
OpenAI | 终极评测:GPT-5对决Claude 4.1,谁才是最强经济价值大模型?
OpenAI团队提出GDPval基准,旨在前瞻性评估AI模型在真实经济任务中的能力。该基准涵盖美国9大GDP贡献行业的44个职业,包含1320个由资深专家设计的真实任务。研究发现,前沿模型(如Claude Opus4.1)在近48%的任务中表现达到或超越人类专家水平,且性能随时间线性提升。研究还验证了增加推理努力、任务上下文和引导能有效提升模型表现。该工作为量化AI的经济价值提供了新框架,并开源了
一、导读
当前,评估AI模型经济影响的方法多为滞后性指标,难以在技术普及前预测其潜力。为解决这一挑战,本文提出了GDPval,一个旨在直接衡量AI模型在真实世界经济价值任务上能力的全新基准(benchmark)。GDPval覆盖了对美国GDP(国内生产总值)贡献最大的9个行业中的44个知识工作类职业,其任务均由平均拥有14年行业经验的专家构建,确保了任务的真实性与代表性。研究发现,前沿模型在GDPval上的性能随时间呈线性增长,其产出质量已接近行业专家水平。本文的核心贡献在于提供了一个现实、广泛且可量化的评估框架,分析了AI与人类专家协同工作时在成本与效率上的潜力,并验证了增加推理(reasoning)努力、任务上下文和引导(scaffolding)能有效提升模型表现。为推动领域发展,论文还开源了一个包含220个任务的黄金子集及一个自动评分服务。
二、论文基本信息

基本信息
-
论文标题:GDPVAL: EVALUATING AI MODEL PERFORMANCE ON REAL-WORLD ECONOMICALLY VALUABLE TASKS
-
作者:Tejal Patwardhan, Rachel Dias, Elizabeth Proehl, Grace Kim, Michele Wang, Olivia Watkins, Simón Posada Fishman, Marwan Aljubeh, Phoebe Thacker, Laurance Fauconnet, Natalie S. Kim, Patrick Chao, Samuel Miserendino, Gildas Chabot, David Li, Michael Sharman, Alexandra Barr, Amelia Glaese, Jerry Tworek
-
作者单位:OpenAI
摘要精炼
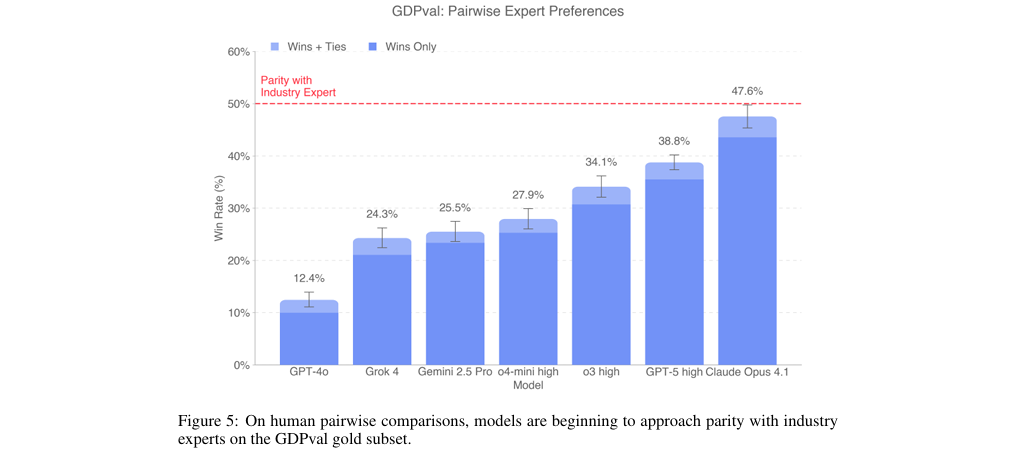
本文的研究目标是创建一个能够衡量AI模型在真实世界经济活动中能力的基准,即GDPval。该基准的核心技术贡献是构建了一个覆盖美国9大GDP贡献行业、44个职业的1,320个真实工作任务的数据集,这些任务均源于资深行业专家的实际工作产品,并经过多轮审核。关键发现表明,当前最前沿的模型(如Claude Opus 4.1)在与人类专家交付成果的成对比较(pairwise comparison)中,有47.6%的情况下被评为“更好”或“同样好”(见图5),显示出其性能正在逼近行业专家水平。此外,研究证实模型性能会随着推理 effort、上下文丰富度和引导的增强而提升。结论指出,将前沿AI模型与人类监督相结合,在执行GDPval任务时具有显著降低成本和缩短时间的潜力。
➔➔➔➔点击查看原文,获取更多大模型相关资料![]() https://mp.weixin.qq.com/s/zv51UTlqL73YSp6ZJ13juw
https://mp.weixin.qq.com/s/zv51UTlqL73YSp6ZJ13juw
三、研究背景与相关工作
研究背景
随着AI技术,特别是大型语言模型的飞速发展,其对劳动力市场的潜在影响已成为社会关注的焦点。然而,当前衡量AI经济影响的方法(如AI采用率、GDP增长贡献等)多为滞后性指标。历史经验表明,从技术发明到其在整个经济体中广泛渗透往往需要数年甚至数十年,期间涉及法规、文化和流程的变革。因此,迫切需要一种能够前瞻性、直接地评估AI模型在经济相关任务上实际能力的方法,以便在技术大规模应用前,更清晰、更可信地评估其经济价值和潜在影响。这便是GDPval研究的出发点和核心动机。
相关工作
现有的AI模型评估基准主要分为两类。第一类是学术测试风格的基准(如MMLU、GPQA),它们侧重于评估模型的推理难度,但与真实工作场景的关联度有限。第二类是专注于特定领域的评估(如软件工程领域的SWE-bench),虽然真实性高,但缺乏跨行业的广泛代表性。同时,一些研究通过分析已有的AI使用模式来推断其经济影响,但这同样属于滞后性分析。GDPval的创新之处在于,它通过自上而下的方法,系统性地覆盖了对经济贡献最大的多个行业和职业,确保了任务的代表性和广度。同时,它强调任务的真实性、多模态、主观性和长周期难度,弥补了现有评估方法的不足。
四、主要贡献与创新
1. 构建了首个大规模、跨行业的经济价值任务基准(GDPval)
GDPval覆盖了美国GDP贡献最高的9个行业中的44个高薪知识工作职业,包含了1,320个基于真实工作产出的任务。这为衡量AI的实际经济能力提供了一个贴近现实且具有广泛代表性的评估平台。
2. 量化了前沿AI模型与行业专家的性能差距
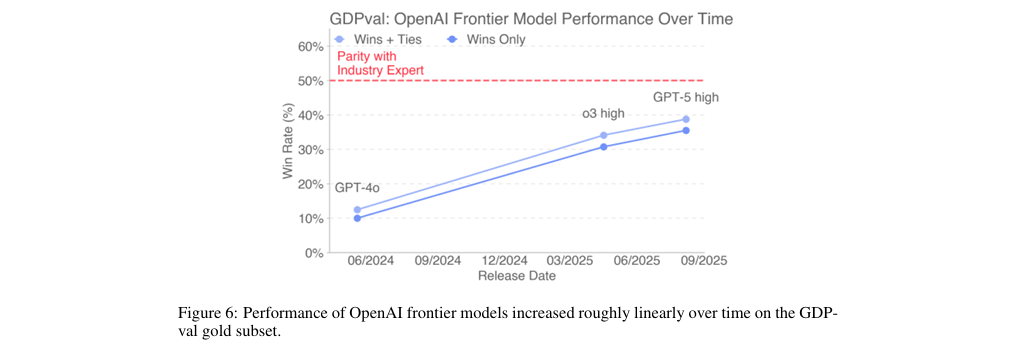
通过严格的专家盲审成对比较,研究表明最先进的模型(如Claude Opus 4.1和GPT-5)在任务完成质量上已接近人类专家水平(见图5),并呈现出随时间线性提升的趋势(见图6)。
3. 分析了AI辅助工作流的潜在经济效益
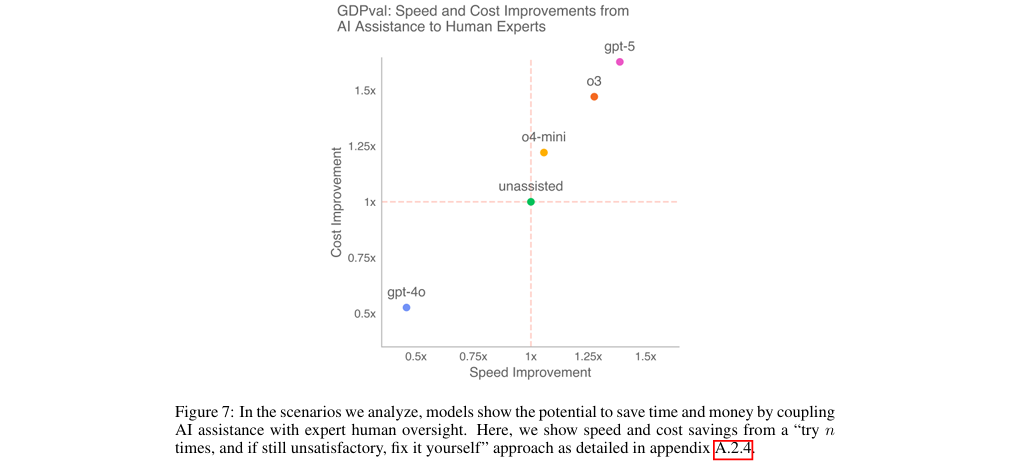
论文设计了多种人机协作场景,并进行了成本与速度分析。结果表明,将AI模型整合到专家工作流程中,即使在模型输出不完美需要返工的情况下,仍有潜力节省大量时间和资金(见图7)。
4. 验证了提升模型性能的有效途径
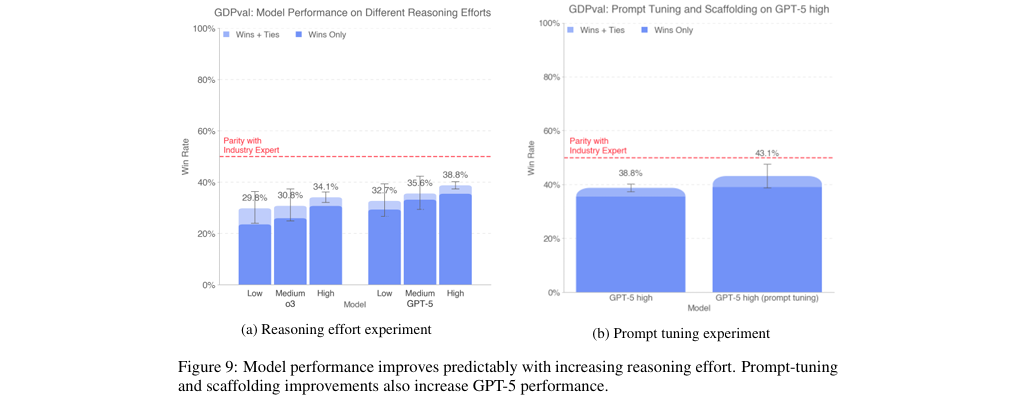
实验证明,通过增加模型的推理努力、提供更丰富的任务上下文以及改进引导(如通过特定指令进行提示调整),可以显著提升模型在复杂经济任务上的表现(见图9b)。
5. 开源了黄金子集和自动评分工具
为促进社区研究,论文开源了包含220个任务的黄金子集及一个实验性的自动评分服务,降低了其他研究者复现和扩展该工作的门槛。
五、研究方法与原理
总体框架与核心思想
本文的核心思想是通过模拟真实世界的经济活动来直接衡量AI的实用价值。其总体框架自上而下地构建了一个评估体系:
-
宏观层面:从美国GDP数据出发,锁定经济贡献最高的9个行业。
-
中观层面:在这些行业中,根据总薪酬和数字化程度,筛选出44个代表性的知识工作职业。
-
微观层面:招募在这些职业中经验丰富的专家(平均14年经验),让他们根据自己的实际工作,创建包含“任务请求”和“交付成果”的真实任务,并确保任务覆盖了O*NET数据库定义的关键工作活动。
-
评估:采用人类专家盲审成对比较作为核心评估方法,直接对比模型和人类专家的交付成果,同时开发实验性的自动评分器作为辅助。 这种“源于真实经济,终于专家评估”的设计哲学,确保了评估结果的现实性和可信度。
关键实现与评估原理
关键实现细节
-
任务质量控制:所有任务都经过一个严格的迭代审核流程,包括AI模型初步筛选和至少三轮、平均五轮的人类专家审核,确保任务的真实性、难度和代表性。
-
专家招募标准:对任务创建和评审的专家有严格要求,包括至少4年专业经验、强大的职业履历、并通过面试、背景调查和能力测试。
-
模型调用设置:在评估不同模型时,为确保公平和发挥模型最大潜力,启用了与任务最相关的功能。例如,为OpenAI模型启用了网页搜索和代码解释器工具,为Claude模型启用了文件创建与分析功能。
核心评估原理与指标
-
核心评估指标:胜率(Win Rate)。这是通过人类专家对模型交付成果与人类专家交付成果进行盲审的成对比较得出的。评审者将结果标记为“模型胜”、“人类胜”或“平局”。胜率是衡量模型性能相对于人类专家基准的核心标准。
-
评估场景与公式:为了评估AI的经济效益,论文设计了“尝试n次,若不满意则自己完成”(try n times, then fix it)的场景。其预期时间成本公式如下,其中
M_T,i是模型完成时间,R_T,i是人工审核时间,H_T,i是人类独立完成时间,w_i是模型在该任务上的胜率。对于尝试n次的情况,预期的任务完成时间
E[T_n,i]为:化简后得到:
成本
E[C_n,i]的计算方式与此类似。这些公式为量化AI的潜在效率提升提供了理论依据。
六、实验结果与分析
实验设置
-
数据集: GDPval黄金子集(220个任务)。
-
评估指标: 人类专家盲审成对比较的胜率(Win Rate vs. 人类专家)。
-
对比基线: 由行业专家(平均14年经验)完成的交付成果。
-
关键模型: GPT-4o, o4-mini, o3, GPT-5, Claude Opus 4.1, Gemini 2.5 Pro, and Grok 4.
核心实验与结论
-
实验目的: 该实验旨在直接比较多个前沿AI模型与行业专家在完成真实经济价值任务时的产出质量。
-
关键结果: 实验结果(见图5)显示,不同模型的性能存在显著差异。表现最好的Claude Opus 4.1,其交付成果在47.6%的情况下被专家评为“优于”或“等同于”人类专家的成果。紧随其后的是GPT-5,胜率(含平局)为39.0%。这表明最顶尖的模型在某些任务上的表现已经可以与经验丰富的人类专家相媲美甚至超越。同时(见图6),OpenAI的前沿模型性能随时间推移(o3 -> GPT-4o -> GPT-5)呈现出大致线性的增长趋势。
-
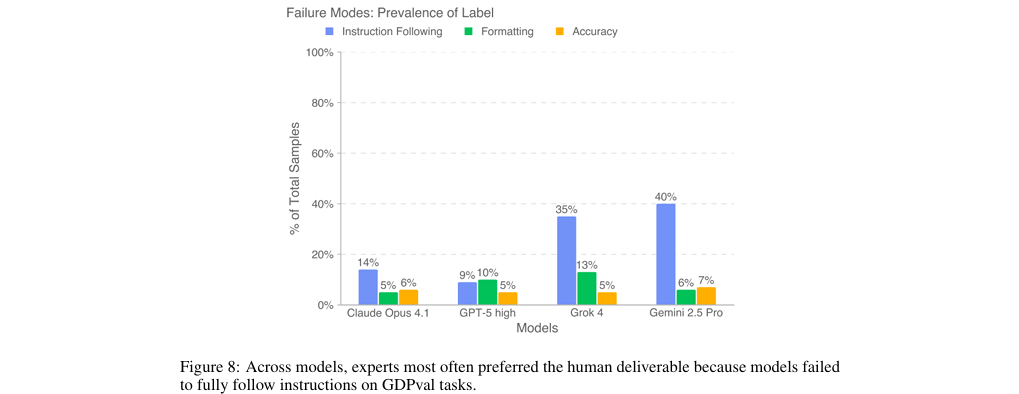
作者结论: 作者得出结论,前沿AI模型的能力正在稳步提升,并已开始在质量上接近行业专家的水平。这预示着AI在辅助甚至自动化复杂知识工作方面具有巨大潜力。模型的具体优劣势有所不同,例如Claude Opus 4.1在美学(如文档格式)上表现更佳,而GPT-5在准确性(如遵循指令)上更具优势(见图8)。
七、论文结论与启示
总结
本文成功构建并验证了一个全新的AI能力评估基准——GDPval,它通过直接衡量模型在真实、高价值经济任务上的表现,为评估AI的社会经济影响提供了前瞻性视角。研究从问题(当前评估方法的滞后性)出发,提出了一个创新的方法(自上而下构建真实世界任务集),并得出了明确的成果:前沿AI模型的性能正快速逼近人类专家水平,且在人机协同工作流中展现出巨大的效率和成本优势。论文通过严谨的实验设计和细致的分析,为理解AI的真实世界能力边界做出了重要贡献。
展望
根据论文的局限性讨论,未来的研究方向可以包括:
-
扩大数据集规模: 增加覆盖的职业和任务数量,构建一个更全面的知识工作评估体系。
-
增强任务复杂性: 引入更多需要隐性知识(tacit knowledge)、团队协作、人际沟通以及使用专有软件的任务,使评估更贴近真实工作环境的复杂性。
-
提升交互性和真实性: 未来版本的GDPval可以设计成交互式任务,要求模型通过多轮对话澄清模糊需求和获取上下文,而不是目前的一次性(one-shot)任务,以此评估模型解决不明确问题的能力。
-
改进自动评分器: 持续优化自动评分模型,使其在评估主观性和多模态输出方面更接近人类专家的水准。
➔➔➔➔点击查看原文,获取更多大模型相关资料![]() https://mp.weixin.qq.com/s/zv51UTlqL73YSp6ZJ13juw
https://mp.weixin.qq.com/s/zv51UTlqL73YSp6ZJ13juw
更多推荐

 22
22 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)