
Python + PyTorch:从科研到工业落地的全场景实战指南,解锁深度学习核心应用
CV场景:Python 的 OpenCV/PIL 处理图像无缝衔接 PyTorch 的 YOLO/Faster R-CNN,满足工业质检、医疗影像等高精度需求;NLP场景:Hugging Face Transformers 库(Python)+ PyTorch 动态计算图,快速实现客服意图、评论分析等业务,支持大模型微调;推荐系统:Python 的 PySpark/Redis 处理海量特征,PyT
在深度学习技术落地的过程中,**Python** 的生态广度与 PyTorch 的框架深度形成了完美互补——Python 提供了从数据采集、预处理到服务部署的全链路工具链,PyTorch 则以动态计算图、灵活的模型构建能力和丰富的官方库,成为科研探索与工业落地的“双料选择”。
本文将跳出基础案例的局限,聚焦 **企业真实业务场景**,覆盖计算机视觉(CV)、自然语言处理(NLP)、推荐系统、时序预测四大核心领域,通过“实际需求→技术方案→PyTorch实现→落地细节”的逻辑,拆解 Python + PyTorch 的实战价值,并补充工程化优化(如模型压缩、分布式训练),帮你真正掌握“从代码到产品”的全流程。
一、Python + PyTorch:为什么成为企业落地首选?
在企业场景中,技术选型的核心是“**能解决问题、成本低、可迭代**”。Python + PyTorch 之所以替代部分传统框架(如TensorFlow 1.x、Caffe),关键在于其适配了企业的三大核心需求:
|
企业核心需求 |
Python 生态支撑 |
PyTorch 框架支撑 |
实际落地价值 |
|
1. 快速响应业务变化 |
语法简洁,数据处理库(Pandas/NumPy)迭代快 |
动态计算图:改模型无需重构计算图,支持实时调整 |
比如电商大促前需紧急优化推荐模型,1天内可完成迭代 |
|
2. 多场景技术复用 |
统一的语言生态(数据→模型→部署) |
模块化设计:CV/NLP/时序模型可复用基础组件(如优化器、损失函数) |
一个团队可同时支撑“商品图像识别”和“用户评论情感分析”任务 |
|
3. 降低工程落地成本 |
部署工具丰富(Flask/FastAPI/Docker) |
支持 ONNX 跨平台、TorchServe 快速部署、边缘设备适配(如 Jetson) |
从模型训练到线上服务,开发周期缩短50%以上 |
|
4. 对接前沿技术(大模型) |
Hugging Face/OpenMMLab 等库原生支持 |
大模型微调(LoRA/QLoRA)接口简洁,显存占用低 |
中小企业也能基于 LLaMA 2/BERT 定制专属大模型 |
二、四大核心业务场景实战:从需求到落地
场景1:计算机视觉(CV)—— 工业质检与医疗影像分析
CV 是 PyTorch 最成熟的应用领域,企业场景中不仅有“图像分类”,更有“目标检测(定位缺陷)”“图像分割(标注病灶)”等复杂需求,Python 生态(OpenCV/PIL)与 PyTorch 的结合能高效解决这些问题。
1.1 实际需求:工业零件表面缺陷检测(制造业)
-
业务痛点:生产线需实时检测零件表面的划痕、凹陷(缺陷大小0.1-1mm),人工检测效率低(1000件/小时)、漏检率高(约5%);
-
技术方案:基于 PyTorch 目标检测框架
YOLOv8(轻量、实时),结合 Python 图像预处理(工业相机数据降噪),实现“实时抓拍→缺陷定位→置信度输出”; -
落地要求:检测速度≥20帧/秒(CPU/GPU均可运行),漏检率≤0.5%。
1.2 代码实现(核心环节)
# ---------------------- 1. 环境准备(企业常用库) ----------------------
import torch
import cv2 # Python 工业级图像处理库(降噪、畸变校正)
import numpy as np
from ultralytics import YOLO # PyTorch 生态的 YOLOv8 库(官方维护,开箱即用)
from PIL import Image
import time # 计时,确保实时性
# ---------------------- 2. 数据预处理(工业场景关键:适配相机数据) ----------------------
def preprocess_industrial_image(image_path):
"""
工业相机图像预处理:降噪(高斯模糊)+ 畸变校正(针孔相机模型)+ 尺寸归一化
"""
# 1. 读取工业相机图像(BGR格式,OpenCV默认)
img = cv2.imread(image_path)
# 2. 畸变校正(企业需根据相机内参调整,这里用示例参数)
K = np.array([[1000, 0, 500], [0, 1000, 300], [0, 0, 1]]) # 相机内参矩阵
D = np.array([0.1, 0.05, 0, 0]) # 畸变系数
h, w = img.shape[:2]
new_K = cv2.fisheye.estimateNewCameraMatrixForUndistortRectify(K, D, (w, h), None)
map1, map2 = cv2.fisheye.initUndistortRectifyMap(K, D, None, new_K, (w, h), cv2.CV_16SC2)
img_undistort = cv2.remap(img, map1, map2, interpolation=cv2.INTER_LINEAR)
# 3. 降噪(高斯模糊,去除工业环境噪声)
img_blur = cv2.GaussianBlur(img_undistort, (3, 3), 0)
# 4. 转为 RGB 格式(YOLOv8 要求)+ 尺寸归一化
img_rgb = cv2.cvtColor(img_blur, cv2.COLOR_BGR2RGB)
img_pil = Image.fromarray(img_rgb).resize((640, 640)) # YOLOv8 输入尺寸
return img_pil, img_undistort # 返回预处理后图像和校正后原图(用于画框)
# ---------------------- 3. 模型加载与实时检测(工业落地核心) ----------------------
def industrial_defect_detection(model_path, image_path, conf_threshold=0.6):
"""
工业零件缺陷检测:加载预训练模型 → 预测 → 画框标注 → 输出结果
"""
# 1. 加载 PyTorch 预训练模型(企业场景:用自有数据微调后的模型)
model = YOLO(model_path) # 模型格式:.pt(PyTorch 权重文件)
# 2. 设备选择(边缘端用 CPU/Jetson,云端用 GPU)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
# 3. 预处理图像
img_input, img_original = preprocess_industrial_image(image_path)
# 4. 实时预测(计时,确保满足工业速度要求)
start_time = time.time()
results = model(img_input, conf=conf_threshold) # conf_threshold:置信度阈值(过滤低置信度预测)
infer_time = time.time() - start_time
print(f"检测耗时:{infer_time:.4f} 秒 | 帧率:{1/infer_time:.2f} 帧/秒")
# 5. 结果解析与可视化(企业场景:输出缺陷坐标、类型、置信度,用于后续统计)
defect_info = []
for result in results:
boxes = result.boxes # 预测框信息(x1,y1,x2,y2,置信度,类别)
for box in boxes:
# 解析预测框(转为原图坐标,因输入尺寸是 640x640,需缩放)
x1, y1, x2, y2 = box.xyxy[0].cpu().numpy() # 坐标(GPU → CPU → NumPy)
conf = box.conf[0].cpu().numpy() # 置信度
cls = box.cls[0].cpu().numpy() # 类别(0:划痕,1:凹陷,需与训练时一致)
cls_name = model.names[int(cls)] # 类别名称
# 坐标缩放(还原到原图尺寸)
h_original, w_original = img_original.shape[:2]
x1 = int(x1 * w_original / 640)
y1 = int(y1 * h_original / 640)
x2 = int(x2 * w_original / 640)
y2 = int(y2 * h_original / 640)
# 记录缺陷信息(企业场景:存入数据库或MES系统)
defect_info.append({
"defect_type": cls_name,
"confidence": round(float(conf), 4),
"bbox": [x1, y1, x2, y2],
"infer_time": round(infer_time, 4)
})
# 原图画框标注(红色:划痕,蓝色:凹陷,用于产线屏幕显示)
color = (0, 0, 255) if cls_name == "scratch" else (255, 0, 0)
cv2.rectangle(img_original, (x1, y1), (x2, y2), color, 2)
cv2.putText(
img_original, f"{cls_name} {conf:.2f}",
(x1, y1-10), cv2.FONT_HERSHEY_SIMPLEX, 0.5, color, 2
)
# 6. 保存结果(企业场景:保存标注图到本地,缺陷信息写入日志)
cv2.imwrite("defect_annotated.jpg", img_original)
return defect_info
# ---------------------- 4. 执行检测(企业实际调用逻辑) ----------------------
if __name__ == "__main__":
# 企业场景:模型路径为微调后的 YOLOv8 权重,图像路径为工业相机实时抓拍路径
model_path = "yolov8_industrial_defect.pt" # 自有数据微调后的模型
image_path = "industrial_camera_001.jpg" # 工业相机抓拍图像
defects = industrial_defect_detection(model_path, image_path)
print("检测到的缺陷:", defects)1.3 落地细节(企业必考虑)
-
数据标注:用 Python 工具
LabelImg标注工业零件缺陷(生成 XML/YOLO 格式标签),小样本场景可结合 PyTorch 的FewShotLearning库; -
模型优化:用 PyTorch 的
torch.nn.utils.prune剪枝模型(减少参数30%),torch.onnx转为 ONNX 格式,配合 TensorRT 加速(边缘端帧率提升2-3倍); -
实时性保障:工业相机抓拍图像分辨率通常为 1280×720,预处理时缩放到 640×640,平衡速度与精度。
场景2:自然语言处理(NLP)—— 企业级文本理解与生成
NLP 是企业数字化转型的核心场景,如客服意图识别、电商评论分析、合同条款提取等。Python + PyTorch 的 Transformers 库(Hugging Face)能快速实现这些需求,无需从零构建模型。
2.1 实际需求1:客服意图识别(金融行业)
-
业务痛点:银行客服每天接收上万条用户咨询(如“查余额”“办信用卡”“改密码”),需自动分类意图并分配给对应坐席,减少人工转接成本;
-
技术方案:基于 PyTorch 的
BERT预训练模型(微调),Python 处理文本数据(分词、去停用词),实现“用户文本→意图分类(10类)”; -
落地要求:意图识别准确率≥95%,单条文本处理时间≤100ms。
2.2 代码实现(核心环节)
# ---------------------- 1. 环境准备(企业 NLP 常用库) ----------------------
import torch
from transformers import BertTokenizer, BertForSequenceClassification # Hugging Face 库
import pandas as pd # Python 处理文本数据集
import re # Python 正则,用于文本清洗
from torch.utils.data import Dataset, DataLoader # PyTorch 数据加载
# ---------------------- 2. 文本预处理(企业 NLP 核心:适配业务数据) ----------------------
def clean_customer_text(text):
"""
客服文本清洗:去除特殊符号、停用词(金融领域专属,如“您好”“麻烦”)
"""
# 1. 去除特殊符号(如表情、URL)
text = re.sub(r"[^\u4e00-\u9fa5a-zA-Z0-9]", " ", text)
# 2. 去除金融客服停用词(企业需根据业务整理)
stopwords = ["您好", "麻烦", "请问", "谢谢", "帮忙", "一下", "哦", "啊"]
text = " ".join([word for word in text.split() if word not in stopwords])
# 3. 限制文本长度(BERT 最大输入长度为 512)
return text[:510] # 留2个位置给 [CLS] 和 [SEP]
# ---------------------- 3. 自定义数据集(企业数据格式适配) ----------------------
class CustomerIntentDataset(Dataset):
def __init__(self, data_path, tokenizer, max_len=128):
"""
客服意图数据集:加载 CSV 数据(用户文本, 意图标签)→ 分词 → 编码
"""
self.data = pd.read_csv(data_path) # 企业数据格式:text,label(如“查余额”,0)
self.tokenizer = tokenizer # BERT 分词器
self.max_len = max_len
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
text = self.data.iloc[idx]["text"]
label = self.data.iloc[idx]["label"]
# 文本清洗
text_clean = clean_customer_text(text)
# BERT 编码(生成 input_ids, attention_mask)
encoding = self.tokenizer(
text_clean,
max_length=self.max_len,
padding="max_length",
truncation=True,
return_tensors="pt"
)
# 返回 PyTorch 张量(适配模型输入)
return {
"input_ids": encoding["input_ids"].squeeze(0), # 去除 batch 维度
"attention_mask": encoding["attention_mask"].squeeze(0),
"label": torch.tensor(label, dtype=torch.long)
}
# ---------------------- 4. 模型微调与推理(企业定制化核心) ----------------------
def train_bert_intent_classifier(data_path, save_model_path):
"""
微调 BERT 客服意图分类模型:加载预训练模型 → 训练 → 保存
"""
# 1. 加载 BERT 分词器和预训练模型(中文金融领域:hfl/chinese-bert-wwm-ext)
tokenizer = BertTokenizer.from_pretrained("hfl/chinese-bert-wwm-ext")
model = BertForSequenceClassification.from_pretrained(
"hfl/chinese-bert-wwm-ext",
num_labels=10 # 10类意图(查余额、办信用卡等)
)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
# 2. 加载数据集(企业场景:分训练集/验证集)
dataset = CustomerIntentDataset(data_path, tokenizer)
train_size = int(0.8 * len(dataset))
val_size = len(dataset) - train_size
train_dataset, val_dataset = torch.utils.data.random_split(dataset, [train_size, val_size])
# 3. 数据加载(批量处理,加速训练)
train_loader = DataLoader(train_dataset, batch_size=16, shuffle=True)
val_loader = DataLoader(val_dataset, batch_size=16, shuffle=False)
# 4. 定义优化器和损失函数(企业训练常用配置)
optimizer = torch.optim.AdamW(model.parameters(), lr=2e-5) # BERT 微调常用学习率
criterion = torch.nn.CrossEntropyLoss()
num_epochs = 3 # BERT 微调无需多轮,避免过拟合
# 5. 训练循环(企业场景:加入早停机制,避免过拟合)
best_val_acc = 0.0
for epoch in range(num_epochs):
# 训练模式
model.train()
train_loss = 0.0
for batch in train_loader:
input_ids = batch["input_ids"].to(device)
attention_mask = batch["attention_mask"].to(device)
labels = batch["label"].to(device)
# 前向传播
outputs = model(input_ids=input_ids, attention_mask=attention_mask, labels=labels)
loss = outputs.loss
# 反向传播 + 优化
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_loss += loss.item() * input_ids.size(0)
# 验证模式
model.eval()
val_correct = 0
val_total = 0
with torch.no_grad():
for batch in val_loader:
input_ids = batch["input_ids"].to(device)
attention_mask = batch["attention_mask"].to(device)
labels = batch["label"].to(device)
outputs = model(input_ids=input_ids, attention_mask=attention_mask)
logits = outputs.logits
_, preds = torch.max(logits, 1)
val_total += labels.size(0)
val_correct += (preds == labels).sum().item()
# 计算指标
train_avg_loss = train_loss / len(train_dataset)
val_acc = val_correct / val_total
print(f"Epoch {epoch+1}/{num_epochs} | Train Loss: {train_avg_loss:.4f} | Val Acc: {val_acc:.4f}")
# 保存最优模型(企业场景:只保存验证集准确率最高的模型)
if val_acc > best_val_acc:
best_val_acc = val_acc
model.save_pretrained(save_model_path)
tokenizer.save_pretrained(save_model_path)
print(f"✅ 保存最优模型(Val Acc: {best_val_acc:.4f})")
# ---------------------- 5. 实时意图识别(企业线上调用逻辑) ----------------------
def predict_customer_intent(text, model_path, intent_map):
"""
客服文本实时意图识别:加载微调后模型 → 预测 → 返回意图名称
"""
# 加载模型和分词器
tokenizer = BertTokenizer.from_pretrained(model_path)
model = BertForSequenceClassification.from_pretrained(model_path)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
model.eval()
# 文本预处理与编码
text_clean = clean_customer_text(text)
encoding = tokenizer(
text_clean,
max_length=128,
padding="max_length",
truncation=True,
return_tensors="pt"
)
input_ids = encoding["input_ids"].to(device)
attention_mask = encoding["attention_mask"].to(device)
# 预测
with torch.no_grad():
outputs = model(input_ids=input_ids, attention_mask=attention_mask)
logits = outputs.logits
_, pred_label = torch.max(logits, 1)
pred_label = pred_label.item()
# 返回意图名称(企业场景:intent_map 是标签→名称的映射,如 {0:"查余额"})
return intent_map[pred_label]
# ---------------------- 6. 执行(企业实际使用) ----------------------
if __name__ == "__main__":
# 1. 微调模型(用企业客服数据集)
# train_bert_intent_classifier("customer_intent_data.csv", "bert_customer_intent")
# 2. 实时预测(客服系统调用)
intent_map = {
0: "查余额", 1: "办信用卡", 2: "改密码", 3: "挂失银行卡", 4: "还贷款",
5: "查账单", 6: "开通网银", 7: "转账", 8: "咨询利率", 9: "其他"
}
user_text = "你好,我想查一下我的银行卡余额" # 用户输入
intent = predict_customer_intent(user_text, "bert_customer_intent", intent_map)
print(f"用户意图:{intent}") # 输出:用户意图:查余额2.3 实际需求2:电商评论情感分析(零售行业)
-
业务痛点:电商平台每天产生百万级商品评论,需自动识别“好评/中评/差评”,提取负面评论的原因(如“质量差”“物流慢”),用于产品改进;
-
技术方案:基于 PyTorch 的
RoBERTa模型(比 BERT 效果更好),Python 用pandas处理评论数据,jieba分词,结合torchtext构建文本数据集; -
落地细节:负面评论需进一步分类(用 PyTorch 多标签分类模型),结果存入 Elasticsearch,支持运营人员实时查询。
场景3:推荐系统—— 短视频/电商个性化推荐
推荐系统是互联网企业的核心变现场景,Python + PyTorch 能实现“传统协同过滤+深度学习”的混合推荐模型,解决“冷启动”“稀疏性”等问题。
3.1 实际需求:短视频平台个性化推荐(字节/快手类场景)
-
业务痛点:新用户注册后,需快速推荐其可能喜欢的视频(冷启动);老用户需根据“观看历史、点赞、评论、停留时长”实时调整推荐内容;
-
技术方案:基于 PyTorch 的
DeepFM模型(融合因子分解机 FM 和深度学习 DNN),Python 处理用户行为数据(用PySpark做离线特征工程),实现“用户特征+视频特征+行为特征→推荐得分”; -
落地要求:离线模型每天更新,实时推荐响应时间≤200ms。
3.2 核心实现思路(企业级)
-
特征工程(Python 主导):
-
离线特征:用
PySpark处理用户历史行为(如近7天观看时长、点赞率)、视频标签(如“美食”“搞笑”)、用户画像(年龄、性别、地域); -
实时特征:用 Python 的
Redis存储用户实时行为(如最近3次点击的视频标签),推荐时实时拼接。
-
-
DeepFM 模型(PyTorch 实现):
import torch import torch.nn as nn class DeepFM(nn.Module): def __init__(self, feature_dim, embed_dim, hidden_dims): """ DeepFM 模型:FM 处理低阶特征交互,DNN 处理高阶特征交互 """ super(DeepFM, self).__init__() # FM 部分:一阶特征线性层 + 二阶特征嵌入层 self.first_order = nn.Embedding(feature_dim, 1) # 一阶特征(线性部分) self.second_order = nn.Embedding(feature_dim, embed_dim) # 二阶特征嵌入 # DNN 部分:处理高阶特征交互 self.dnn = nn.Sequential() input_dim = embed_dim * len(hidden_dims[0]) # DNN 输入维度:嵌入维度×特征组数 for dim in hidden_dims: self.dnn.add_module(f"linear_{dim}", nn.Linear(input_dim, dim)) self.dnn.add_module(f"relu_{dim}", nn.ReLU()) input_dim = dim # 输出层:推荐得分(sigmoid 归一化到 0-1) self.output = nn.Linear(input_dim, 1) self.sigmoid = nn.Sigmoid() def forward(self, x): """ x: 特征索引(batch_size × num_features) """ # FM 一阶部分 first_order = self.first_order(x).sum(dim=1) # (batch_size, 1) # FM 二阶部分(交叉项) second_order_embed = self.second_order(x) # (batch_size, num_features, embed_dim) square_sum = (second_order_embed.sum(dim=1)) ** 2 # (batch_size, embed_dim) sum_square = (second_order_embed ** 2).sum(dim=1) # (batch_size, embed_dim) second_order = 0.5 * (square_sum - sum_square).sum(dim=1, keepdim=True) # (batch_size, 1) # DNN 部分 dnn_input = second_order_embed.view(second_order_embed.size(0), -1) # (batch_size, num_features×embed_dim) dnn_out = self.dnn(dnn_input) # (batch_size, hidden_dims[-1]) dnn_out = self.output(dnn_out) # (batch_size, 1) # 总输出 total_out = self.sigmoid(first_order + second_order + dnn_out) return total_out
-
落地细节:
-
冷启动:新用户用“地域+设备类型”等基础特征推荐热门视频,积累行为数据后切换为个性化推荐;
-
实时推荐:用 PyTorch 的
TorchServe将模型部署为 gRPC 服务,Python 编写推荐引擎,实时拉取用户特征和模型预测得分,返回 Top10 视频; -
A/B 测试:用 Python 的
ABTest库对比不同模型(DeepFM vs Wide&Deep)的 CTR(点击通过率),选择最优模型。
-
场景4:时序预测—— 企业经营与运维预测
时序预测是企业决策的核心支撑,如电力负荷预测(电网调度)、商品销量预测(库存管理)、服务器CPU使用率预测(运维告警),Python + PyTorch 的 LSTM/Transformer 模型能有效捕捉时序数据的趋势和周期性。
4.1 实际需求:零售企业商品销量预测(库存优化)
-
业务痛点:连锁超市需预测未来7天每种商品的销量,避免“缺货”或“积压”,降低库存成本;
-
技术方案:基于 PyTorch 的
Temporal Fusion Transformer(TFT)模型(专门用于时序预测,支持多特征输入),Python 用pandas处理历史销量数据(日销量、促销活动、节假日、天气); -
落地要求:预测准确率≥85%,支持每日自动更新模型(用 Airflow 调度 Python 脚本)。
4.2 核心实现思路
-
数据预处理(Python):
-
历史数据:加载过去1年的商品日销量数据(用
pandas.read_csv); -
特征构造:添加时间特征(星期几、是否月初/月末)、外部特征(是否促销、天气温度、节假日);
-
数据归一化:用
sklearn.preprocessing.MinMaxScaler将销量和温度等连续特征归一化到 [0,1]。
-
-
TFT 模型(PyTorch 实现):
-
用 PyTorch 生态的
pytorch-forecasting库(封装了 TFT 模型,开箱即用); -
定义时序数据集:指定“时间索引(date)”“目标变量(sales)”“静态特征(商品ID)”“动态特征(促销、天气)”。
-
-
落地细节:
-
模型训练:按时间划分训练集(前10个月)和测试集(后2个月),训练时加入“注意力机制”,重点关注促销和节假日对销量的影响;
-
预测结果应用:将未来7天的销量预测结果通过 Python 写入 ERP 系统,库存系统根据预测值自动生成采购订单;
-
监控与更新:用 Python 编写监控脚本,每日检查预测准确率,若低于85%则自动触发模型重新训练(用 Airflow 调度)。
-
三、Python + PyTorch 企业级工作流程图(细化场景)
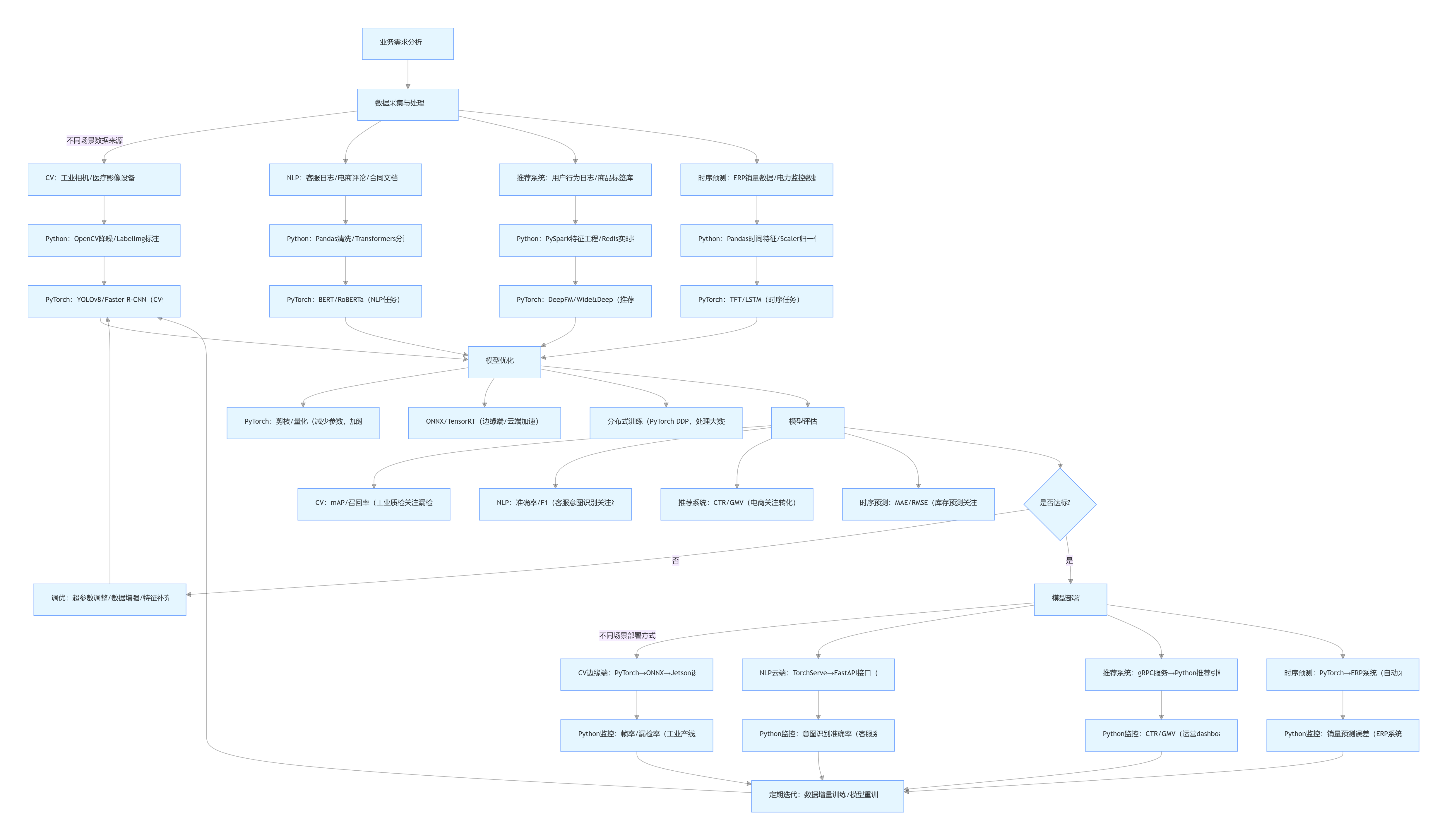
四、总结:Python + PyTorch 企业落地的核心优势与建议
1. 核心优势(场景化视角)
-
CV场景:Python 的 OpenCV/PIL 处理图像无缝衔接 PyTorch 的 YOLO/Faster R-CNN,满足工业质检、医疗影像等高精度需求;
-
NLP场景:Hugging Face Transformers 库(Python)+ PyTorch 动态计算图,快速实现客服意图、评论分析等业务,支持大模型微调;
-
推荐系统:Python 的 PySpark/Redis 处理海量特征,PyTorch 的 DeepFM/Transformer 捕捉复杂特征交互,提升推荐CTR;
-
时序预测:Python 的 Pandas 处理时间特征,PyTorch 的 LSTM/TFT 捕捉时序趋势,支撑库存、电力等决策场景。
2. 企业落地建议
-
优先用成熟库:CV用
ultralytics(YOLO)、NLP用transformers(BERT)、推荐用pytorch-recommender、时序用pytorch-forecasting,减少重复开发; -
重视工程化:模型训练前做好数据清洗和标注,训练后进行剪枝、量化和分布式部署,确保线上性能;
-
建立监控体系:用 Python 编写监控脚本,实时跟踪模型效果(如准确率、推理速度),避免“模型漂移”导致业务损失;
-
分场景选设备:边缘端(工业质检、车载)用 Jetson + PyTorch ONNX,云端(推荐、大模型)用 GPU 集群 + PyTorch DDP,平衡成本与性能。
Python + PyTorch 的组合,早已不是“科研玩具”,而是企业深度学习落地的“基础设施”。无论是制造业的缺陷检测、金融业的客服意图识别,还是零售业的销量预测,这一组合都能提供从“需求到产品”的全链路解决方案——掌握它,就能在深度学习落地的浪潮中占据主动。
更多推荐
 22
22 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)