
HuggingFace微调大模型保姆级教程,附过拟合解决思路,建议收藏!
本文介绍了使用HuggingFace Transformers库微调BERT模型处理Yelp评论数据集的完整流程。首先说明了硬件配置(配备NVIDIA H200显卡),然后详细展示了数据下载、预处理(包括文本分词和填充截断策略)以及抽样处理过程。接着讲解了模型训练的超参数配置和评估方法准备,最后提到在双H200显卡上完整数据集微调约需30分钟。该教程为初学者提供了从数据准备到模型训练的端到端指导,
本文详细介绍如何使用HuggingFace的Transformers库对大模型进行微调,解决医学领域特定问题。内容包括硬件需求、数据集下载与预处理、训练参数配置、模型评估和训练流程,展示了从零开始的微调过程
前置硬件需求
有一张显卡即可,若卡能力不足,可适当减小参与训练数据大小。
我们的配置如下:
Mon Sep 1 10:06:29 2025 +-----------------------------------------------------------------------------------------+| NVIDIA-SMI 575.57.08 Driver Version: 575.57.08 CUDA Version: 12.9 ||-----------------------------------------+------------------------+----------------------+| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC || Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. || | | MIG M. ||=========================================+========================+======================|| 0 NVIDIA H200 On | 00000000:8C:00.0 Off | 0 || N/A 32C P0 113W / 700W | 993MiB / 143771MiB | 0% Default || | | Disabled |+-----------------------------------------+------------------------+----------------------+| 1 NVIDIA H200 On | 00000000:A4:00.0 Off | 0 || N/A 33C P0 74W / 700W | 4MiB / 143771MiB | 0% Default || | | Disabled |+-----------------------------------------+------------------------+----------------------+ +-----------------------------------------------------------------------------------------+| Processes: || GPU GI CI PID Type Process name GPU Memory || ID ID Usage ||=========================================================================================|| 0 N/A N/A 1 C /bin/dumb-init 984MiB |+-----------------------------------------------------------------------------------------+
动手实操
下载数据集
初学微调,我们可以使用yelp_review_full数据集做微调,这是一个用户评论数据集,有关于产品的评论以及打星。
from datasets import load_datasetdataset=load_dataset("yelp_review_full")print(dataset)
从此时的输出我们看到我们的数据集的结构,有650000条训练数据,50000条测试数据:
DatasetDict({ train: Dataset({ features: ['label', 'text'], num_rows: 650000 }) test: Dataset({ features: ['label', 'text'], num_rows: 50000 })})
编写函数展示数据,为后面预处理数据做准备。
def show_random_elements(dataset,num_example=2): assert num_example <= len(dataset), "不能取比数据集量还大的数据哦!" picks=[] for _ inrange(num_example): pick = random.randint(0, len(dataset)-1) picks.append(pick) while pick in picks: pick = random.randint(0, len(dataset)-1) picks.append(pick) df=pd.DataFrame(dataset[picks]) for column,typ in dataset.features.items(): if(isinstance(typ,datasets.ClassLabel)): df[column]=df[column].transform(lambda x:typ.names[x]) display(HTML(df.to_html())) show_random_elements(dataset["train"])
我们看到数据如图:

我们可以发现数据长短不一,而且均以文本形式呈现,故我们来对它们进行数据预处理。
数据预处理
我们用Tokenizer来处理文本,将文本转为数字,对于长度不等的输入数据,可使用填充(padding)与截断(truncation)策略来处理。
from transformers import AutoTokenizertokenizer=AutoTokenizer.from_pretrained("bert-base-cased")def tokenize_function(examples): return tokenizer(examples["text"],padding="max_length",truncation=True)tokenized_datasets=dataset.map(tokenize_function,batched=True)
展示处理后数据:
show_random_elements(tokenized_datasets["train"],5)
输出如图:
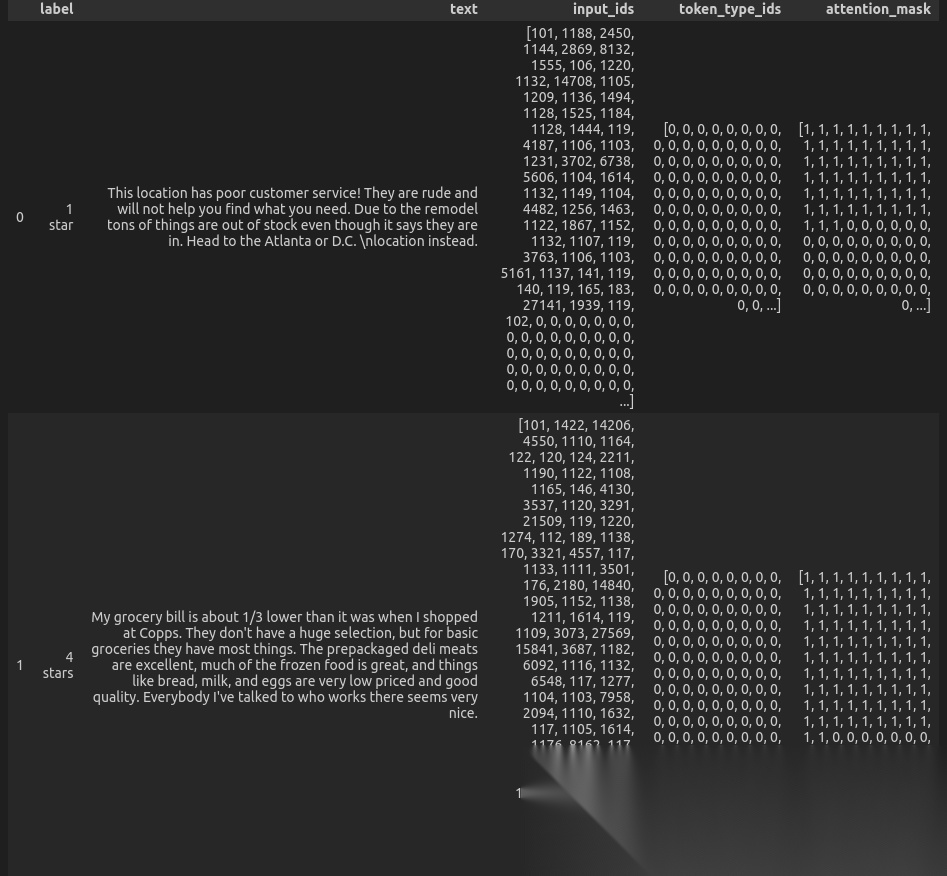
我们可以发现后面为零的部分,其实就是我们填充的部分。
如果显卡资源有限,我们可以进行数据抽样,拿出部分数据即可,做小规模训练。
small_train_dataset=tokenized_datasets["train"].shuffle(seed=42).select(range(10000))small_eval_dataset=tokenized_datasets["test"].shuffle(seed=42).select(range(1000))
当然,我们是跑了全部数据的。在两张H200上,用全部数据微调,需要三十分钟左右。
配置训练超参数
from transformers import AutoModelForSequenceClassificationfrom transformers import TrainingArgumentsmodel=AutoModelForSequenceClassification.from_pretrained("bert-base-cased", num_labels=5)model_dir="models/bert-base-cased-finetune-yelp-all"training_args=TrainingArguments( output_dir=model_dir, per_device_train_batch_size=64, num_train_epochs=3, logging_steps=100)
我们可以print一下当前部分训练超参数配置(篇幅有限,展示部分):
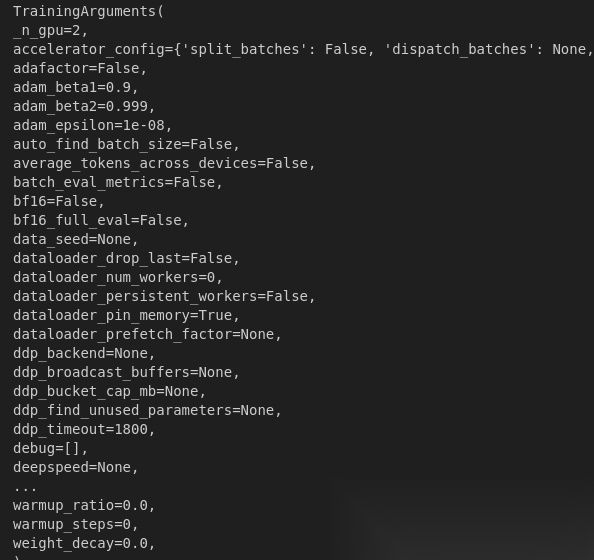
模型评估准备
我们利用evaluate库来进行模型评估。
Hugging Face Evaluate 库 支持使用一行代码,获得数十种不同领域(自然语言处理、计算机视觉、强化学习等)的评估方法。
训练器(Trainer)在训练过程中不会自动评估模型性能。因此,我们需要向训练器传递一个函数来计算和报告指标。
Evaluate库提供了一个简单的准确率函数,我们可以使用evaluate.load函数加载。
import numpy as npimport evaluatemetric=evaluate.load("accuracy")def compute_metrics(eval_pred): logits,labels=eval_pred predictions=np.argmax(logits,axis=-1) return metric.compute(predictions=predictions,references=labels)
训练过程指标监控
为了监控训练过程中的评估指标变化,我们可以在TrainingArguments指定evaluation_strategy参数,以便在 epoch 结束时报告评估指标。
from transformers import TrainingArguments,Trainertraining_args=TrainingArguments( output_dir=model_dir, per_device_train_batch_size=64, num_train_epochs=3, logging_steps=100, eval_strategy="epoch")trainer=Trainer( model=model, args=training_args, train_dataset=small_train_dataset, eval_dataset=small_eval_dataset, compute_metrics=compute_metrics)
万事俱备,只欠训练!
trainer.train()
我们在H200上的过程:
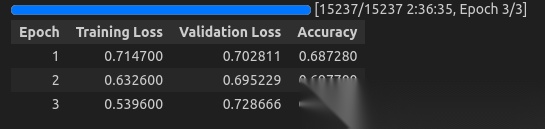
我们跑了3个epoch,可以发现准确度实际上并不是很高,甚至有点过拟合!😭😭😭
训练好后,进行模型测试
small_test_data=tokenized_datasets["test"].shuffle(seed=42).select(range(50000))trainer.evaluate(small_test_data)
输出如图:
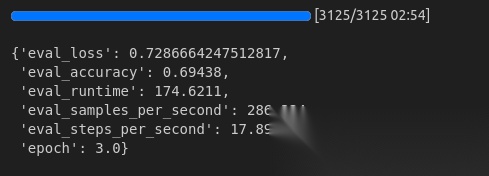
最后,保存模型。
trainer.save_model(model_dir)trainer.save_state()
那么问题来了,这个过拟合,我们有哪些办法解决呢?下面有请我们聪明的读者来思考~
读者福利大放送:如果你对大模型感兴趣,想更加深入的学习大模型**,那么这份精心整理的大模型学习资料,绝对能帮你少走弯路、快速入门**
如果你是零基础小白,别担心——大模型入门真的没那么难,你完全可以学得会!
👉 不用你懂任何算法和数学知识,公式推导、复杂原理这些都不用操心;
👉 也不挑电脑配置,普通家用电脑完全能 hold 住,不用额外花钱升级设备;
👉 更不用你提前学 Python 之类的编程语言,零基础照样能上手。
你要做的特别简单:跟着我的讲解走,照着教程里的步骤一步步操作就行。
包括:大模型学习线路汇总、学习阶段,大模型实战案例,大模型学习视频,人工智能、机器学习、大模型书籍PDF。带你从零基础系统性的学好大模型!
现在这份资料免费分享给大家,有需要的小伙伴,直接VX扫描下方二维码就能领取啦😝↓↓↓
为什么要学习大模型?
数据显示,2023 年我国大模型相关人才缺口已突破百万,这一数字直接暴露了人才培养体系的严重滞后与供给不足。而随着人工智能技术的飞速迭代,产业对专业人才的需求将呈爆发式增长,据预测,到 2025 年这一缺口将急剧扩大至 400 万!!
大模型学习路线汇总
整体的学习路线分成L1到L4四个阶段,一步步带你从入门到进阶,从理论到实战,跟着学习路线一步步打卡,小白也能轻松学会!
大模型实战项目&配套源码
光学理论可不够,这套学习资料还包含了丰富的实战案例,让你在实战中检验成果巩固所学知识
大模型学习必看书籍PDF
我精选了一系列大模型技术的书籍和学习文档(电子版),它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。
大模型超全面试题汇总
在面试过程中可能遇到的问题,我都给大家汇总好了,能让你们在面试中游刃有余
这些资料真的有用吗?
这份资料由我和鲁为民博士(北京清华大学学士和美国加州理工学院博士)共同整理,现任上海殷泊信息科技CEO,其创立的MoPaaS云平台获Forrester全球’强劲表现者’认证,服务航天科工、国家电网等1000+企业,以第一作者在IEEE Transactions发表论文50+篇,获NASA JPL火星探测系统强化学习专利等35项中美专利。本套AI大模型课程由清华大学-加州理工双料博士、吴文俊人工智能奖得主鲁为民教授领衔研发。
资料内容涵盖了从入门到进阶的各类视频教程和实战项目,无论你是小白还是有些技术基础的技术人员,这份资料都绝对能帮助你提升薪资待遇,转行大模型岗位。
👉获取方式:
😝有需要的小伙伴,可以保存图片到VX扫描下方二维码免费领取【保证100%免费】
相信我,这套大模型系统教程将会是全网最齐全 最适合零基础的!!
更多推荐

 11
11 0
0- 0



 已为社区贡献59条内容
已为社区贡献59条内容

所有评论(0)