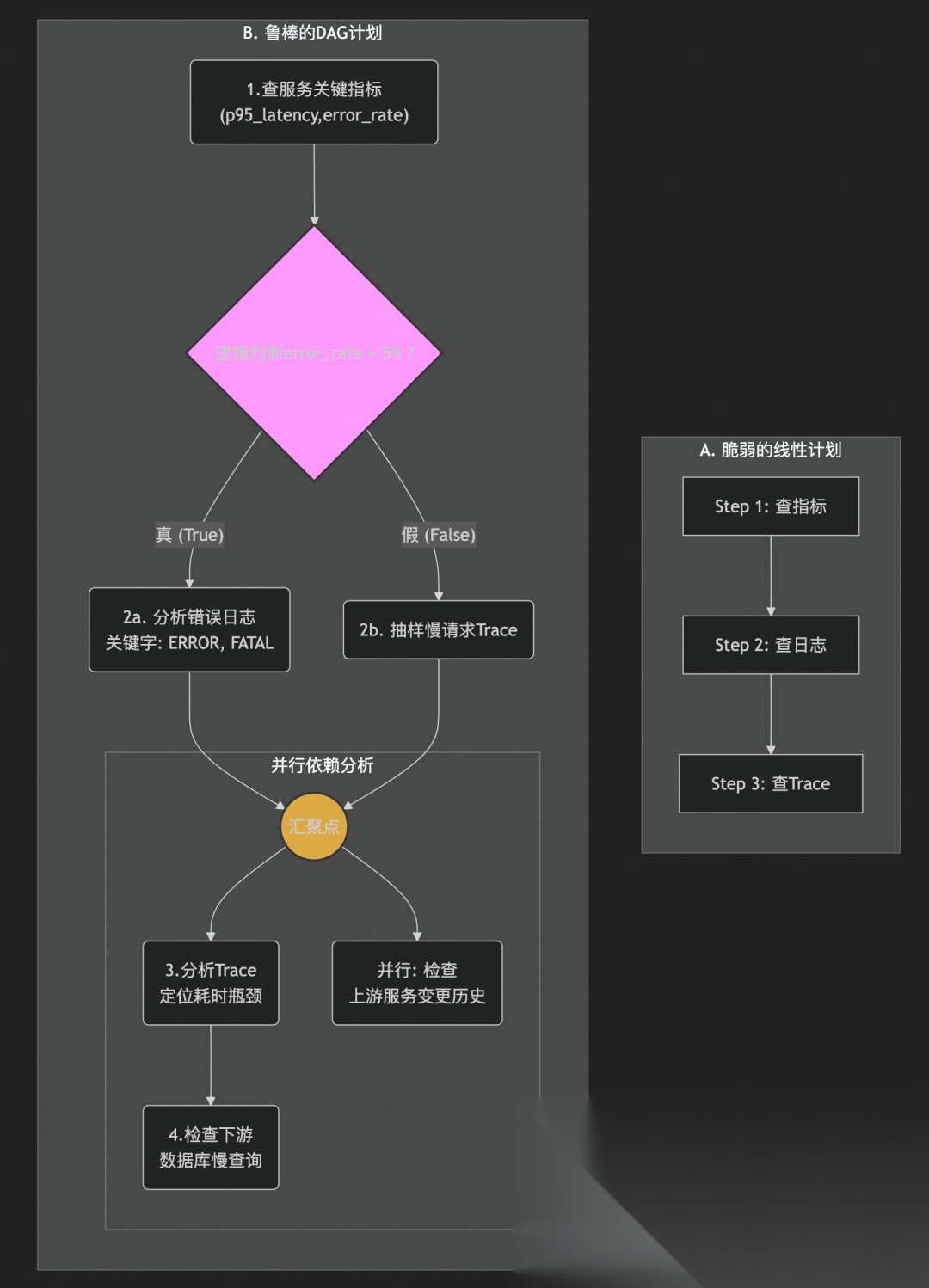
- 「图A (线性计划)」:像一张简单的待办事项清单,只能按顺序执行,无法应对意外情况。
- 「图B (DAG计划)」:是一张真正的作战地图。它清晰地定义了:
- 「条件分支 (Conditional Branching)」:
逻辑判断节点根据前一步的结果,动态地选择下一条执行路径。 - 「并行执行 (Parallel Execution)」:在
汇聚点之后,检查数据库和检查服务变更是两个互不依赖的任务,可以同时进行,大幅缩短总体排障时间。
「2. DAG 节点的逻辑构成:原子任务的“规程手册”」
图中的每一个节点,都是一个被精确定义的原子任务。它的定义必须包含执行、容错和控制所需的所有信息。
「逻辑描述:一个节点的完备定义」
- 「身份标识 (Identity)」:
node_id,一个在计划内唯一的名称,如check_service_metrics。 - 「核心指令 (Instruction)」:
tool_name: 要调用的工具或函数,如get_prometheus_metrics。parameters: 工具所需的参数。关键在于,参数值可以动态引用其他节点的输出,例如service_name: {{ nodes.start.input.service_name }},从而形成数据流。
- 「执行约束 (Constraints)」:
dependencies: 一个列表,声明了必须在本节点开始前成功完成的所有node_id。这是构建DAG结构的核心。
- 「应急预案 (Contingency Plan)」:
retry_policy: 定义重试逻辑,如{ "max_attempts": 3, "strategy": "exponential_backoff" }。timeout_seconds: 任务执行的超时限制。on_failure_goto: 声明式错误处理。如果本节点失败,则直接跳转到指定的“备用方案”节点,而不是让整个计划失败。
「3. 解析与验证:进入执行前的“多层政审”」
解析器的职责是作为一道坚固的闸门,确保任何逻辑不自洽、权限不足或格式错误的“规程”都无法进入执行阶段。
「图2:规划解析与验证的逻辑流程」
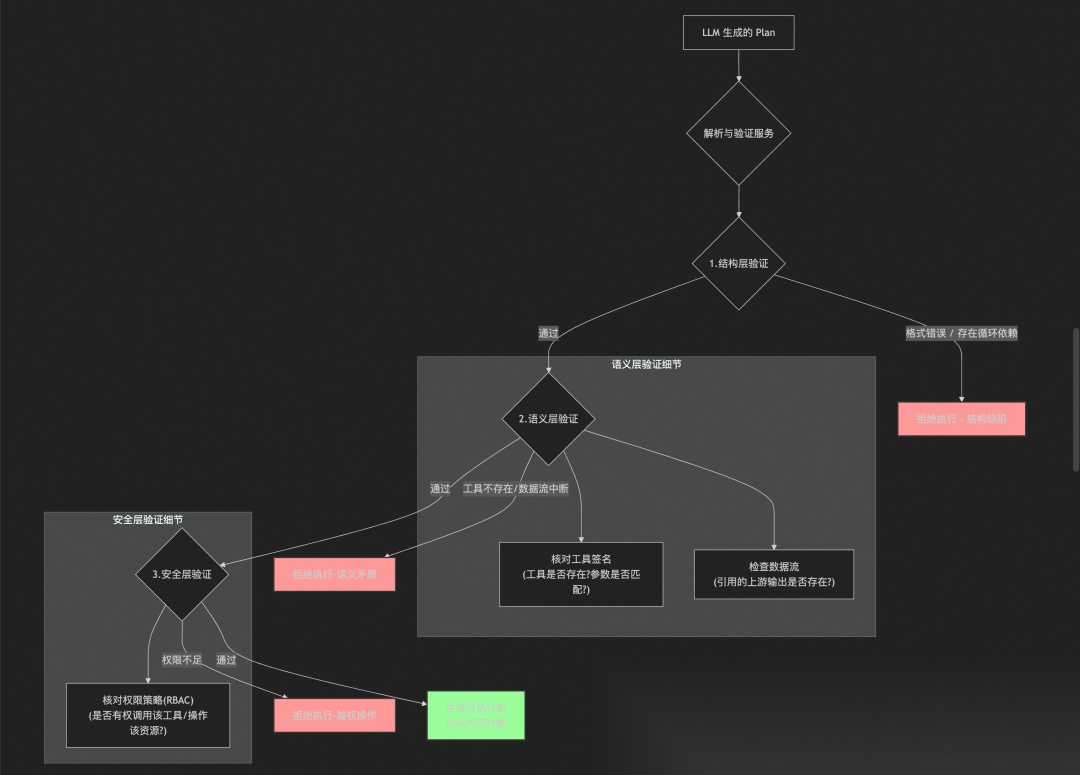
这个流程确保了只有在结构、语义和安全上都完全合规的计划,才会被“编译”成一个确定性的、可供执行引擎消费的内部表示。
步骤3:规划的执行与监控 (Plan Execution & Monitoring) — 可靠、透明的“自动化指挥中心”
执行引擎是 AIOps Agent 的“自主神经系统”。它不负责思考,只负责精确、可靠地执行已批准的“作战规程 (DAG)”,并对战场上的所有动态进行实时监控和记录。
「1. 核心架构:事件驱动的分布式状态机」
为了实现高可用和高扩展,执行引擎必须是事件驱动的,并且将所有状态持久化。它不是一个简单的循环,而是一个响应外部事件的反应式系统。
「图3:执行引擎的宏观逻辑架构」
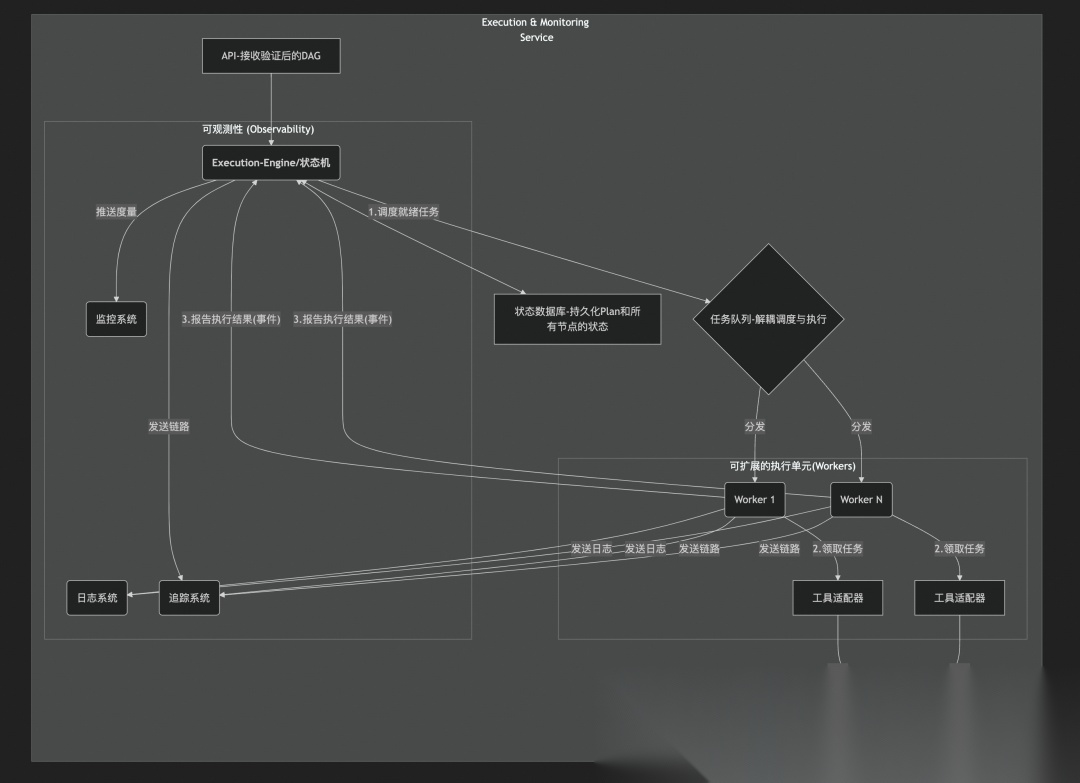
「2. 执行引擎的逻辑“心跳”」
下面是引擎在收到一个“节点执行完毕”事件后的核心处理逻辑,这是一个持续循环的反应过程。
- 「第1步:事件接收与状态固化」
- 引擎从内部事件总线或外部消息队列接收到一个“节点完成”事件(包含
plan_id,node_id,status,result)。 - 「立即行动」:将该节点的新状态(如
SUCCESS或FAILED)及其结果原子性地更新到状态数据库中。「这是保证系统可恢复性的关键」。
- 「第2步:失败路径处理」
-
「检查预案」:查询该节点的定义,看是否存在
on_failure_goto这样的错误处理指令。 -
「若有预案」:则将预案指向的节点(如
fallback_node)标记为“就绪”,并进入第4步。 -
「若无预案」:则将整个计划(Plan)的状态更新为
FAILED,终止所有相关活动。 -
「条件判断」:如果接收到的状态是
FAILED:
- 「第3步:成功路径处理」
-
「识别下游」:查询DAG的拓扑结构,找到所有直接依赖于刚刚完成的这个节点的下游节点。
-
「条件判断」:如果接收到的状态是
SUCCESS:
- 「第4步:新任务的评估与调度」
-
「检查依赖」:检查该下游节点的所有上游依赖(父节点)的状态是否**「全部」**为
SUCCESS。 -
「若依赖满足」:则将该下游节点的状态更新为
PENDING,并将其作为一个新的任务消息(包含plan_id和node_id)发布到任务队列中。 -
「若依赖未满足」:则不进行任何操作,等待其其他父节点完成。
-
「遍历下游」:对于每一个下游节点:
- 「第5步:循环」
- 引擎回到空闲状态,等待下一个“节点完成”事件的到来,重复以上过程,直到整个DAG所有最终节点都达到
SUCCESS状态或某个分支进入FAILED状态。
通过这套逻辑,我们将复杂的执行过程分解为一系列无状态、可重入的事件处理步骤,构建了一个既强大又极度稳健的自动化执行系统。
「步骤4: 规划的动态修正 (Dynamic Plan Refinement)」
这是最高级的形态,让Agent具备适应性。
- 当一个步骤执行失败或返回的结果与预期严重不符时(例如,查询日志,但没有找到任何错误),Execution Service不应直接终止。
- 它应将当前的“意外情况”(包含原始计划、已执行步骤和意外结果)打包,重新提交给Planning Service。
- Planning Service会向LLM发起一次“重新规划”(Re-planning)请求。
- 「Re-planning Prompt示例:」 “原始计划在执行步骤2时失败,因为日志系统过载。请基于此信息,生成一个修正后的新计划来继续排查问题。”
- LLM可能会提出一个替代方案,如“更换关键词重新查询日志”或“跳过日志分析,直接检查依赖服务的健康状况”。
「4. 学术界前沿研究与参考论文」
将工程实践与学术研究相结合,可以为系统演进提供更多思路。
- 「ReAct (基础框架)」
- **「论文:」**ReAct: Synergizing Reasoning and Acting in Language Models (Shunyu Yao, et al., 2022)
- 「简介:」 提出了将推理和行动相结合的Agent框架,是许多后续研究的基石。
- 「Chain-of-Thought / Plan-of-Thought (规划生成)」
- **「论文:」**Chain-of-Thought Prompting Elicits Reasoning in Large Language Models (Jason Wei, et al., 2022)
- 「简介:」 虽然主要讲的是推理链,但其“让模型先思考再回答”的思想是Plan-of-Thought的直接启发。
- 「LLM-Planner (规划与执行)」
- **「论文:」**LLM-Planner: Few-Shot Grounded Planning for Embodied Agents (Chan Hee Song, et al., 2022)
- 「简介:」 这篇论文探索了如何让LLM生成对物理世界有效的计划,并将计划“接地”(grounded)到可执行的动作上。其将高级规划和低级执行分离的思想与我们的架构不谋而合。
- 「HuggingGPT / JARVIS (多工具协同)」
- **「论文:」**HuggingGPT: Solving AI Tasks with ChatGPT and its Friends in Hugging Face (Yongliang Shen, et al., 2023)
- 「简介:」 展示了一个LLM作为控制器,调度Hugging Face上众多AI模型来完成多模态任务的系统。其任务分解和模型选择的机制对我们的Tool Executor和Planning Service有重要参考价值。
- 「Tree-of-Thoughts (ToT) (规划评估与筛选)」
- **「论文:」**Tree of Thoughts: Deliberate Problem Solving with Large Language Models (Shunyu Yao, et al., 2023)
- 「简介:」 提出了一种更高级的推理范式,允许LLM在一个“思想树”中探索多个推理路径,并使用自我评估来决定下一步的方向。这可以用于生成多个候选Plan,并从中选择最优的一个。
- 「Self-Correction / Reflection (规划修正)」
- **「论文:」**Self-Refine: Iterative Refinement with Self-Feedback (Aman Madaan, et al., 2023)
- 「简介:」 探索了让LLM自我反思和迭代式地优化其输出的能力。这种“生成-反馈-修正”的循环,正是我们“动态规划修正”阶段的核心算法思想。
- 「Agent Survey (宏观视角)」
- **「论文:」**A Survey on Large Language Model based Autonomous Agents (Lei Wang, et al., 2024)
- 「简介:」 对基于大语言模型的自主Agent进行了全面的综述,系统地梳理了Agent的构成、工作原理、长期目标、学习和规划能力。对于理解2024年Agent技术全景和发展趋势至关重要。
- 「Multi-Agent Framework (多Agent协同规划)」
- **「论文:」**AutoGen: Enabling Next-Gen LLM Applications with Multi-Agent Conversation (Qingyun Wu, et al., 2024)
- 「简介:」 提出了一个强大的多Agent对话框架,允许开发者定义多个具有不同角色和能力的Agent(如“规划师”、“执行者”、“审查员”),通过对话协作完成复杂任务。这种模式将规划过程转化为Agent间的协同对话,为解决复杂问题提供了新思路。
- 「Tool-Interactive Self-Correction (工具交互式修正)」
- **「论文:」**CRITIC: Large Language Models Can Self-Correct with Tool-Interactive Critiquing (Zhibin Gou, et al., 2024)
- 「简介:」 提出了一种更高级的自主修正方法。Agent不再仅仅进行内部反思,而是能主动调用外部工具(如代码解释器、API检查工具)来验证自己的推理和输出,获取外部世界的真实反馈,并基于这些反馈进行更精准的批判和修正。这对于需要高准确性的AIOps场景尤其有价值。
- 「Adaptive Planning (自适应规划 - 未来方向)」
- **「研究方向:」**Reinforcement Learning from Task Feedback for LLM Agents (2025及以后)
- 「简介:」 这是Agent规划能力演进的一个前沿方向。其核心思想是,Agent不再仅仅依赖Prompt生成静态计划,而是通过强化学习(RL)来学习一个自适应的规划“策略”。系统会根据任务执行的最终结果(如问题解决效率、资源消耗、用户满意度)给予Agent奖励或惩罚,从而让Agent在大量实践中持续迭代和优化其规划能力,变得越来越“智能”。
「5. 总结」
rning from Task Feedback for LLM Agents* (2025及以后)
- 「简介:」 这是Agent规划能力演进的一个前沿方向。其核心思想是,Agent不再仅仅依赖Prompt生成静态计划,而是通过强化学习(RL)来学习一个自适应的规划“策略”。系统会根据任务执行的最终结果(如问题解决效率、资源消耗、用户满意度)给予Agent奖励或惩罚,从而让Agent在大量实践中持续迭代和优化其规划能力,变得越来越“智能”。
「5. 总结」
从ReAct演进到Plan-Driven,本质上是让Agent从一个“战术执行者”转变为一个“战略规划师”。这不仅提升了解决复杂问题的上限,更重要的是,通过结构化的Plan,我们让Agent的决策过程变得更加透明、可控和可预测。结合学术界在规划、推理和自我修正方面的研究成果,我们可以构建一个真正能够胜任核心生产环境运维任务的AIOps平台大脑。
如何学习大模型 AI ?
我国在AI大模型领域面临人才短缺,数量与质量均落后于发达国家。2023年,人才缺口已超百万,凸显培养不足。随着Al技术飞速发展,预计到2025年,这一缺口将急剧扩大至400万,严重制约我国Al产业的创新步伐。加强人才培养,优化教育体系,国际合作并进,是破解困局、推动AI发展的关键。
但是具体到个人,只能说是:
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。

2025最新大模型学习路线
明确的学习路线至关重要。它能指引新人起点、规划学习顺序、明确核心知识点。大模型领域涉及的知识点非常广泛,没有明确的学习路线可能会导致新人感到迷茫,不知道应该专注于哪些内容。
对于从来没有接触过AI大模型的同学,我帮大家准备了从零基础到精通学习成长路线图以及学习规划。可以说是最科学最系统的学习路线。

针对以上大模型的学习路线我们也整理了对应的学习视频教程,和配套的学习资料。
大模型经典PDF书籍
新手必备的大模型学习PDF书单来了!全是硬核知识,帮你少走弯路!

配套大模型项目实战
所有视频教程所涉及的实战项目和项目源码等
博主介绍+AI项目案例集锦
MoPaaS专注于Al技术能力建设与应用场景开发,与智学优课联合孵化,培养适合未来发展需求的技术性人才和应用型领袖。


这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

为什么要学习大模型?
2025人工智能大模型的技术岗位与能力培养随着人工智能技术的迅速发展和应用 , 大模型作为其中的重要组成部分 , 正逐渐成为推动人工智能发展的重要引擎 。大模型以其强大的数据处理和模式识别能力, 广泛应用于自然语言处理 、计算机视觉 、 智能推荐等领域 ,为各行各业带来了革命性的改变和机遇 。

适合人群
- 在校学生:包括专科、本科、硕士和博士研究生。学生应具备扎实的编程基础和一定的数学基础,有志于深入AGI大模型行业,希望开展相关的研究和开发工作。
- IT行业从业人员:包括在职或失业者,涵盖开发、测试、运维、产品经理等职务。拥有一定的IT从业经验,至少1年以上的编程工作经验,对大模型技术感兴趣或有业务需求,希望通过课程提升自身在IT领域的竞争力。
- IT管理及技术研究领域人员:包括技术经理、技术负责人、CTO、架构师、研究员等角色。这些人员需要跟随技术发展趋势,主导技术创新,推动大模型技术在企业业务中的应用与改造。
- 传统AI从业人员:包括算法工程师、机器视觉工程师、深度学习工程师等。这些AI技术人才原先从事机器视觉、自然语言处理、推荐系统等领域工作,现需要快速补充大模型技术能力,获得大模型训练微调的实操技能,以适应新的技术发展趋势。

课程精彩瞬间
大模型核心原理与Prompt:掌握大语言模型的核心知识,了解行业应用与趋势;熟练Python编程,提升提示工程技能,为Al应用开发打下坚实基础。
RAG应用开发工程:掌握RAG应用开发全流程,理解前沿技术,提升商业化分析与优化能力,通过实战项目加深理解与应用。
Agent应用架构进阶实践:掌握大模型Agent技术的核心原理与实践应用,能够独立完成Agent系统的设计与开发,提升多智能体协同与复杂任务处理的能力,为AI产品的创新与优化提供有力支持。
模型微调与私有化大模型:掌握大模型微调与私有化部署技能,提升模型优化与部署能力,为大模型项目落地打下坚实基础。




顶尖师资,深耕AI大模型前沿技术
实战专家亲授,让你少走弯路
一对一学习规划,职业生涯指导
- 真实商业项目实训
- 大厂绿色直通车
人才库优秀学员参与真实商业项目实训
以商业交付标准作为学习标准,具备真实大模型项目实践操作经验可写入简历,支持项目背调
大厂绿色直通车,冲击行业高薪岗位


文中涉及到的完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
更多推荐

 13
13 0
0- 0



 已为社区贡献32条内容
已为社区贡献32条内容

所有评论(0)